曾经参与过系统维护或是在现有系统中进行迭代开发的软件工程师们,你们是否有过这样的痛苦经历:当需要修改一个Bug的时候,面对一个类中成百上千行的代码,没有注释,千奇百怪的方法和变量名字,层层嵌套的方法调用,混乱不堪的结构,不要说准确找到Bug所在的位置,就是要清晰知道一段代码究竟是做了什么也非常困难。最终,改对了一个Bug,却多冒出N个新Bug。同样的情况,当你拿到一份新的需求,需要在现有系统中添加功能的时候,面对一行行完全过程式的代码,需要使用一个功能时,不知道是应该自己编写,还是应该寻找是否已经存在的方法,编写一个非常简单的新、删、改功能,却要费尽九牛二虎之力。最终发现,系统存在着太多的重复逻辑,阅读、测试、修改非常困难。在经历了这些痛苦之后,你们是否会不约而同的发出一个感慨:与其进行系统维护和迭代开发,还不如重新设计开发一个新的系统来得痛快?
面对这一系列让软件陷入无底泥潭的问题,基于面向对象思想的领域驱动设计方法是一个很好的解决方法。从事过系统设计的富有经验的设计师们,对职责单一原则、信息专家、充血/贫血模型、模型驱动设计这些名词或概念应该不会感到陌生。面向对象的设计大师Martin Fowler不止一次的在他的Blog和著作《企业应用架构模式》中倡导过上述概念在设计中的巨大威力,而另外一位领域模型的出色专家Eric Evans的著作《领域驱动设计》也为我们提供了不少宝贵的经验和方法。
笔者从事系统设计多年,将会在本系列文章中把本人对领域驱动设计的理解,结合工作过程中积累的实际项目经验进行浅析,希望与大家交流学习。
在本系列博文的开篇中,我将会拿出一个例子,先用传统的面向过程方式,使用贫血模型进行设计,然后再逐步加入需求变更。让读者发现,随着系统的不断变更,基于贫血模型的设计将会让系统慢慢陷入泥潭,越来越难于维护。然后再用基于面向对象的领域驱动设计重新上述过程,通过对比展示领域驱动设计对于复杂的业务系统的威力。
假设现在有一个银行支付系统项目,其中的一个重要的业务用例是账户转账业务。系统使用迭代的方式进行开发,在1.0版本中,该用例的功能需求非常简单,事件流描述如下:
主事件流:
1)用户登录银行的在线支付系统
2)选择用户在该银行注册的网上银行账户
3)选择需要转账的目标账户,输入转账金额,申请转账
4)银行系统检查转出账户的金额是否足够
5)从转出账户中扣除转出金额(debit),更新转出账户的余额
6)把转出金额加入到转入账户中(credit),更新转入账户的余额
备选事件流:
4a)如果转出账户中的余额不足,转账失败,返回错误信息
面向过程的设计方式(贫血模型)
设计方案如下(忽略展示层部分):
1)设计一个账户交易服务接口AccountingService,设计一个服务方法transfer(),并提供一个具体实现类AccountingServiceImpl,所有账户交易业务的业务逻辑都置于该服务类中。
2)提供一个AccountInfo和一个Account,前者是一个用于与展示层交换账户数据的账户数据传输对象,后者是一个账户实体(相当于一个EntityBean),这两个对象都是普通的JavaBean,具有相关属性和简单的get/set方法。
下面是AccountingServiceImpl.transfer()方法的实现逻辑(伪代码):
public class AccountingServiceImpl implements AccountingService {
public void transfer(Long srcAccountId, Long destAccountId, BigDecimal amount) throws AccountingServiceException {
Account srcAccount = accountRepository.getAccount(srcAccountId);
Account destAccount = accountRepository.getAccount(destAccountId);
if(srcAccount.getBalance().compareTo(amount)<0){
throw new AccountingServiceException(AccountingService.BALANCE_IS_NOT_ENOUGH);
}
srcAccount.setBalance(srcAccount.getBalance().sbustract(amount));
destAccount.setBalance(destAccount.getBalance().add(amount));
}
}
public class Account implements DomainObject {
private Long id;
private Bigdecimal balance;
/**
* getter/setter
*/
}
可以看到,由于1.0版本的功能需求非常简单,按面向过程的设计方式,把所有业务代码置于AccountingServiceImpl中完全没有问题。
这时候,新需求来了,在1.0.1版本中,需要为账户转账业务增加如下功能,在转账时,首先需要判断账户是否可用,然后,账户的余额还要分成两部分:冻结部分和活跃部分,处于冻结部分的金额不能用于任何交易业务,我们来看看变更后的代码:
public class AccountingServiceImpl implements AccountingService {
public void transfer(Long srcAccountId,Long destAccountId,BigDecimal amount) throws AccountingServiceException {
Account srcAccount = accountRepository.getAccount(srcAccountId);
Account destAccount = accountRepository.getAccount(destAccountId);
if(!srcAccount.isActive() || !destAccount.isActive())
throw new AccountingServiceException(AccountingService.ACCOUNT_IS_NOT_AVAILABLE);
BigDecimal availableAmount = srcAccount.getBalance().substract(srcAccount.getFrozenAmount());
if(availableAmount.compareTo(amount)<0)
throw new AccountingServiceException(AccountingService.BALANCE_IS_NOT_ENOUGH);
srcAccount.setBalance(srcAccount.getBalance().sbustract(amount));
destAccount.setBalance(destAccount.getBalance().add(amount));
}
}
public class Account implements DomainObject {
private Long id;
private BigDecimal balance;
private BigDecimal frozenAmount;
/**
* getter/setter
*/
}
可以看到,情况变得稍微复杂了,这时候,1.0.2的需求又来了,需要在每次交易成功后,创建一个交易明细账,于是,我们又必须在transfer()方面里面增加创建并持久化交易明细账的业务逻辑:
AccountTransactionDetails details= new AccountTransactionDetails(…);
accountRepository.save(details);
业务需求不断复杂化:账户每笔转账的最大额度需要由其信用指数确定、需要根据银行的手续费策略计算并扣除一定的手续费用……,随着业务的复杂化,transfer()方法的逻辑变得越来越复杂,逐渐形成了上文所述的成百上千行代码。有经验的程序员可能会做出类此“方法抽取”的重构,把转账业务按逻辑划分成若干块:判断余额是否足够、判断账户的信用指数以确定每笔最大转账金额、根据银行的手续费策略计算手续费、记录交易明细账……,从而使代码更加结构化。这是一个好的开始,但还是显然不足。
假设某一天,系统需求增加一个新的模块,为系统增加一个网上商城,让银行用户可以进行在线购物,而在线购物也存在着很多与账户贷记借记业务相同或相似的业务逻辑:判断余额是否足够、对账户进行借贷操作(credit/debit)以改变余额、收取手续费用、产生交易明细账……
面对这种情况,有两种解决办法:
1) 把AccountingServiceImpl中的相同逻辑拷贝到OnlineShoppingServiceImplementation中
2) 让OnlineShoppingServiceImpl调用AccountingServiceImpl的相同服务
显然,第二种方法比第一种方法更好,结构更清晰,维护更容易。但问题在于,这样就会形成网上商城服务模块与账户收支服务模块的不必要的依赖关系,系统的耦合度高了,如果系统为了更灵活的伸缩性,让每个大业务模块独立进行部署,还需要因为两者的依赖关系建立分布式调用,这无疑增加了设计、开发和运维的成本。
有经验的设计人员可能会发现第三种解决办法:把相同的业务逻辑抽取成一个新的服务,作为公共服务同时供上述两个业务模块使用。这就是笔者将会马上讨论的方案——使用领域驱动设计。
面向对象的领域驱动设计方式(充血模型)
为了节省篇幅,这里就直接以最复杂的业务需求来进行设计。
领域驱动设计的一个重要的概念是领域模型,首先,我们根据业务领域抽象出以下核心业务对象模型:
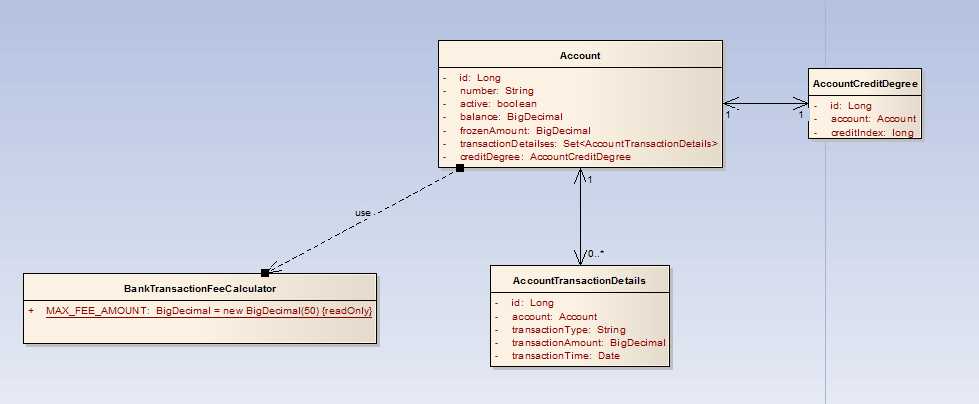
Account:账户,是整个系统的最核心的业务对象,它包括以下属性:对象标识、账户号、是否有效标识、余额、冻结金额、账户交易明细集合、账户信用等级。
AccountTransactionDetails:账户交易明细,它从属于账户,每个账户有多个交易明细,它包括以下属性:对象标识、所属账户、交易类型、交易发生金额、交易发生时间。
AccountCreditDegree:账户信用等级,它用于限制账户的每笔交易发生金额,包含以下属性:对象标识、对应账户、信用指数。
BankTransactionFeeCalculator:银行交易手续费用计算器,它包含一个常量:每笔交易的手续费上限。
我们知道,领域对象除了具有自身的属性和状态之外,它的一个很重要的标志是,它具有属于自己职责范围之内的行为,这些行为封装了其领域内的领域业务逻辑。于是,我们进行进一步的建模,根据业务需求为领域对象设计业务方法:
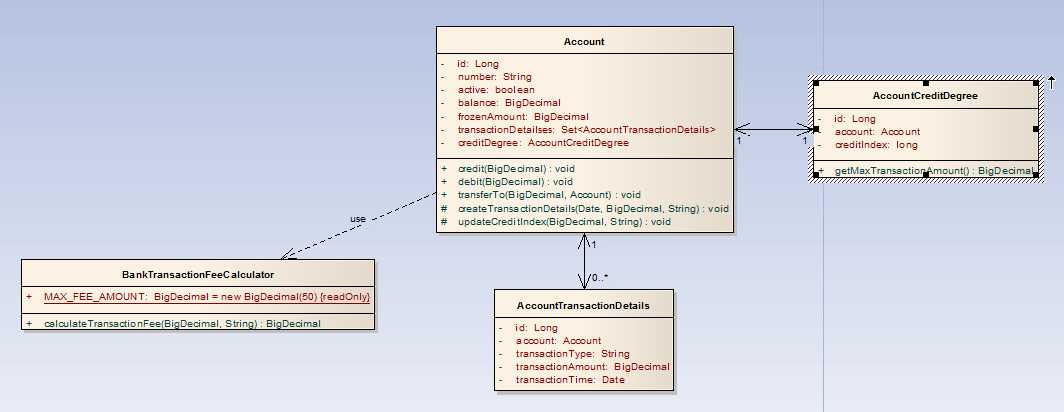
根据职责单一的原则,我们把功能需求中描述的功能合理的分配到不同的领域对象中:
Account:
(我们可以看到,后两个业务方法被声明为protected,具体原因见后述)
AccountCreditDegree:
BankTransactionFeeCalculator:
经过这样的设计,前例中所有放置在服务对象的业务逻辑被分别划入不同的负责相关职责的领域对象当中,下面的时序图描述了AccountingServiceImpl的转账业务的实现逻辑(为了简化逻辑,我们忽略掉事物、持久化等逻辑):

再看看AccountingServiceImpl.transfer()的实现逻辑:
public class AccountingServiceImpl implements AccountingService {
public void transfer(Long srcAccountId,Long destAccountId,BigDecimal amount) throws AccountDomainException {
Account srcAccount = accountRepository.getAccount(srcAccountId);
Account destAccount = accountRepository.getAccount(destAccountId);
srcAccount.transferTo(destAccount,amount);
}
}
我们可以看到,上例那些复杂的业务逻辑:判断余额是否足够、判断账户是否可用、改变账户余额、计算手续费、判断交易额度、产生交易明细账……,都不再存在于AccountingServiceImplementation的transfer方法中,它们被委派给负责这些业务的领域对象的业务方法中去,现在应该猜到为什么Account中有两个方法被声明为protected了吧,因为他们是在debit和credit方法被调用时,由这两个方法调用的,对于AccountingServiceImpl来说,由于产生交易明细(createTransactionDetails)和更新账户信用指数(updateCreditIndex)都不属于其职责范围,它不需要也无权使用这些逻辑。
我们可以看到,使用领域驱动设计至少会带来下述优点:
再看看如果这时需要加入网上商城的一个新的模块,开发人员需要怎么去做,还记得上面提过的第三种方案吗?就是把账户贷记和借记的相关业务抽取到成一个公共服务,同时供银行在线支付系统和网上商城系统服务,其实这个公共的服务,本质上就是这些具有领域逻辑的领域对象:Account、AccountCreditDegree……,由此我们又可以发现领域驱动设计的一大优点:
笔者经验尚浅,而且文笔拙劣,希望通过这样的一个场景的分析比较,能让读者初步认识到基于面向对象的领域驱动设计的威力,并在实际项目中尝试应用。本篇是领取驱动设计系列博文的第一篇,在系列文章的第二篇博文中,笔者将会浅析VO、DTO、DO、PO的概念、用处和区别,敬请各位对本系列博文感兴趣的读者关注并给予指导修正。
http://kb.cnblogs.com/page/522125/
上一篇文章作为一个引子,说明了领域驱动设计的优势,从本篇文章开始,笔者将会结合自己的实际经验,谈及领域驱动设计的应用。本篇文章主要讨论一下我们经常会用到的一些对象:VO、DTO、DO和PO。
由于不同的项目和开发人员有不同的命名习惯,这里我首先对上述的概念进行一个简单描述,名字只是个标识,我们重点关注其概念:
概念:
VO(View Object):视图对象,用于展示层,它的作用是把某个指定页面(或组件)的所有数据封装起来。
DTO(Data Transfer Object):数据传输对象,这个概念来源于J2EE的设计模式,原来的目的是为了EJB的分布式应用提供粗粒度的数据实体,以减少分布式调用的次数,从而提高分布式调用的性能和降低网络负载,但在这里,我泛指用于展示层与服务层之间的数据传输对象。
DO(Domain Object):领域对象,就是从现实世界中抽象出来的有形或无形的业务实体。
PO(Persistent Object):持久化对象,它跟持久层(通常是关系型数据库)的数据结构形成一一对应的映射关系,如果持久层是关系型数据库,那么,数据表中的每个字段(或若干个)就对应PO的一个(或若干个)属性。
模型:
下面以一个时序图建立简单模型来描述上述对象在三层架构应用中的位置:
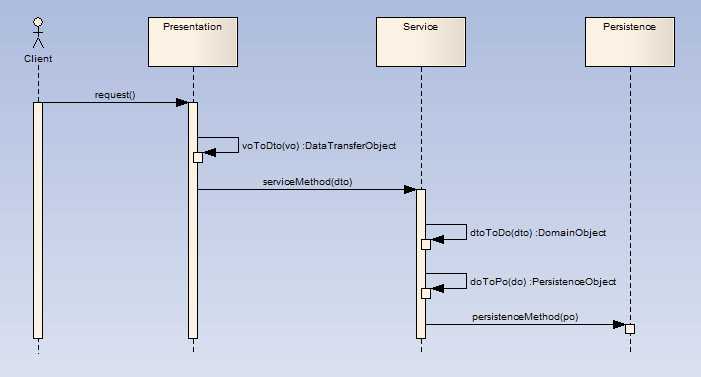
VO与DTO的区别
大家可能会有个疑问(在笔者参与的项目中,很多程序员也有相同的疑惑):既然DTO是展示层与服务层之间传递数据的对象,为什么还需要一个VO呢?对!对于绝大部分的应用场景来说,DTO和VO的属性值基本是一致的,而且他们通常都是POJO,因此没必要多此一举。但不要忘记这是实现层面的思维,对于设计层面来说,概念上还是应该存在VO和DTO,因为两者有着本质的区别,DTO代表服务层需要接收的数据和返回的数据,而VO代表展示层需要显示的数据。
用一个例子来说明可能会比较容易理解:例如服务层有一个getUser的方法返回一个系统用户,其中有一个属性是gender(性别),对于服务层来说,它只从语义上定义:1-男性,2-女性,0-未指定,而对于展示层来说,它可能需要用“帅哥”代表男性,用“美女”代表女性,用“秘密”代表未指定。说到这里,可能你还会反驳,在服务层直接就返回“帅哥美女”不就行了吗?对于大部分应用来说,这不是问题,但设想一下,如果需求允许客户可以定制风格,而不同风格对于“性别”的表现方式不一样,又或者这个服务同时供多个客户端使用(不同门户),而不同的客户端对于表现层的要求有所不同,那么,问题就来了。再者,回到设计层面上分析,从职责单一原则来看,服务层只负责业务,与具体的表现形式无关,因此,它返回的DTO,不应该出现与表现形式的耦合。
理论归理论,这到底还是分析设计层面的思维,是否在实现层面必须这样做呢?一刀切的做法往往会得不偿失,下面我马上会分析应用中如何做出正确的选择。
VO与DTO的应用
上面只是用了一个简单的例子来说明VO与DTO在概念上的区别,本节将会告诉你如何在应用中做出正确的选择。
在以下才场景中,我们可以考虑把VO与DTO二合为一(注意:是实现层面):
以下场景需要优先考虑VO、DTO并存:
DTO与DO的区别
首先是概念上的区别,DTO是展示层和服务层之间的数据传输对象(可以认为是两者之间的协议),而DO是对现实世界各种业务角色的抽象,这就引出了两者在数据上的区别,例如UserInfo和User(对于DTO和DO的命名规则,请参见笔者前面的一篇博文),对于一个getUser方法来说,本质上它永远不应该返回用户的密码,因此UserInfo至少比User少一个password的数据。而在领域驱动设计中,正如第一篇系列文章所说,DO不是简单的POJO,它具有领域业务逻辑。
DTO与DO的应用
从上一节的例子中,细心的读者可能会发现问题:既然getUser方法返回的UserInfo不应该包含password,那么就不应该存在password这个属性定义,但如果同时有一个createUser的方法,传入的UserInfo需要包含用户的password,怎么办?在设计层面,展示层向服务层传递的DTO与服务层返回给展示层的DTO在概念上是不同的,但在实现层面,我们通常很少会这样做(定义两个UserInfo,甚至更多),因为这样做并不见得很明智,我们完全可以设计一个完全兼容的DTO,在服务层接收数据的时候,不该由展示层设置的属性(如订单的总价应该由其单价、数量、折扣等决定),无论展示层是否设置,服务层都一概忽略,而在服务层返回数据时,不该返回的数据(如用户密码),就不设置对应的属性。
对于DO来说,还有一点需要说明:为什么不在服务层中直接返回DO呢?这样可以省去DTO的编码和转换工作,原因如下:
对于DTO来说,也有一点必须进行说明,就是DTO应该是一个“扁平的二维对象”,举个例子来说明:如果User会关联若干个其他实体(例如Address、Account、Region等),那么getUser()返回的UserInfo,是否就需要把其关联的对象的DTO都一并返回呢?如果这样的话,必然导致数据传输量的大增,对于分布式应用来说,由于涉及数据在网络上的传输、序列化和反序列化,这种设计更不可接受。如果getUser除了要返回User的基本信息外,还需要返回一个AccountId、AccountName、RegionId、RegionName,那么,请把这些属性定义到UserInfo中,把一个“立体”的对象树“压扁”成一个“扁平的二维对象”。笔者目前参与的项目是一个分布式系统,该系统不管三七二十一,把一个对象的所有关联对象都转换为相同结构的DTO对象树并返回,导致性能非常的慢。
DO与PO的区别
DO和PO在绝大部分情况下是一一对应的,PO是只含有get/set方法的POJO,但某些场景还是能反映出两者在概念上存在本质的区别:
DO与PO的应用
由于ORM框架的功能非常强大而大行其道,而且JavaEE也推出了JPA规范,现在的业务应用开发,基本上不需要区分DO与PO,PO完全可以通过JPA,Hibernate Annotations/hbm隐藏在DO之中。虽然如此,但有些问题我们还必须注意:
到目前为止,相信大家都已经比较清晰的了解VO、DTO、DO、PO的概念、区别和实际应用了。通过上面的详细分析,我们还可以总结出一个原则:分析设计层面和实现层面完全是两个独立的层面,即使实现层面通过某种技术手段可以把两个完全独立的概念合二为一,在分析设计层面,我们仍然(至少在头脑中)需要把概念上独立的东西清晰的区分开来,这个原则对于做好分析设计非常重要(工具越先进,往往会让我们越麻木)。第一篇系列博文抛砖引玉,大唱领域驱动设计的优势,但其实领域驱动设计在现实环境中还是有种种的限制,需要选择性的使用,正如我在《田七的智慧》博文中提到,我们不能永远的理想化的去选择所谓“最好的设计”,在必要的情况下,我们还是要敢于放弃,因为最合适的设计才是最好的设计。本来,系列中的第二篇博文应该是讨论领取驱动设计的限制和如何选择性的使用,但请原谅我的疏忽,下一篇系列博文会把这个主题补上,敬请关注。
http://kb.cnblogs.com/page/522348/
本系列的第一篇博文抛砖引玉,大谈领域驱动设计的优势,这里笔者还是希望以客观的态度,谈谈领域驱动设计的缺点及其不适合使用的场景,以让读者可以有选择性的使用领域驱动设计。
我们知道,没有最好,只有最合适,设计也是一样。因此,所谓设计,就是以你和你的团队的知识、经验和智慧,全面充分的考虑各种内外因素后,在你们的设计方案中作出合理的选择的过程。而这些影响你们选择的因素主要有:
当然,上述的考虑因素站在比较高的角度,通常是项目经理、架构师需要考虑的问题,但这当中你应该会得到一些启发。回到我们的主题,我们首先看看,领域驱动设计相对于传统的面向过程式的设计,有什么缺点:

系统的初始阶段,领域驱动设计需要付出更大的成本,但随着时间的推移,领域驱动设计的成本效益优势会逐步显现
那么,假设我们在时间、团队能力及各种资源都允许的情况下,是否就可以麻木的全盘使用领域驱动设计呢?正如本博文的标题一样,答案是否定的,我们需要有选择性的使用。让我们来看看一些指导性原则:
本博文给有志于领域驱动设计的读者泼了一下冷水,提出一些“反模式”(Bitter),是为了让读者冷静一下,在领域驱动设计过程中作出更灵活和更合理的选择。关于这方面的论述,笔者在这里浅尝则止,限于水平、经验和表达能力,不敢胡乱卖弄,建议读者可以参考阅读Martin Fowler的《Patterns of Enterprise Application Architecture》一书的相关观点。
http://kb.cnblogs.com/page/521969/
领域驱动设计系列(转)






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
