作者:阿思翠 | 来源:互联网 | 2022-12-06 18:22
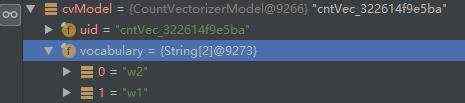
我正在尝试在具有约15.000.000唯一字符串值的列上使用Spark的StringIndexer功能转换器。无论我投入多少资源,Spark都会因内存不足异常而死在我身上。
from pyspark.ml.feature import StringIndexer
data = spark.read.parquet("s3://example/data-raw").select("user", "count")
user_indexer = StringIndexer(inputCol="user", outputCol="user_idx")
indexer_model = user_indexer.fit(data) # This never finishes
indexer_model \
.transform(data) \
.write.parquet("s3://example/data-indexed")
驱动程序上会生成一个错误文件,其开头如下所示:
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 268435456 bytes for committing reserved memory.
# Possible reasons:
# The system is out of physical RAM or swap space
# In 32 bit mode, the process size limit was hit
# Possible solutions:
# Reduce memory load on the system
# Increase physical memory or swap space
# Check if swap backing store is full
# Use 64 bit Java on a 64 bit OS
# Decrease Java heap size (-Xmx/-Xms)
# Decrease number of Java threads
# Decrease Java thread stack sizes (-Xss)
# Set larger code cache with -XX:ReservedCodeCacheSize=
# This output file may be truncated or incomplete.
#
# Out of Memory Error (os_linux.cpp:2657)
现在,如果我尝试手动索引值并将它们存储在数据框中,则一切工作都像魅力一样,都在几个Amazon c3.2xlarge工作人员上进行。
from pyspark.sql.functions import row_number
from pyspark.sql.window import Window
data = spark.read.parquet("s3://example/data-raw").select("user", "count")
uid_map = data \
.select("user") \
.distinct() \
.select("user", row_number().over(Window.orderBy("user")).alias("user_idx"))
data.join(uid_map, "user", "inner").write.parquet("s3://example/data-indexed")
我真的很想使用Spark提供的正式转换器,但是目前看来这是不可能的。关于如何进行这项工作的任何想法?








 京公网安备 11010802041100号
京公网安备 11010802041100号