前言:
模型作用为提取三元组,基于英文,目前尝试改为中文。
论文题目名称叫《Open Language Learning for Information Extraction》,代码地址: https://github.com/knowitall/...
论文核心:
论文核心主要解决2个问题,一个是基于动词结构之外的三元组提取,例如形容词等,二是基于上下文的三元组提取,举例说明。这里论文与reverb和woe两种抽取方式做比较。

在1-3句话中,基于reverb和woe的提取为none,即什么也提取不到。但基于ollie,其可以提取到,也就是解决了reverb和woe的第一个缺点。
举例说明一下:例如第一句Saint 赢了超级杯后,就成了美国橄榄球联盟的顶级球员。 这句话里没有动词,所以reverb和woe什么都提取不到。
在4-5句中,ollie是基于上下文的抽取,所以reverb和woe的抽取只能抽到地球是宇宙的中心,但无法抽到eraly astronmers,而ollie能够抽到attributedto。
举例:在很早以前人们认为地球是宇宙的中心,reverb和woe提取的是地球是宇宙中心,这显然不对。而ollie可以提取到AttributedTo相信;早期的天文学家。
以上两点取自论文Introduction。
如何做的:
1.扩展关系短语的句法范围,以涵盖更多的关系表达式。
2.扩大开放即表示允许额外的上下文信息,如归因和子句的修饰符
具体做法:
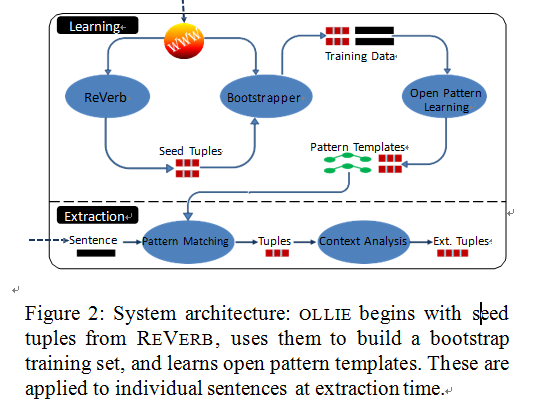
(1)构造一个引导集










![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)

 京公网安备 11010802041100号
京公网安备 11010802041100号