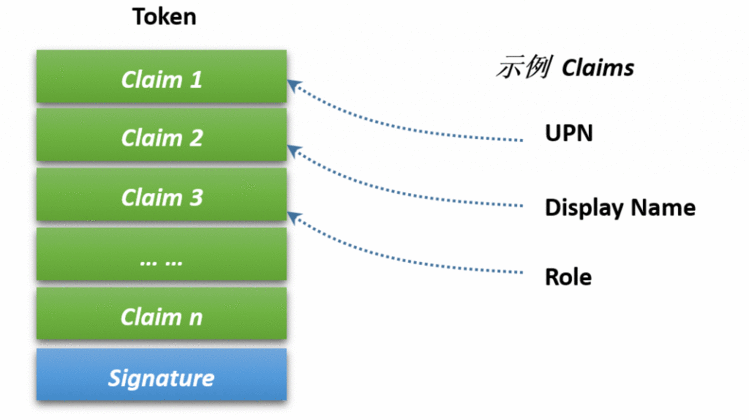
请求头Request Headers: Accept:请求报头域,用于客户端可接受哪些类型的信息。 Accept-Language:指定客户端可接受的语言类型。 Accept-Encoding:指定客户端可接受的内容编码。 Host:用于指定请求资源的主机 IP 和端口号,其内容为请求 URL 的原始服务器或网关的位置。 COOKIE:也常用复数形式 COOKIEs ,这是网站为了辨别用户进行会话跟踪而存储在用户本地的数据,它的主要功能是维持当前访问会话,例如登陆以后再次打开还是登陆状态。 Referer :此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,如做来源统计、防盗链处理等。 User-Agent:UA ,一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本,浏览器及版本等信息,在做爬虫时加上此信息,可以伪装为浏览器;如果不加,很可能会被识别出为爬虫。 Content-Type:也叫互联网媒体类型( Internet Media Type )或者 MIME 类型,在 HTT 协议消息头中,它用来表示具体请求中的媒体类型信息。 在爬虫中,如果要构造 POST 请求,需要使用正确的 Content-Type。
 第一列Name:请求的名称,一般会将RL最后一部分内容当作名称。
第一列Name:请求的名称,一般会将RL最后一部分内容当作名称。










 京公网安备 11010802041100号
京公网安备 11010802041100号