该内容面向SVM支持分类的学习,纯属个人见解,内容并不是完全靠谱,仅供参考
一.Svm.svc()
SVC是SVM的一种Type,是用来支持向量分类
SVR是svm的令一种tyep,是用来支持向量回归
SVM模型有两个非常重要的参数C与gamma。
C
其中 C是惩罚系数,即对误差的宽容度。,过大过小都不好,适中最好,所以这里涉及到了调参的工作
c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差 仅作了解
Gamma
支持向量的分布,一般来说gamma太小,欠拟合,太大,过拟合,适中,最好。
gamma是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,而如果设的过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率。
二.平滑滤波:
通过平滑滤波来损坏边缘的特征信息。类似与超清,高清,标清的区别
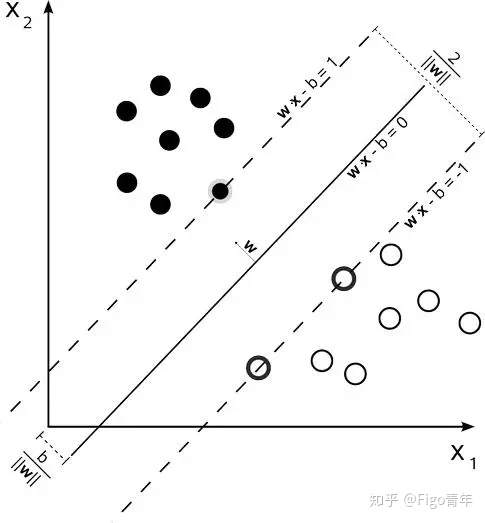
三.核函数: 仅作了解
把点弄成线,把线弄成体,把体弄成高维空间 ,这就是高斯核函数做的事情

作用:将低维空间线性不可分割任务交给核函数,核函数通过高维的映射将线性不可分割的两类点变成线性可分割。再将高维中的判决边界,再映射回低维空间
四.Fit: 拟合
拟合就是把平面上一系列的点,用一条光滑的曲线连接起来。
因为这条曲线有无数种可能,从而有各种拟合方法。拟合的曲线一般可以用函数表示,根据这个函数的不同有不同的拟合名字。 仅作了解
过拟合,这条坐标上的所有特征信息都连起来。
做的题少 考试50分
欠拟合,这条坐标上上的特征信息有许多没有连起来。
做的题太多,太相似 考试70分
拟合,就是过拟合与欠拟合之间最适中的一个平滑的曲线。
做的题不多不少,什么种类的题都会做一点,考试90分
五.线性回归,线性拟合
线性回归是外国人的术语,线性拟合是中国人的术语,两者本质上可以等同
两者的含义本质上都是为了说明通过该方法在二维空间中找到一条连接这些特征信息点的
看不见的线。
说的在通俗一点,就是将这些点拟合成一条线,或是点一点点的回归成一条线。
六.非线性回归,非线性拟合
线性是指一条平滑的直线
二元一次方程在坐标系上所显示的出来的结果就是线性的成正比关系是线性
非线性就是指一条曲线
非二元一次方程在坐标系上所显示的出来的结果就是非线性的 成反比关系是非线性

线性 非线性 非线性
线性函数关系是直线,而非线性函数关系是非直线,包括各种曲线、折线、不连续的线等;
七.Clf.fit:
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) #数据特征
>>> y = np.array([1, 1, 2, 2]) # 数据对应的标签
>>> from sklearn.svm import SVC # 导入svm的svc类(支持向量分类)
>>> clf = SVC() # 创建分类器对象
>>> clf.fit(X, y) # 用训练数据拟合分类器模型
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> clf.predict([[-0.8, -1]]) # 用训练好的分类器去预测[-0.8, -1]数据的标签
[1]
八.Joblib
做模型训练时,需要将模型保存下来,然后放到独立的测试集上测试,下面介绍的是Python中训练模型的保存和再使用。
在机器学习过程中,一般用来训练模型的过程比较长,所以我们一般会将训练的模型进行保存(持久化),然后进行评估,预测等等,这样便可以节省大量的时间。
1. joblib.dump(clf,'../../data/model/randomforest.pkl',compress=3)
2. #load model to clf
3. clf = joblib.load('../../data/model/randomforest.pkl')
Compress=3: 压缩=3
压缩:整数为0到9,可选
数据的可选压缩级别。0是没有压缩。
高意味着更多的压缩,但也慢读和
写的时候。使用3的值通常是一个很好的折衷方案。
详情请看说明。
压缩的意义:减少空间占用









 京公网安备 11010802041100号
京公网安备 11010802041100号