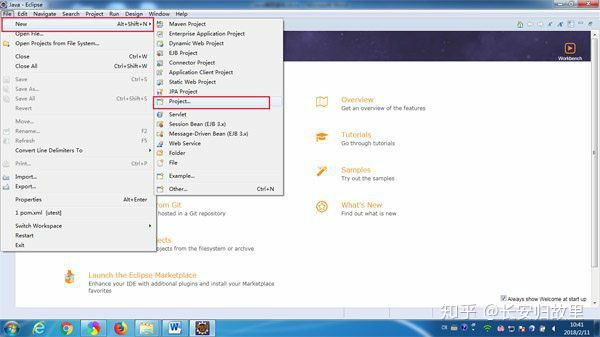
以下Java程序平均需要在0.50到0.55之间运行:
public static void main(String[] args) {
long startTime = System.nanoTime();
int n = 0;
for (int i = 0; i <1000000000; i++) {
n += 2 * (i * i);
}
System.out.println((double) (System.nanoTime() - startTime) / 1000000000 + " s");
System.out.println("n = " + n);
}
如果我更换2 * (i * i)用2 * i * i,它需要0.60〜0.65s之间运行.怎么会?
我运行了每个版本的程序15次,在两者之间交替.结果如下:
2*(i*i) | 2*i*i ----------+---------- 0.5183738 | 0.6246434 0.5298337 | 0.6049722 0.5308647 | 0.6603363 0.5133458 | 0.6243328 0.5003011 | 0.6541802 0.5366181 | 0.6312638 0.515149 | 0.6241105 0.5237389 | 0.627815 0.5249942 | 0.6114252 0.5641624 | 0.6781033 0.538412 | 0.6393969 0.5466744 | 0.6608845 0.531159 | 0.6201077 0.5048032 | 0.6511559 0.5232789 | 0.6544526
最快的运行2 * i * i时间比最慢的运行时间长2 * (i * i).如果它们同样有效,则发生这种情况的概率将小于1/2 ^ 15 = 0.00305%.
字节码的顺序略有不同.
2 * (i * i):
iconst_2
iload0
iload0
imul
imul
iadd
vs 2 * i * i:
iconst_2
iload0
imul
iload0
imul
iadd
乍一看,这不应该有所作为; 如果有的话,第二个版本更优,因为它使用的一个插槽更少.
所以我们需要深入挖掘下层(JIT)1.
请记住,JIT倾向于非常积极地展开小循环.事实上,我们观察到2 * (i * i)案件的展开时间为16倍:
030 B2: # B2 B3 <- B1 B2 Loop: B2-B2 inner main of N18 Freq: 1e+006 030 addl R11, RBP # int 033 movl RBP, R13 # spill 036 addl RBP, #14 # int 039 imull RBP, RBP # int 03c movl R9, R13 # spill 03f addl R9, #13 # int 043 imull R9, R9 # int 047 sall RBP, #1 049 sall R9, #1 04c movl R8, R13 # spill 04f addl R8, #15 # int 053 movl R10, R8 # spill 056 movdl XMM1, R8 # spill 05b imull R10, R8 # int 05f movl R8, R13 # spill 062 addl R8, #12 # int 066 imull R8, R8 # int 06a sall R10, #1 06d movl [rsp + #32], R10 # spill 072 sall R8, #1 075 movl RBX, R13 # spill 078 addl RBX, #11 # int 07b imull RBX, RBX # int 07e movl RCX, R13 # spill 081 addl RCX, #10 # int 084 imull RCX, RCX # int 087 sall RBX, #1 089 sall RCX, #1 08b movl RDX, R13 # spill 08e addl RDX, #8 # int 091 imull RDX, RDX # int 094 movl RDI, R13 # spill 097 addl RDI, #7 # int 09a imull RDI, RDI # int 09d sall RDX, #1 09f sall RDI, #1 0a1 movl RAX, R13 # spill 0a4 addl RAX, #6 # int 0a7 imull RAX, RAX # int 0aa movl RSI, R13 # spill 0ad addl RSI, #4 # int 0b0 imull RSI, RSI # int 0b3 sall RAX, #1 0b5 sall RSI, #1 0b7 movl R10, R13 # spill 0ba addl R10, #2 # int 0be imull R10, R10 # int 0c2 movl R14, R13 # spill 0c5 incl R14 # int 0c8 imull R14, R14 # int 0cc sall R10, #1 0cf sall R14, #1 0d2 addl R14, R11 # int 0d5 addl R14, R10 # int 0d8 movl R10, R13 # spill 0db addl R10, #3 # int 0df imull R10, R10 # int 0e3 movl R11, R13 # spill 0e6 addl R11, #5 # int 0ea imull R11, R11 # int 0ee sall R10, #1 0f1 addl R10, R14 # int 0f4 addl R10, RSI # int 0f7 sall R11, #1 0fa addl R11, R10 # int 0fd addl R11, RAX # int 100 addl R11, RDI # int 103 addl R11, RDX # int 106 movl R10, R13 # spill 109 addl R10, #9 # int 10d imull R10, R10 # int 111 sall R10, #1 114 addl R10, R11 # int 117 addl R10, RCX # int 11a addl R10, RBX # int 11d addl R10, R8 # int 120 addl R9, R10 # int 123 addl RBP, R9 # int 126 addl RBP, [RSP + #32 (32-bit)] # int 12a addl R13, #16 # int 12e movl R11, R13 # spill 131 imull R11, R13 # int 135 sall R11, #1 138 cmpl R13, #999999985 13f jl B2 # loop end P=1.000000 C=6554623.000000
我们看到有1个寄存器被"溢出"到堆栈中.
对于2 * i * i版本:
05a B3: # B2 B4 <- B1 B2 Loop: B3-B2 inner main of N18 Freq: 1e+006 05a addl RBX, R11 # int 05d movl [rsp + #32], RBX # spill 061 movl R11, R8 # spill 064 addl R11, #15 # int 068 movl [rsp + #36], R11 # spill 06d movl R11, R8 # spill 070 addl R11, #14 # int 074 movl R10, R9 # spill 077 addl R10, #16 # int 07b movdl XMM2, R10 # spill 080 movl RCX, R9 # spill 083 addl RCX, #14 # int 086 movdl XMM1, RCX # spill 08a movl R10, R9 # spill 08d addl R10, #12 # int 091 movdl XMM4, R10 # spill 096 movl RCX, R9 # spill 099 addl RCX, #10 # int 09c movdl XMM6, RCX # spill 0a0 movl RBX, R9 # spill 0a3 addl RBX, #8 # int 0a6 movl RCX, R9 # spill 0a9 addl RCX, #6 # int 0ac movl RDX, R9 # spill 0af addl RDX, #4 # int 0b2 addl R9, #2 # int 0b6 movl R10, R14 # spill 0b9 addl R10, #22 # int 0bd movdl XMM3, R10 # spill 0c2 movl RDI, R14 # spill 0c5 addl RDI, #20 # int 0c8 movl RAX, R14 # spill 0cb addl RAX, #32 # int 0ce movl RSI, R14 # spill 0d1 addl RSI, #18 # int 0d4 movl R13, R14 # spill 0d7 addl R13, #24 # int 0db movl R10, R14 # spill 0de addl R10, #26 # int 0e2 movl [rsp + #40], R10 # spill 0e7 movl RBP, R14 # spill 0ea addl RBP, #28 # int 0ed imull RBP, R11 # int 0f1 addl R14, #30 # int 0f5 imull R14, [RSP + #36 (32-bit)] # int 0fb movl R10, R8 # spill 0fe addl R10, #11 # int 102 movdl R11, XMM3 # spill 107 imull R11, R10 # int 10b movl [rsp + #44], R11 # spill 110 movl R10, R8 # spill 113 addl R10, #10 # int 117 imull RDI, R10 # int 11b movl R11, R8 # spill 11e addl R11, #8 # int 122 movdl R10, XMM2 # spill 127 imull R10, R11 # int 12b movl [rsp + #48], R10 # spill 130 movl R10, R8 # spill 133 addl R10, #7 # int 137 movdl R11, XMM1 # spill 13c imull R11, R10 # int 140 movl [rsp + #52], R11 # spill 145 movl R11, R8 # spill 148 addl R11, #6 # int 14c movdl R10, XMM4 # spill 151 imull R10, R11 # int 155 movl [rsp + #56], R10 # spill 15a movl R10, R8 # spill 15d addl R10, #5 # int 161 movdl R11, XMM6 # spill 166 imull R11, R10 # int 16a movl [rsp + #60], R11 # spill 16f movl R11, R8 # spill 172 addl R11, #4 # int 176 imull RBX, R11 # int 17a movl R11, R8 # spill 17d addl R11, #3 # int 181 imull RCX, R11 # int 185 movl R10, R8 # spill 188 addl R10, #2 # int 18c imull RDX, R10 # int 190 movl R11, R8 # spill 193 incl R11 # int 196 imull R9, R11 # int 19a addl R9, [RSP + #32 (32-bit)] # int 19f addl R9, RDX # int 1a2 addl R9, RCX # int 1a5 addl R9, RBX # int 1a8 addl R9, [RSP + #60 (32-bit)] # int 1ad addl R9, [RSP + #56 (32-bit)] # int 1b2 addl R9, [RSP + #52 (32-bit)] # int 1b7 addl R9, [RSP + #48 (32-bit)] # int 1bc movl R10, R8 # spill 1bf addl R10, #9 # int 1c3 imull R10, RSI # int 1c7 addl R10, R9 # int 1ca addl R10, RDI # int 1cd addl R10, [RSP + #44 (32-bit)] # int 1d2 movl R11, R8 # spill 1d5 addl R11, #12 # int 1d9 imull R13, R11 # int 1dd addl R13, R10 # int 1e0 movl R10, R8 # spill 1e3 addl R10, #13 # int 1e7 imull R10, [RSP + #40 (32-bit)] # int 1ed addl R10, R13 # int 1f0 addl RBP, R10 # int 1f3 addl R14, RBP # int 1f6 movl R10, R8 # spill 1f9 addl R10, #16 # int 1fd cmpl R10, #999999985 204 jl B2 # loop end P=1.000000 C=7419903.000000
在这里[RSP + ...],由于需要保留更多的中间结果,我们观察到更多的"溢出"和对堆栈的更多访问.
因此,问题的答案很简单:2 * (i * i)比2 * i * iJIT为第一种情况生成更优的汇编代码要快.
但当然很明显,第一版和第二版都没有任何好处; 循环可以真正受益于矢量化,因为任何x86-64 CPU至少具有SSE2支持.
所以这是优化器的问题; 通常情况下,它会过于积极地展开并在脚下射击,一直错过各种其他机会.
实际上,现代x86-64 CPU将指令进一步分解为微操作(μops),并具有寄存器重命名,μop缓存和循环缓冲等功能,循环优化比简单展开以获得最佳性能要精细得多.根据Agner Fog的优化指南:
如果平均指令长度超过4个字节,则由μop缓存引起的性能增益可能相当大.可以考虑以下优化μop缓存使用的方法:
确保关键循环足够小以适应μop缓存.
将最关键的循环条目和函数条目与32对齐.
避免不必要的循环展开.
避免使用有额外加载时间的指令
...
关于那些加载时间 - 即使最快的L1D命中也需要4个周期,额外的寄存器和μop,所以是的,即使是少量的内存访问也会影响紧密循环中的性能.
但回到矢量化的机会 - 看看它有多快,我们可以用GCC编译一个类似的C应用程序,它直接向它进行矢量化(AVX2显示,SSE2类似)2:
vmovdqa ymm0, YMMWORD PTR .LC0[rip] vmovdqa ymm3, YMMWORD PTR .LC1[rip] xor eax, eax vpxor xmm2, xmm2, xmm2 .L2: vpmulld ymm1, ymm0, ymm0 inc eax vpaddd ymm0, ymm0, ymm3 vpslld ymm1, ymm1, 1 vpaddd ymm2, ymm2, ymm1 cmp eax, 125000000 ; 8 calculations per iteration jne .L2 vmovdqa xmm0, xmm2 vextracti128 xmm2, ymm2, 1 vpaddd xmm2, xmm0, xmm2 vpsrldq xmm0, xmm2, 8 vpaddd xmm0, xmm2, xmm0 vpsrldq xmm1, xmm0, 4 vpaddd xmm0, xmm0, xmm1 vmovd eax, xmm0 vzeroupper
运行时间:
SSE:0.24秒,或者快2倍.
AVX:0.15秒,或快3倍.
AVX2:0.08秒,或快5倍.
1 要获取JIT生成的程序集输出,请获取调试JVM并运行-XX:+PrintOptoAssembly
2 C版本使用-fwrapv标志进行编译,这使得GCC能够将带符号的整数溢出视为二进制补码.
当乘法运算时2 * (i * i),JVM能够2将循环中的乘法分解出来,从而得到这个等效但更有效的代码:
int n = 0;
for (int i = 0; i <1000000000; i++) {
n += i * i;
}
n *= 2;
但是当乘法运算时(2 * i) * i,JVM不会优化它,因为在加法之前不再乘以常数.
以下是我认为是这种情况的几个原因:
if (n == 0) n = 1在循环开始时添加语句会导致两个版本同样有效,因为将乘法分解不再保证结果将是相同的
优化版本(通过将乘法除以2)与2 * (i * i)版本完全一样快
以下是我用来得出这些结论的测试代码:
public static void main(String[] args) {
long fastVersion = 0;
long slowVersion = 0;
long optimizedVersion = 0;
long modifiedFastVersion = 0;
long modifiedSlowVersion = 0;
for (int i = 0; i <10; i++) {
fastVersion += fastVersion();
slowVersion += slowVersion();
optimizedVersion += optimizedVersion();
modifiedFastVersion += modifiedFastVersion();
modifiedSlowVersion += modifiedSlowVersion();
}
System.out.println("Fast version: " + (double) fastVersion / 1000000000 + " s");
System.out.println("Slow version: " + (double) slowVersion / 1000000000 + " s");
System.out.println("Optimized version: " + (double) optimizedVersion / 1000000000 + " s");
System.out.println("Modified fast version: " + (double) modifiedFastVersion / 1000000000 + " s");
System.out.println("Modified slow version: " + (double) modifiedSlowVersion / 1000000000 + " s");
}
private static long fastVersion() {
long startTime = System.nanoTime();
int n = 0;
for (int i = 0; i <1000000000; i++) {
n += 2 * (i * i);
}
return System.nanoTime() - startTime;
}
private static long slowVersion() {
long startTime = System.nanoTime();
int n = 0;
for (int i = 0; i <1000000000; i++) {
n += 2 * i * i;
}
return System.nanoTime() - startTime;
}
private static long optimizedVersion() {
long startTime = System.nanoTime();
int n = 0;
for (int i = 0; i <1000000000; i++) {
n += i * i;
}
n *= 2;
return System.nanoTime() - startTime;
}
private static long modifiedFastVersion() {
long startTime = System.nanoTime();
int n = 0;
for (int i = 0; i <1000000000; i++) {
if (n == 0) n = 1;
n += 2 * (i * i);
}
return System.nanoTime() - startTime;
}
private static long modifiedSlowVersion() {
long startTime = System.nanoTime();
int n = 0;
for (int i = 0; i <1000000000; i++) {
if (n == 0) n = 1;
n += 2 * i * i;
}
return System.nanoTime() - startTime;
}
以下是结果:
Fast version: 5.7274411 s Slow version: 7.6190804 s Optimized version: 5.1348007 s Modified fast version: 7.1492705 s Modified slow version: 7.2952668 s
ByteCodes:https:
//cs.nyu.edu/courses/fall00/V22.0201-001/jvm2.html ByteCodes查看器:https://github.com/Konloch/bytecode-viewer
在我的JDK(Win10 64 1.8.0_65-b17)上,我可以重现并解释:
public static void main(String[] args) {
int repeat = 10;
long A = 0;
long B = 0;
for (int i = 0; i
输出:
...
405 ms A 785527736
327 ms B 785527736
404 ms A 785527736
329 ms B 785527736
404 ms A 785527736
328 ms B 785527736
404 ms A 785527736
328 ms B 785527736
410 ms
333 ms
所以为什么?字节代码是这样的:
private static multiB(int arg0) { // 2 * (i * i)
L1 {
iconst_2
iload0
iload0
imul
imul
ireturn
}
L2 {
}
}
private static multi(int arg0) { // 2 * i * i
L1 {
iconst_2
iload0
imul
iload0
imul
ireturn
}
L2 {
}
}
区别在于:
括号(2 * (i * i)):
推送const堆栈
在堆栈上推送本地
在堆栈上推送本地
乘以堆栈顶部
乘以堆栈顶部
没有括号(2 * i * i):
推送const堆栈
在堆栈上推送本地
乘以堆栈顶部
在堆栈上推送本地
乘以堆栈顶部
加载所有堆栈然后再运行比在堆栈和操作之间切换更快.
4> 小智..:
卡斯珀德在接受的回答中评论道:
Java和C示例使用完全不同的寄存器名称.两个都是使用AMD64 ISA的例子吗?
xor edx, edx
xor eax, eax
.L2:
mov ecx, edx
imul ecx, edx
add edx, 1
lea eax, [rax+rcx*2]
cmp edx, 1000000000
jne .L2
我没有足够的声誉在评论中回答这个问题,但这些是相同的ISA.值得指出的是,GCC版本使用32位整数逻辑,而JVM编译版本在内部使用64位整数逻辑.
R8到R15只是新的X86_64 寄存器.EAX到EDX是RAX到RDX通用寄存器的下半部分.答案中的重要部分是GCC版本未展开.它只是每个实际的机器代码循环执行一轮循环.虽然JVM版本在一个物理循环中有16轮循环(基于rustyx答案,我没有重新解释程序集).这是使用更多寄存器的原因之一,因为循环体实际上长了16倍.
糟糕的gcc并没有注意到它可以使`* 2`脱离循环。尽管在这种情况下,这样做并不是一个胜利,因为使用LEA是免费的。在Intel CPU上,“ lea eax,[rax + rcx * 2]”与“ add eax,ecx”具有相同的1c延迟。但是,在AMD CPU上,任何缩放索引都会将LEA延迟增加到2个周期。因此,循环承载的依赖链延长到2个周期,成为Ryzen的瓶颈。(在Ryzen和Intel上,“ imul ecx,edx”的吞吐量为每个时钟1个)。
5> 小智..:
虽然与问题的环境没有直接关系,但仅仅是为了好奇,我在.Net Core 2.1,x64,发布模式上做了同样的测试.这是一个有趣的结果,证实了在力量的黑暗面发生的类似的phonemenia(其他方式).码:
static void Main(string[] args)
{
Stopwatch watch = new Stopwatch();
Console.WriteLine("2 * (i * i)");
for (int a = 0; a <10; a++)
{
int n = 0;
watch.Restart();
for (int i = 0; i <1000000000; i++)
{
n += 2 * (i * i);
}
watch.Stop();
Console.WriteLine($"result:{n}, {watch.ElapsedMilliseconds} ms");
}
Console.WriteLine();
Console.WriteLine("2 * i * i");
for (int a = 0; a <10; a++)
{
int n = 0;
watch.Restart();
for (int i = 0; i <1000000000; i++)
{
n += 2 * i * i;
}
watch.Stop();
Console.WriteLine($"result:{n}, {watch.ElapsedMilliseconds}ms");
}
}
结果:
2*(i*i)
结果:119860736,438ms
结果:119860736,433ms
结果:119860736,437ms
结果:119860736,435ms
结果:119860736,436ms
结果:119860736,435ms
结果:119860736,435ms
结果:119860736,439ms
结果:119860736,436ms
结果:119860736,437ms
2*i*i
结果:119860736,417ms
结果:119860736,417ms
结果:119860736,417ms
结果:119860736,418ms
结果:119860736,418ms
结果:119860736,417ms
结果:119860736,418ms
结果:119860736,416ms
结果:119860736,417ms
结果:119860736,418ms
除此之外是另一种方式
@SamB它仍然在imgur.com域上,这意味着它只能在imgur中生存.
6> paulsm4..:
我得到了类似的结果:
2 * (i * i): 0.458765943 s, n=119860736
2 * i * i: 0.580255126 s, n=119860736
如果两个循环都在同一个程序中,或者每个循环都在一个单独的.java文件/ .class中,我在单独的运行中执行,我得到了SAME结果.
最后,这是javap -c -v <.java>每个的反编译:
3: ldc #3 // String 2 * (i * i):
5: invokevirtual #4 // Method java/io/PrintStream.print:(Ljava/lang/String;)V
8: invokestatic #5 // Method java/lang/System.nanoTime:()J
8: invokestatic #5 // Method java/lang/System.nanoTime:()J
11: lstore_1
12: iconst_0
13: istore_3
14: iconst_0
15: istore 4
17: iload 4
19: ldc #6 // int 1000000000
21: if_icmpge 40
24: iload_3
25: iconst_2
26: iload 4
28: iload 4
30: imul
31: imul
32: iadd
33: istore_3
34: iinc 4, 1
37: goto 17
与
3: ldc #3 // String 2 * i * i:
5: invokevirtual #4 // Method java/io/PrintStream.print:(Ljava/lang/String;)V
8: invokestatic #5 // Method java/lang/System.nanoTime:()J
11: lstore_1
12: iconst_0
13: istore_3
14: iconst_0
15: istore 4
17: iload 4
19: ldc #6 // int 1000000000
21: if_icmpge 40
24: iload_3
25: iconst_2
26: iload 4
28: imul
29: iload 4
31: imul
32: iadd
33: istore_3
34: iinc 4, 1
37: goto 17
仅供参考 -
java -version
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
获取[debug jre](https://github.com/ojdkbuild/ojdkbuild/releases)并使用`-XX:+ PrintOptoAssembly`运行.或者只是使用vtune或类似的.
7> Oleksandr Py..:
使用Java 11进行有趣的观察并使用以下VM选项关闭循环展开:
-XX:LoopUnrollLimit=0
带有2 * (i * i)表达式的循环导致更紧凑的本机代码1:
L0001: add eax,r11d
inc r8d
mov r11d,r8d
imul r11d,r8d
shl r11d,1h
cmp r8d,r10d
jl L0001
与2 * i * i版本相比:
L0001: add eax,r11d
mov r11d,r8d
shl r11d,1h
add r11d,2h
inc r8d
imul r11d,r8d
cmp r8d,r10d
jl L0001
Java版本:
java version "11" 2018-09-25
Java(TM) SE Runtime Environment 18.9 (build 11+28)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11+28, mixed mode)
基准测试结果:
Benchmark (size) Mode Cnt Score Error Units
LoopTest.fast 1000000000 avgt 5 694,868 ± 36,470 ms/op
LoopTest.slow 1000000000 avgt 5 769,840 ± 135,006 ms/op
基准源代码:
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Warmup(iteratiOns= 5, time = 5, timeUnit = TimeUnit.SECONDS)
@Measurement(iteratiOns= 5, time = 5, timeUnit = TimeUnit.SECONDS)
@State(Scope.Thread)
@Fork(1)
public class LoopTest {
@Param("1000000000") private int size;
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(LoopTest.class.getSimpleName())
.jvmArgs("-XX:LoopUnrollLimit=0")
.build();
new Runner(opt).run();
}
@Benchmark
public int slow() {
int n = 0;
for (int i = 0; i
1 - 使用的VM选项: -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:LoopUnrollLimit=0
哇,这是一些脑死亡的问题.而不是在复制它之前递增`i`*以计算&#39;2*i`,而是在它需要额外的`add r11d,2`指令之后执行它.(另外它错过了`添加相同,相同&#39;的窥视孔而不是`shl`乘以1(在更多端口上添加运行).它还错过了一个LEA窥视孔,用于`x*2 + 2`(`lea r11d,[r8*2 + 2]`)如果它真的想按照那个顺序做一些疯狂的指令调度的原因.我们已经可以从展开的版本中看到错过了LEA的成本是u*很多uops,就像两个循环一样这里.
如果JIT编译器有时间在长时间运行的循环中寻找优化,那么`lea eax,[rax + r11*2]`将替换2个指令(在两个循环中).任何体面的提前编译器都会找到它.(除非可能只调整AMD,因为缩放索引LEA有2个周期延迟,所以可能不值得.)
8> NoDataFound..:
我使用默认原型尝试了JMH:我还添加了基于Runemoro的优化版本的解释.
@State(Scope.Benchmark)
@Warmup(iteratiOns= 2)
@Fork(1)
@Measurement(iteratiOns= 10)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
//@BenchmarkMode({ Mode.All })
@BenchmarkMode(Mode.AverageTime)
public class MyBenchmark {
@Param({ "100", "1000", "1000000000" })
private int size;
@Benchmark
public int two_square_i() {
int n = 0;
for (int i = 0; i
结果如下:
Benchmark (size) Mode Samples Score Score error Units
o.s.MyBenchmark.square_i_two 100 avgt 10 58,062 1,410 ns/op
o.s.MyBenchmark.square_i_two 1000 avgt 10 547,393 12,851 ns/op
o.s.MyBenchmark.square_i_two 1000000000 avgt 10 540343681,267 16795210,324 ns/op
o.s.MyBenchmark.two_i_ 100 avgt 10 87,491 2,004 ns/op
o.s.MyBenchmark.two_i_ 1000 avgt 10 1015,388 30,313 ns/op
o.s.MyBenchmark.two_i_ 1000000000 avgt 10 967100076,600 24929570,556 ns/op
o.s.MyBenchmark.two_square_i 100 avgt 10 70,715 2,107 ns/op
o.s.MyBenchmark.two_square_i 1000 avgt 10 686,977 24,613 ns/op
o.s.MyBenchmark.two_square_i 1000000000 avgt 10 652736811,450 27015580,488 ns/op
在我的电脑上(Core i7 860,在我的智能手机上阅读时没有什么区别):
n += i*i那n*2是第一次
2 * (i * i) 是第二个.
JVM显然没有以与人类相同的方式进行优化(基于Runemoro答案).
现在,阅读字节码: javap -c -v ./target/classes/org/sample/MyBenchmark.class
2*(i*i)(左)和2*i*i(右)之间的差异:https://www.diffchecker.com/cvSFppWI
2*(i*i)和优化版本之间的差异:https://www.diffchecker.com/I1XFu5dP
我不是字节码方面的专家,但我们iload_2之前imul:我们可能会得到不同之处:我可以假设JVM优化读数i两次(i已经在这里,没有必要再次加载),而在2*i*i它不能.
AFAICT字节码与性能无关,我不会尝试根据它来估计更快的速度.它只是JIT编译器的源代码......确保可以保留重新排序源代码行的意义 - 改变结果代码和效率,但这一切都是不可预测的.
9> GhostCat say..:
更多的附录.我使用IBM最新的Java 8 JVM重新进行了实验:
java version "1.8.0_191"
Java(TM) 2 Runtime Environment, Standard Edition (IBM build 1.8.0_191-b12 26_Oct_2018_18_45 Mac OS X x64(SR5 FP25))
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
这显示了非常相似的结果:
0.374653912 s
n = 119860736
0.447778698 s
n = 119860736
(第二个结果使用2*i*i).
有趣的是,当在同一台机器上运行时,却使用Oracle java:
Java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
结果平均有点慢:
0.414331815 s
n = 119860736
0.491430656 s
n = 119860736
长话短说:即使HotSpot的次要版本号在这里也很重要,因为JIT实现中的细微差别会产生显着的影响.
10> Jorn Vernee..:
这两种添加方法会生成略有不同的字节代码:
17: iconst_2
18: iload 4
20: iload 4
22: imul
23: imul
24: iadd
对于2 * (i * i)vs:
17: iconst_2
18: iload 4
20: imul
21: iload 4
23: imul
24: iadd
为了2 * i * i.
当使用这样的JMH基准时:
@Warmup(iteratiOns= 5, batchSize = 1)
@Measurement(iteratiOns= 5, batchSize = 1)
@Fork(1)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Benchmark)
public class MyBenchmark {
@Benchmark
public int noBrackets() {
int n = 0;
for (int i = 0; i <1000000000; i++) {
n += 2 * i * i;
}
return n;
}
@Benchmark
public int brackets() {
int n = 0;
for (int i = 0; i <1000000000; i++) {
n += 2 * (i * i);
}
return n;
}
}
差异很明显:
# JMH version: 1.21
# VM version: JDK 11, Java HotSpot(TM) 64-Bit Server VM, 11+28
# VM options:
Benchmark (n) Mode Cnt Score Error Units
MyBenchmark.brackets 1000000000 avgt 5 380.889 ± 58.011 ms/op
MyBenchmark.noBrackets 1000000000 avgt 5 512.464 ± 11.098 ms/op
您观察到的是正确的,而不仅仅是您的基准测试风格的异常(即没有热身,请参阅如何在Java中编写正确的微基准测试?)
用Graal再次跑步:
# JMH version: 1.21
# VM version: JDK 11, Java HotSpot(TM) 64-Bit Server VM, 11+28
# VM options: -XX:+UnlockExperimentalVMOptions -XX:+EnableJVMCI -XX:+UseJVMCICompiler
Benchmark (n) Mode Cnt Score Error Units
MyBenchmark.brackets 1000000000 avgt 5 335.100 ± 23.085 ms/op
MyBenchmark.noBrackets 1000000000 avgt 5 331.163 ± 50.670 ms/op
你会发现结果更接近,这是有道理的,因为Graal是一个整体性能更好,更现代的编译器.
所以这实际上取决于JIT编译器能够优化特定代码片段的程度,并且不一定有合理的理由.








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 