微服务20_多级缓存01:JVM进程缓存前言:什么是多级缓存?1、传统缓存的问题:2、多级缓存方案一、JVM进程缓存(Tomcat内部编写进程缓存)1、导入商品案例1.安装mysql2.导入Demo3
微服务20_多级缓存01:JVM进程缓存
- 前言:什么是多级缓存?
- 一、JVM进程缓存(Tomcat内部编写进程缓存)
- 1、导入商品案例
- 1.安装mysql
- 2.导入Demo
- 3. 商品查询页面 来调用controller的接口
- 4.反向代理的配置:
- 了解本地缓存和分布式缓存
- 2、初始Caffeine
- 3、实现进程缓存
前言:什么是多级缓存?
缓存的作用是减轻数据库的压力,缩短服务相应的时间,从而提高整个并发的能力,Redis单节并发以及很高了,但是依然有上限,随着互联网的发展,用户体量越来越大,比如淘宝京东的流量能达到数亿级别的流量。那么多级缓存就是为了应对多级缓存高并发。
1、传统缓存的问题:
用户请求到达Tomcat服务器,然后优先查询redis,如果redis命中,直接返回。未命中就访问数据库。 也能很大的程度减少数据库压力。
问题:
- 用户请求直接进入Tomcat,再去redis查询。而Tomcat并发能力不如redis。从而Tomcat的并发性能成为了整个系统的瓶颈。
- redis有淘汰策略,所以说缓存有过期的可能性。当redis缓存失效时,例如雪崩、穿透情况,造成大量请求到达数据库。
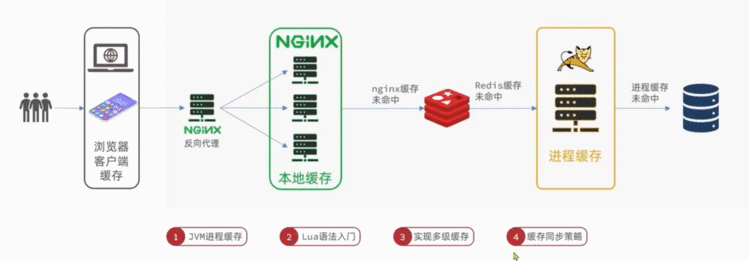
2、多级缓存方案
多级缓存就是充分利用请求处理的每个缓存,分别添加缓存,减轻Tomcat的压力,提升服务性能:
- 第一级缓存:用户通过手机访问浏览器得到渲染。 浏览器缓存。
因为浏览器可以把返回的静态资源缓存到本地的,那么下次用户访问服务器时,只需要检查有没有变化,没有变化服务器直接返回304状态码,不用返回数据了。304:说明本地有。直接渲染本地存着的页面。 减少数据的传输,提高渲染和相应的速度。
- 第二级缓存:Nginx本地缓存。浏览器本地缓存未成功,请求Nginx服务器.Ngin之前是用来做请求代理。在这里形成第二级缓存,称为Nginx本地缓存。 也可以做业务的编写。那么将数据缓存到nging本地,用户请求来了,如果有直接返回,不用到达Tomcat。
在Nginx内部去实现对redis、Tomcat的访问等等的编写,不再单单是业务代理服务器了,变成了web业务服务了,在里面写业务逻辑了。
做成集群:一个Nginx做反向代理,集群做本地缓存,做业务的Nginx的服务器。
- 第三级缓存:redis缓存。
- 第四级缓存:Tomcat进程缓存。
- 第五级缓存:最后到达数据库缓存。
解决的问题:
- 大多数请求由Ngin来进行处理了,减少了对Tomcat的处理,从而Tomcat不会成为服务器的瓶颈了。
- Tomcat也有进程缓存,很大程度减少对数据库的查询
一、JVM进程缓存(Tomcat内部编写进程缓存)
Tomcat服务内部添加缓存, 业务进来以后优先查询进程缓存,缓存未命中,在去查数据库。

1、导入商品案例
1.安装mysql
后期做数据同步需要用到MySQL的主从功能,所以需要大家在虚拟机中,利用Docker来运行一个MySQL容器。
- 先进行将mysql5.7.25版本的mysql压缩包,放到Linux中,进行解压
- 准备挂载容器。为了方便后期配置MySQL,我们先准备两个目录,用于挂载容器的数据和配置文件目录:
# 进入/tmp目录
cd /tmp
# 创建文件夹
mkdir mysql
# 进入mysql目录
cd mysql
- 运行docker命令,运行mysql 。进入mysql目录后,执行下面的Docker命令:
推荐在/tmp/mysql的文件下,运行下面的命令: 因为指定挂载路径是:$pwd。当前路径下创建文件,并挂载。
docker run \
-p 3306:3306 \
--name mysql \
-v $PWD/conf:/etc/mysql/conf.d \
-v $PWD/logs:/logs \
-v $PWD/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123 \
--privileged \
-d \
mysql:5.7.25
docker查看当前运行的容器。docker ps-a是查看所有容器
- 修改配置:添加字符集
在/tmp/mysql/conf目录添加一个my.cnf文件,作为mysql的配置文件:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
添加后:并重启mysql: docker restart mysql
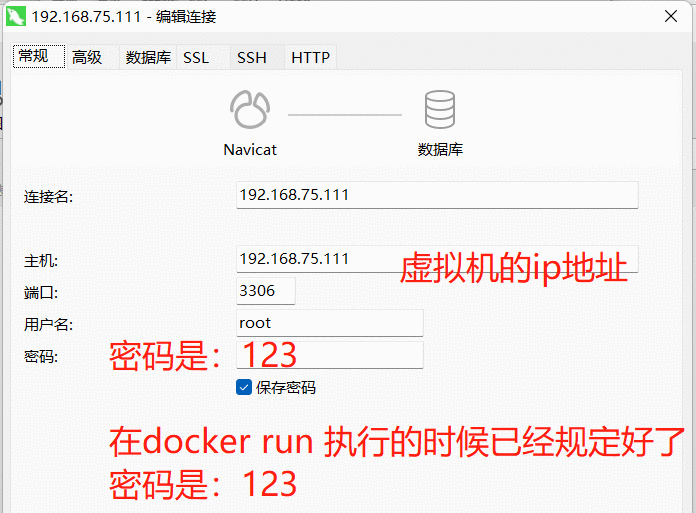
- 用navicat连接虚拟机的数据库:
创建表名:heima
表字段分析:
CREATE TABLE `tb_item` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '商品id',
`title` varchar(264) NOT NULL COMMENT '商品标题',
`name` varchar(128) NOT NULL DEFAULT '' COMMENT '商品名称',
`price` bigint(20) NOT NULL COMMENT '价格(分)',
`image` varchar(200) DEFAULT NULL COMMENT '商品图片',
`category` varchar(200) DEFAULT NULL COMMENT '类目名称',
`brand` varchar(100) DEFAULT NULL COMMENT '品牌名称',
`spec` varchar(200) DEFAULT NULL COMMENT '规格',
`status` int(1) DEFAULT '1' COMMENT '商品状态 1-正常,2-下架,3-删除',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
KEY `status` (`status`) USING BTREE,
KEY `updated` (`update_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=50002 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='商品表';
CREATE TABLE `tb_item_stock` (
`item_id` bigint(20) NOT NULL COMMENT '商品id,关联tb_item表',
`stock` int(10) NOT NULL DEFAULT '9999' COMMENT '商品库存',
`sold` int(10) NOT NULL DEFAULT '0' COMMENT '商品销量',
PRIMARY KEY (`item_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=COMPACT;
为什么要做两张表格呢?
一个商品的数量是非常多的。
一方面数据解耦,字段太多查询效率太低了。
另一方面需要数据需要缓存,那么一条整个数据去做缓存,如果一个字段做了修改,那么整条数据全部失效了,就得所有信息都得去数据库做加载。
例如:将所有信息存入一张表中,那么库存改了以后,就得重新加载该条数据。 那么如果将分为多个表,当库存修改了以后,只需要将库存表进行加载即可,不需要获取所有的商品信息了。
2.导入Demo
基于mybatis-plus快速实现单表的增删改查:
- 分页查询商品
- 新增商品
- 修改商品
- 修改库存
- 删除商品
- 根据id查询商品
- 根据id查询库存
- application.yml文件:
mysql放到了Linux的docker中了,所以说:
数据库的URL:是自己虚拟机的ip地址。
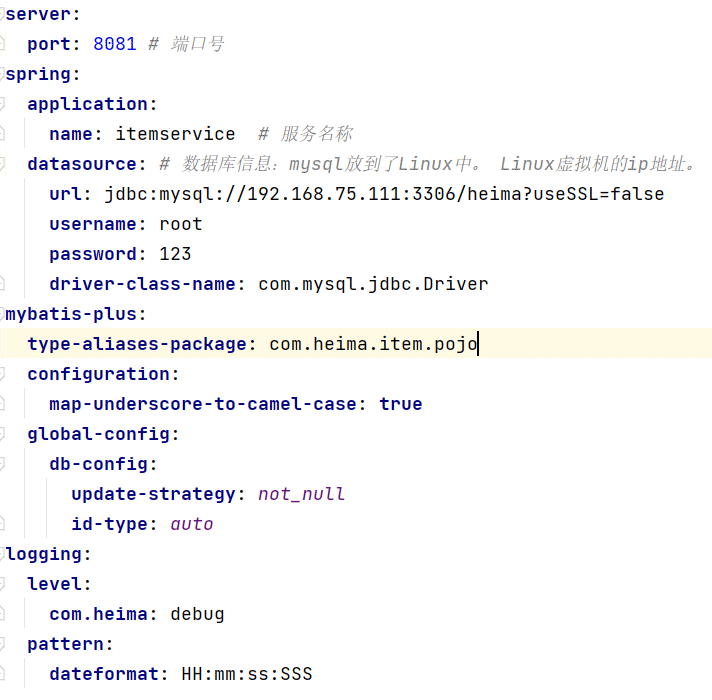
需要修改为自己的虚拟机地址信息、还有账号和密码。
修改后,启动服务,访问:http://localhost:8081/item/10001即可查询数据
3. 商品查询页面 来调用controller的接口
商品查询是购物页面,与商品管理的页面是分离的。
商品查询页面放在Nginx反向代理服务器上面,作为静态资源服务器,用户来请求商品页面的时候,Nginx返给用户。先返回的只是静态页面,数据再从后台查询了【Nginx本地、redis、Tomcat、数据库】
部署方式如图:

我们需要准备一个反向代理的nginx服务器,来部署静态资源。如上图红框所示,将静态的商品页面放到nginx目录中。
页面需要的数据通过ajax向服务端(nginx业务集群)查询。
将其拷贝到一个非中文目录下,运行这个nginx服务。
运行命令:
start nginx.exe
然后访问 http://localhost/item.html?id=10001即可:
localhost 访问的是Nginx
item.html 访问的商品页面
id=10001 是具体的商品
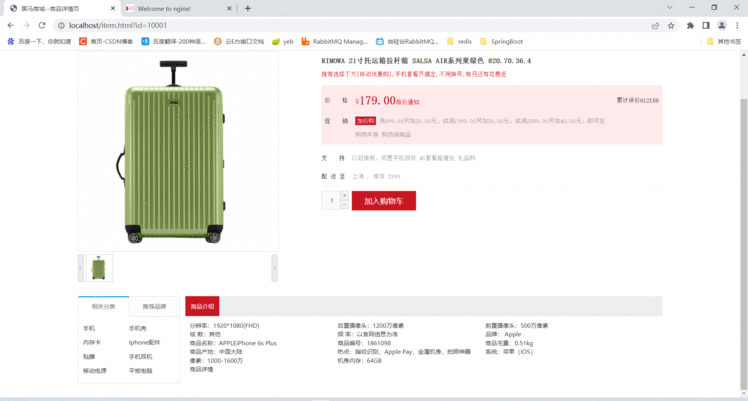
请求地址是:localhost/api/item/10001
并没有添加端口,请求到了80端口的nginx服务器了
用户请求被Nginx反向代理拿到了,它不处理,而是代理到nginx业务集群中去,在去做多级缓存。 所以要完成反向代理的配置
4.反向代理的配置:
nginx/conf/nginx.conf
location /api
以api开头的请求,就被Nginx配置拦截到了,反向代理到负载均衡的配置:http://nginx-cluster
nginx-cluster:是业务集群,本地缓存、redis缓存、Tomcat缓存
现在,页面是假数据展示的。我们需要向服务器发送ajax请求,查询商品数据。
打开控制台,可以看到页面有发起ajax查询数据:
而这个请求地址同样是80端口,所以被当前的nginx反向代理了。
查看nginx的conf目录下的nginx.conf文件:

#user nobody;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
# nginx的业务集群,做Nginx本地缓存、redis缓存、Tomcat缓存
upstream nginx-cluster{
server 192.168.75.111:8081;
}
server {
listen 80;
server_name localhost;
location /api {
proxy_pass http://nginx-cluster;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
了解本地缓存和分布式缓存
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
分布式缓存:例如redis
- 优点:存储量更大、可靠性更好、可以在集群间共享。
- 缺点:访问缓存有网咯开销。
独立于Tomcat之外的,Tomcat访问redis时要发起网络请求,所以说有网络开销。
- 场景:缓存数量较大、可靠性要求高、需要在集群间共享
进程本地缓存:例如hashMap、GuavaCache
- 优点:读取本地内存,没有网络开销,速度更快。
- 缺点:存储容量有限,可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
2、初始Caffeine
专业的进程缓存技术。
Caffeine是一个基于java8开发的,提供了近乎最佳命中率的高性能的本地缓存。目前Spring内部的缓存使用的就是Caffeine。
官网:ttps://github.com/ben-manes/caffeine
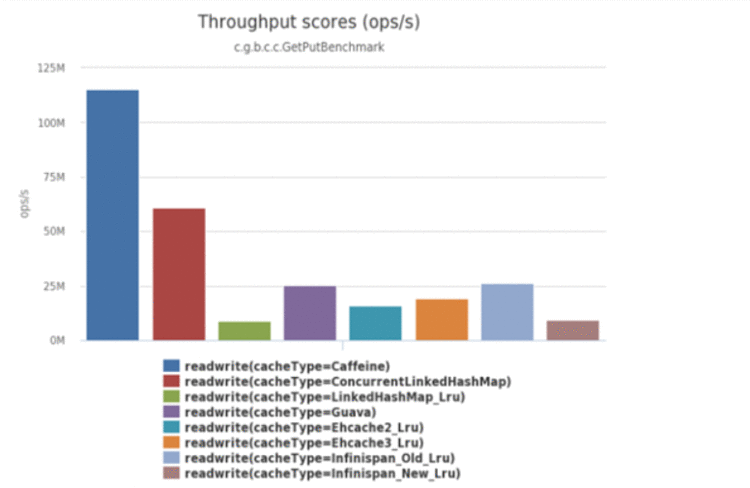
官方读写性能测试:
通过下面的例子进行学习Caffeine的使用:
@Test
void testBasicOps() {
Cache<String, String> cache = Caffeine.newBuilder().build();
cache.put("gf", "迪丽热巴");
String gf = cache.getIfPresent("gf");
System.out.println("gf = " + gf);
String defaultGF = cache.get("defaultGF", key -> {
return "柳岩";
});
System.out.println("defaultGF = " + defaultGF);
}
Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1)
.build();
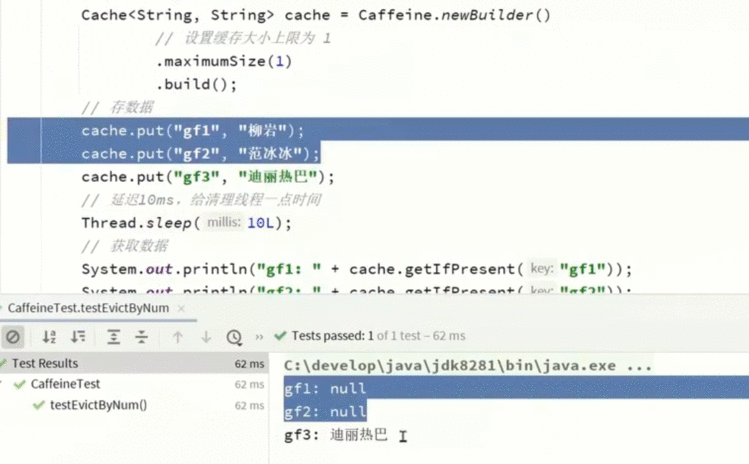
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofSeconds(10))
.build();
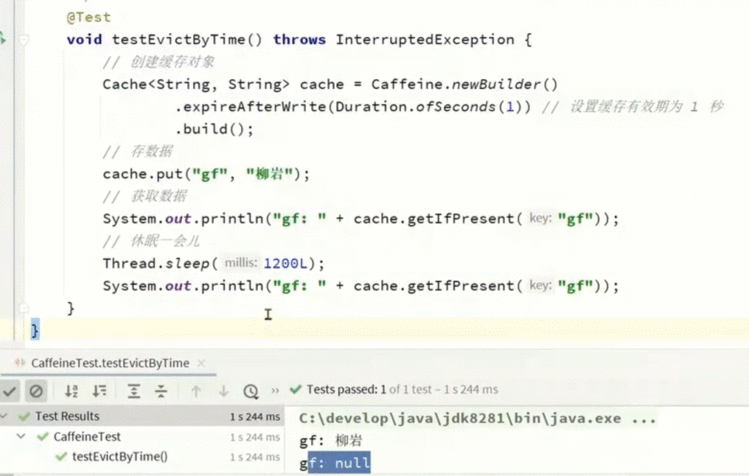
- 方法三:基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
3、实现进程缓存
案例:实现商品的查询本地进程缓存
利用Caffeien实现下列需求:
- 给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
- 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
- 缓存初始大小为100
- 缓存上限为10000
- 添加Bean对象Cache
首先,我们需要定义两个Caffeine的缓存对象,分别保存商品、库存的缓存数据。
在item-service的com.heima.item.config包下定义CaffeineConfig类:
package com.heima.item.config;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CaffeineConfig {
@Bean
public Cache<Long, Item> itemCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
@Bean
public Cache<Long, ItemStock> itemStockCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
}
- 修改controller类,先进行缓存中拿数据,未中再去数据库拿数据,如果拿到数据后放到缓存后,在返回用户数据。
然后,修改item-service中的com.heima.item.web包下的ItemController类,添加缓存逻辑:
@Autowired
private Cache<Long,Item> itemCache;
@Autowired
private Cache<Long,ItemStock> itemStockCache;
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id){
return itemCache.get(id,key->itemService.query()
.ne("status", 3)
.eq("id", key)
.one()
);
}
@GetMapping("/stock/{id}")
public ItemStock findStockById(@PathVariable("id") Long id){
return itemStockCache.get(id,key->stockService.getById(key));
}
}
测试:
当添加缓存之前,每当刷新一下页面,就会去数据库进行查询一次:

添加缓存之后,只去数据库查询一次,再重新刷新页面,不会去数据库进行查询了,而是直接返回缓存信息即可。










 京公网安备 11010802041100号
京公网安备 11010802041100号