作者:Hide-my-love | 来源:互联网 | 2023-08-30 21:27
篇首语:本文由编程笔记#小编为大家整理,主要介绍了Hadoop简介与伪分布式搭建—DAY01相关的知识,希望对你有一定的参考价值。
一、 Hadoop的一些相关概念及思想
1、hadoop的核心组成:
(1)hdfs分布式文件系统
(2)mapreduce 分布式批处理运算框架
(3)yarn 分布式资源调度系统
2、hadoop的由来:最早是从nutch+lucene项目中诞生的,用于存储和处理海量的网页
3、hadoop的生态系统:
(1)Hbase--分布式数据库系统
(2)hive--支持sql语法的分析工具(数据仓库)
(3)sqoop--传统关系型数据库到hadoop平台之间的属于导入导出工具
(4)mahout--机器学习算法库(基于mapreduce实现的众多的机器学习算法)(5)5)flume--分布式的日志采集系统
(6)storm--分布式实时流式运算框架
(7)spark--分布式实时计算框架
(8)HDFS--一个分布式文件系统
··a、文件是被切分后存放在多台节点上,而且每一个块有多个副本
··b、文件系统中有两类节点(namenode--元数据管理,datanode--存储数据块)
3、lucene+solr :参考百度这种所搜引擎的技术结构
二、Hadoop伪分布式搭建
1.准备Linux环境
1.0 设置网络
(1)设置windows
(2)设置vmware
(3)设置Linux(centos) 详见1.2
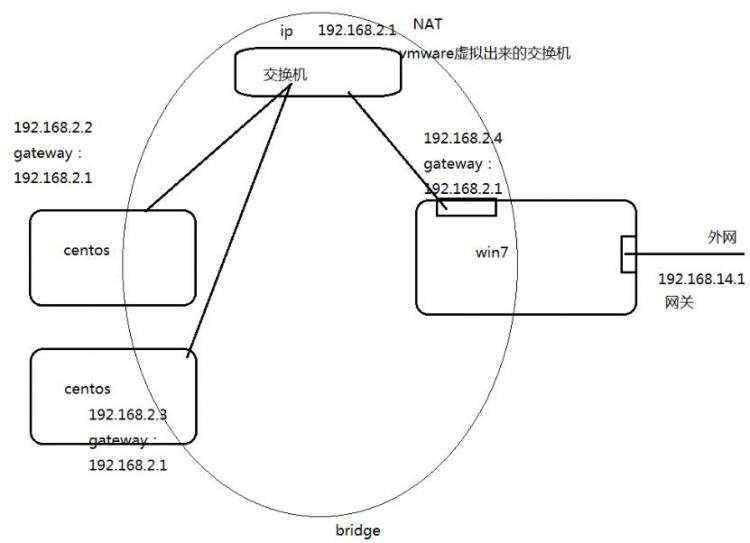
参考图:网络设置图
1.1修改Linux的IP
两种方式:
第一种:通过Linux图形界面进行修改(强烈推荐)
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮
-> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.2.200 子网掩码:255.255.255.0 网关:192.168.2.1 ->
->DNS server:8.8.8.8->apply
第二种:修改配置文件方式(屌丝程序猿专用)
sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static" ###
HWADDR="00:0C:29:3C:BF:E7"
IPV6INIT="yes"
NM_COnTROLLED="yes"
OnBOOT="yes"
TYPE="Ethernet"
UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"
IPADDR="192.168.2.200" ###
NETMASK="255.255.255.0" ###
GATEWAY="192.168.2.1" ###
注意:修改后不会自动生效,需要重启Linux服务器(reboot)或者重启network服务(service network restart)
1.2修改主机名和IP的映射关系
(1)修改主机名:sudo vi /etc/sysconfig/network
HOSTNAME=weekend110
sudo hostname weekend110 #立即生效
eixt #退出当前用户,重新登入后,即可看见更改的用户名 如:[hadoop@weekend110 ~]$
(2)建立ip映射关系
sudo vim /etc/hosts
192.168.2.200 weekend110 # 打开文件后,添加该条记录
1.3关闭防火墙 (系统服务,用sudo命令)
#查看防火墙状态
sudo service iptables status
#关闭防火墙
sudo service iptables stop
#查看防火墙开机启动状态
sudo chkconfig iptables --list
#关闭防火墙开机启动
sudo chkconfig iptables off
1.4重启Linux
reboot
1.5 补充:怎么在Linux环境下不启动图形界面
(1)让普通用户具备sudo执行权限
su root #切换到root用户
vim /etc/sudoers #编辑sudoers文件将当期用户(hadoop)加入到sudoers file
然后在root ALL=(ALL) ALL 下面添加:hadoop ALL=(ALL) ALL, 如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
(2)sudo vi /etc/inittab
将启动级别改为3, 即 id:3:initdefault:
注释:在图形界面下,用 命令 init 3 更改为命令行界面
2.安装JDK
2.1从windows系统上传文件
输入命令alt+p 后出现sftp窗口,然后put d:\\xxx\\yy\\ll\\jdk-7u_65-i585.tar.gz
2.2解压jdk
#创建文件夹
mkdir /home/hadoop/app
#解压
tar -zxvf jdk-7u55-linux-i586.tar.gz -C /home/hadoop/app
2.3将java添加到环境变量中
sudo vi /etc/profile #对所有用户都会生效
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
export PATH=$PATH:$JAVA_HOME/bin #当前路径加上后面的路径,: 表示相加
#刷新配置
source /etc/profile
3.安装hadoop2.4.1
先上传hadoop的安装包到服务器上去/home/hadoop/ , 即输入命令alt+p 后出现sftp窗口,然后put d:\\xxx\\yy\\ll\\jdk-7u_65-i585.tar.gz
注意:hadoop2.x的配置文件 /home/hadoop/app/hadoop-2.4.1/etc/hadoop
伪分布式需要修改5个配置文件
3.1配置hadoop
第一个:hadoop-env.sh #环境变量
vim hadoop-env.sh
#第27行
export JAVA_HOME=/usr/java/jdk1.7.0_65
第二个:core-site.xml #公共的配置文件,根据这个就知道namenode在哪台主机
fs.defaultFS
hdfs://weekend110:9000/ #hdfs://weekend110:9000/ 表示namenode的地址
hadoop.tmp.dir
/home/hadoop/app/hadoop-2.4.1/data/
第三个:hdfs-site.xml hdfs-default.xml
dfs.replication
1 #默认配置3个副本,但是搭建伪分布式,一台机器,所以这里给1
第四个:mapred-site.xml (改名字:mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
mapreduce.framework.name
yarn
第五个:yarn-site.xml
yarn.resourcemanager.hostname
weekend110
yarn.nodemanager.aux-services
mapreduce_shuffle
第六个:slaves
weekend110
...
3.2将hadoop添加到环境变量
sudo vim /etc/profile
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile #刷新
3.3格式化namenode(是对namenode进行初始化)
hadoop namenode -format
3.4启动hadoop
进入到:cd app/hadoop-2.4.1/sbin/
先启动HDFS
start-dfs.sh
stop-dfs.sh
再启动YARN
start-yarn.sh
stop-yarn.sh
3.5验证是否启动成功
使用jps命令验证 (查看所有的进程)
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
3.6 网页查看&测试hdfs&测试mapreduce
(1)网页查看:
进入windows, C:\\Windows\\System32\\drivers\\etc,修改hosts , 添加一条记录: 192.128.2.200 weekend110
访问:http://192.168.2.200:50070 ,或者 http://weekend110:50070(HDFS管理界面)
访问http://192.168.2.200:8088 (MR管理界面)
(2)测试hdfs
从Linux向hdfs传文件: hadoop fs -put jdk-7u65-linux-i586.tar.gz hdfs://weekend110:9000/
从hdfs下载文件到linux: hadoop fs -get hdfs://weekend110:9000/jdk-7u65-linux-i586.tar.gz
(3)测试mapreduce
在/home/hadoop/app/hadoop-2.4.1/share/hadoop/mapreduce 下,有hadoop-mapreduce-examples-2.4.1.jar,里面有mapreduce例子程序
例子1:运行hadoop jar hadoop-mapreduce-examples-2.4.1.jar pi 5 5
例子2:
新建一个文本:[hadoop@weekend110 mapreduce]$ vi test.txt
hello world
hello kitty
hello kitty
hello kugou
hello baby
在hdfs新建目录wordcount: hadoop fs -mkdir hdfs://weekend110:9000/wordcount(或者hadoop fs -mkdir /wordcount)
建立子目录wordcount/input : hadoop fs -mkdir hdfs://weekend110:9000/wordcount/input (或者hadoop fs -mkdir /wordcount/input)
将test.txt上传至hdfs: hadoop fs -put test.txt /wordcount/input
上传结果在HDFS管理界面可以查看
运行wordcount例子: hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount /wordcount/input /wordcount/output
查看生成的结果:hadoop fs -ls /wordcount/output Found 2 items -rw-r--r-- 1 hadoop supergroup 0 2017-10-04 06:14 /wordcount/output/_SUCCESS -rw-r--r-- 1 hadoop supergroup 39 2017-10-04 06:14 /wordcount/output/part-r-00000
继续查看part-r-00000文件内容:hadoop fs -cat /wordcount/output/part-r-00000 baby 1 hello 5 kitty 2 kugou 1 world 1
4.配置ssh免登陆
(1)从weekend110登入spark01出错
[hadoop@weekend110 ~]$ ssh spark01
ssh: Could not resolve hostname spark01: Temporary failure in name resolution
(2)解决办法:添加hosts
执行命令:sudo vi /etc/hosts 添加192.168.2.131 spark01
结果:再次执行命令:ssh spark01 ,成功登入(或者直接用命令: ssh 192.168.2.131)
(3)从weekend110到spark01无密登入配置
生成密钥对,并且指定加密算法指令:ssh-keygen -t rsa(按4个回车)
执行完这个命令后,在/home/hadoop/.shh下会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上: scp id_rsa.pub spark01:/home/hadoop/ (注释:scp 通过ssh协议远程拷贝到spark01上)
创建空文件夹: touch authorized_keys
修改文件夹权限:chmod 600 authorized_keys # -rw-------. 1 hadoop hadoop 0 Oct 4 23:34 authorized_keys
将公钥追加到文件authorized_keys里: cat ../id_rsa.pub >> ./authorized_keys
(4)从weekend110到weekend10无密登入配置
创建空文件夹: touch authorized_keys
修改文件夹权限:chmod 600 authorized_keys # -rw-------. 1 hadoop hadoop 0 Oct 4 23:34 authorized_keys
将/home/hadoop/.shh下的id_rsa.pub(公钥)追加到 authorized_keys:cat ./id_rsa.pub >> ./authorized_keys
查看文件内容: cat authorized_keys
检查是否能够无密登入:
[hadoop@weekend110 .ssh]$ ssh weekend110
Last login: Thu Oct 5 00:16:43 2017 from weekend110 #成功无密登入
(5)启动dfs、yarn
启动dfs: start-dfs.sh
验证:jps
启动yarn: satrt-yarn.sh
验证:jps
注释:ssh无密登陆机制.png

补充:停掉ssh服务:service sshd stop
5、补充:hdfs的实现机制

图hdsf的实现机制.png










 京公网安备 11010802041100号
京公网安备 11010802041100号