目录
需求场景:
架构设计:
端口号:
准备资源:
Linux版本:
准备Java环境
ElasticSearch:
下载安装
配置:
启动:
Zookeeper
下载安装:
配置:
启动:
Kafka
下载安装:
配置:
启动命令:
准备和调试:
Logstash:
下载安装:
配置:
logstash服务配置:
被监听的服务配置:
启动命令:
Kibana:
下载安装:
配置:
启动
操作:
案例:
Web服务代码改造:
集成Kafka:
pom.xml添加依赖:
添加kafka的配置:
利用切面捕获入库信息:
需要注意的细节:
目前已经运行了一个JavaWeb应用,需要能自定义收集http的request和response,做到报文可追溯,可统计,方便查询,同时不能对现有web服务的http请求造成影响。
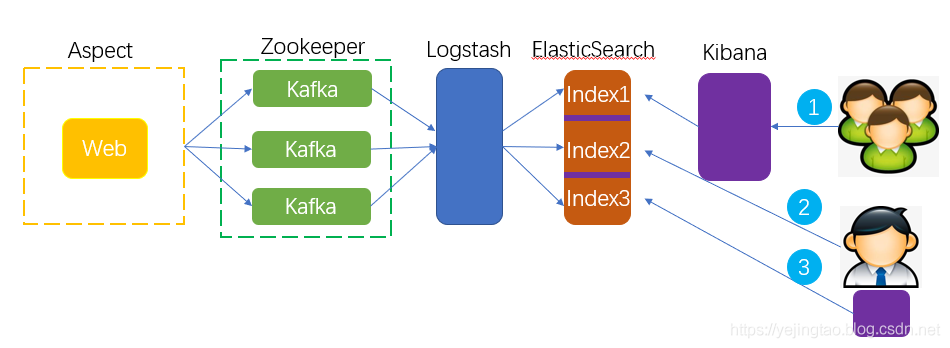
1 利用AOP获取controller层的reqeust和response,并根据自定义要求做Json序列化
2 AOP获取的内容发送到Kafka,利用MQ的特性,减少对http请求造成的延时
3 LogStash从Kafka中消费Json信息,对内容清洗后按照规则发送给不同的es索引
4 ElasticSearch存储内容
5 三种方式检索es中的内容:
第一种:在服务器中搭建Kibana,所有用户利用该Kibana来操作es;(推荐)
第二种:curl直接操作es
第三种:客户端本地安装Kibana,利用客户端Kibana来操作es
9200:ElasticSearch的端口
9092:Kafka的端口
2181:ZooKeeper的端口
5601: Kibana的端口
这些端口号是组建默认的端口,可以根据自己的需要进行配置,如果云平台有安全组限制或者实例中有防火墙的限制,需要打开它们。
几个控件可以分开安装,也可装在一台机器上,建议初期都在一台里,网络传输消耗少。
本篇重在介绍如何把它们串联起来,所有控件先只做单节点,而且这些控件集群配置相对都很简单,在以前的博客中都有介绍过。
最低配置:需要4核8G,或者两台2核4G的也可以。
AWS中最低是C4.xlarge 推荐C4.2xlarge
CentOS-7-x86_64-GenericCloud-1802(小版本号无要求,centos7即可)
Jdk:jdk-8u171-linux-x64.tar.gz(小版本号无要求,jdk8即可)
Centos用户,如果是新机器需要重设下密码:
$sudo passwd centos
Jdk:jdk-8u171-linux-x64.tar.gz
配置java环境
$vi ~/.bashrc
export JAVA_HOME=/opt/jdk/jdk1.8.0_171
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
$source ~/.bashrc
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.1.zip
$unzip elasticsearch-5.6.1.zip
最好安装一个中文插件(如果是纯英文场景可以跳过此步骤)
wget https://github.com/yejingtao/forblog/raw/master/ik/elasticsearch-analysis-ik-5.6.1.zip
中文插件的原因和使用方式:
https://blog.csdn.net/yejingtao703/article/details/78392902
涉及到的配置文件都在config下
1、elasticsearch.yml:elastic结点、集群的配置信息;
2、jvm.options:jvm的配置信息,里面找到默认启动内存是2G,最低可以改成512m
3、log4j2.properties:elastic的log的配置文件。
需要修改绑定地址,否则es不能被外部访问:
修改config 下的配置文件elasticsearch.yml,将#network.host: 192.168.0.1注释放开,同时修改成你对外的IP
$cd bin
$./elasticsearch
如果遇到这样的报错:
ERROR: [2] bootstrap checks failed
[1]: max file descriptors [4096] forelasticsearch process is too low, increase to at least [65536]
[2]: max virtual memory areas vm.max_map_count[65530] is too low, increase to at least [262144]
解决问题1:执行下命令ulimit -n 65536
解决问题2:需要修改/etc/sysctl.conf配置文件
echo "vm.max_map_count=262144">>/etc/sysctl.conf
sysctl –p//立刻生效
其中在解决ulimit -n 65536问题是被卡住了,原因是centos用户没有ulimit命令的权限。
解决方案:
$sudo vi /etc/security/limits.conf
在配置文件的最后添加6行:
centos soft nproc 16384
centos hard nproc 16384
centos soft nofile 65536
centos hard nofile 65536
centos soft memlock 4000000
centos hard memlock 4000000
保存退出后需要重新切换一次centos用户
$su – centos
在外网的浏览器中确认能访问到elasticSearch(http://ip:9200)就可以确定安装完毕
建议做为服务器应用将elasticSearch转为后台运行:
$nohup elasticsearch-5.6.1/bin/elasticsearch &
Zookeeper是使用Kafka的先决条件
$wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
$gunzip zookeeper-3.4.10.tar.gz
将/conf/下zoo_sample.cfg 重命名为 zoo.cfg
vim zoo.cfg
dataDir=/tmp/zookeeper (数据文件)
dataLogDir=/tmp/zookeeperlog (日志文件)
./bin/zkServer.sh start
2181是zk的默认端口,启动后可以telnet检查下是否启动成功(也可以不检查,因为zk启动失败的话,后面的kafka是不会启动成功的)
$wget http://mirror.bit.edu.cn/apache/kafka/2.1.1/kafka_2.11-2.1.1.tgz
$gunzip kafka_2.11-2.1.1.tgz
$vi conf/server.properties
#listeners=PLAINTEXT://:9092改成自己的地址
advertised.listeners=PLAINTEXT也要改成外网地址,深坑,否则外面的生产者解析不到kafka的地址。
$bin/kafka-server-start.sh config/server.properties
同理上线使用时后台运行
$nohup bin/kafka-server-start.sh config/server.properties &
检查Kafka是否启动成功,调用以下命令查询下kafka的topic
$bin/kafka-topics.sh --list --zookeeper {yourip}:2181
创建好topic,给接入代码使用
$bin/kafka-topics.sh --create --zookeeper {yourip}:2181 --replication-factor 1 --partitions 1 --topic httplog
像http日志收集这种应用场景,java代码只做生产者,可以直接用kafka自带的消费者来进行调试,不需要单独开发消费代码。
kafka消费者调测:
$bin/kafka-console-consumer.sh --bootstrap-server {yourip}:9092 --topic httplog
同理,kafka也自带生产者调测工具,这里不再介绍
$wget https://artifacts.elastic.co/downloads/logstash/logstash-5.6.3.zip
$unzip logstash-5.6.3.zip
配置文件在HOME/config下
修改logstash.yml
# Bind address for the metrics REST endpoint
#
# http.host: "127.0.0.1"
重新配置http.host
端口:
# Bind port for the metrics REST endpoint, this option also accept a range
# (9600-9700) and logstash will pick up the first available ports.
#
# http.port: 9600-9700
这里注意下就好,主要根据这个端口范围来关心logstash的死活,这里把logstash架在kafka和elasticsearch之间,我们不会通过端口去访问它。
随便一个位置添加一个启动配置文件logstash.conf,建议也是放在logstash的home目录下,内容如下:
input {
kafka {
bootstrap_servers => ["10.100.1.142:9092"]
client_id => "fwapi"
group_id => "fwapi"
auto_offset_reset => "latest"
consumer_threads => 5
topics => ["httplog"]
codec => json {
charset => "UTF-8"
}
}
}
filter {
json{
source => "message"
target => "message"
}
}
output {
elasticsearch{
hosts => ["10.100.1.142:9200"]
index => "httplog-%{+YYYY.MM.dd}"
timeout => 300
}
}
$bin/logstash -f logstash.conf
上生产时需要转到后台
$nohup bin/logstash -f logstash.conf &
https://www.elastic.co/downloads/kibana
下载时请注意Kibana版本要与elasticsearc版本一致,否则会有下面这种坑

所以对应上述es版本的kibana安装包是:
https://artifacts.elastic.co/downloads/kibana/kibana-5.6.1-linux-x86_64.tar.gz
修改config/kibana.yml
#elasticsearch.hosts: ["http://localhost:9200"]
改成自己elasticsearch的地址
#server.host: "localhost"
改成自己的kibana地址
$./kibana
上生产时需要后台运行
$ nohup ./kibana &
地址:http://hostname:5601/
Dev Tools里是curl的查询界面,
具体某一天中某一个接口的请求:GET httplog-2019.02.28/_search
如果按月查询:GET httplog-2019.02.*/_search
按年查询GET httplog-2019.*/_search
全量查询GET /_search
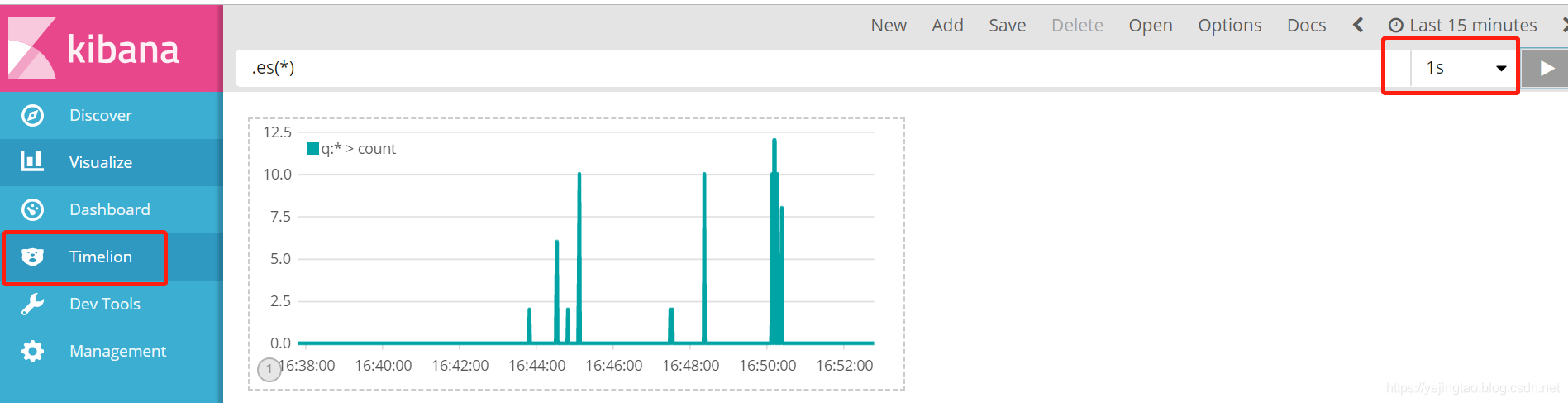
压力监控(QPS):
可以聚合和报表的类型:
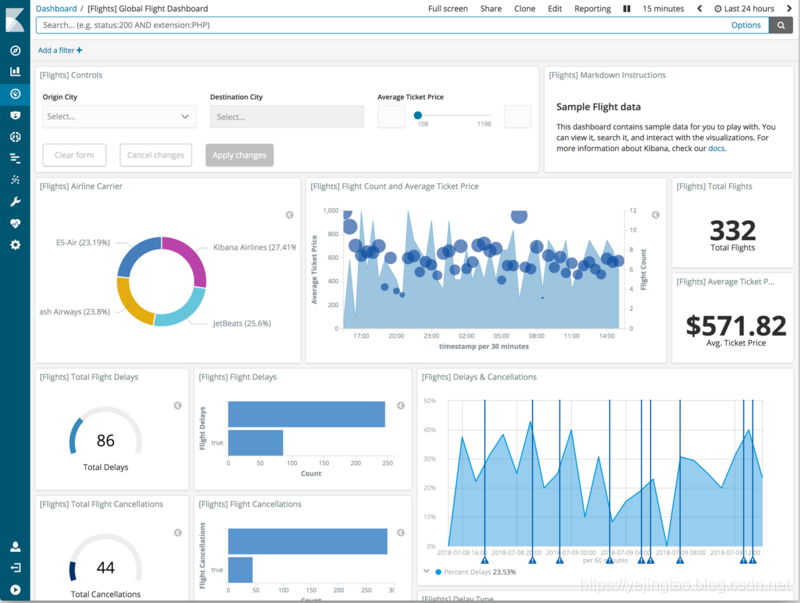
成品案例:
org.springframework.kafka
spring-kafka
spring.kafka.producer.bootstrap-servers=10.100.129.142:9092
spring.kafka.producer.retries=0
spring.kafka.producer.batch-size=4096
spring.kafka.producer.buffer-memory=40960
package com.fw.tester.config;
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
@Configuration
@EnableKafka
public class KafkaProducerConfig {
@Value("${spring.kafka.producer.bootstrap-servers}")
private String servers;
@Value("${spring.kafka.producer.retries}")
private int retries;
@Value("${spring.kafka.producer.batch-size}")
private int batchSize;
@Value("${spring.kafka.producer.buffer-memory}")
private int bufferMemory;
public Map producerConfigs() {
Map props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
//props.put(ProducerConfig.LINGER_MS_CONFIG, linger);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
public ProducerFactory producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate kafkaTemplate() {
return new KafkaTemplate(producerFactory());
}
}
package com.fw.tester.aspect;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.AfterReturning;
import org.aspectj.lang.annotation.AfterThrowing;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.core.annotation.Order;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaTemplate;
import com.alibaba.fastjson.JSON;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* Aspect for http log
*/
@Aspect
@Order(5)
@Component
@Slf4j
public class WebLogJsonAspect {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("${spring.kafka.enable}")
private boolean kafkaEnable;
ThreadLocal startTime = new ThreadLocal<>();
@Pointcut("execution(public * com.fw.tester.controller..*.*(..))")
public void webLog(){}
@Before("webLog()")
public void doBefore(JoinPoint joinPoint) throws Throwable {
startTime.set(System.currentTimeMillis());
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
LogRequest logRequest = new LogRequest(System.currentTimeMillis(), request.getRequestURL().toString(), request.getMethod(),
joinPoint.getSignature().getDeclaringTypeName() + "." + joinPoint.getSignature().getName(), JSON.toJSONString(joinPoint.getArgs()));
log.info(JSON.toJSONString(logRequest));
if(kafkaEnable) {
try {
kafkaTemplate.send("httplog", JSON.toJSONString(logRequest));
log.info("Send message to kafka successfully");
} catch (Exception e) {
log.error("Send message to kafka unsuccessfully", e);
e.printStackTrace();
}
}
}
@AfterReturning(returning = "ret", pointcut = "webLog()")
public void doAfterReturning(Object ret) throws Throwable {
HttpServletResponse respOnse= ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getResponse();
LogResponse logRespOnse= new LogResponse(startTime.get(), response.getStatus(), ret, System.currentTimeMillis() - startTime.get());
log.info(JSON.toJSONString(logResponse));
if(kafkaEnable) {
try {
kafkaTemplate.send("httplog", JSON.toJSONString(logResponse));
log.info("Send message to kafka successfully");
} catch (Exception e) {
log.error("Send message to kafka unsuccessfully", e);
e.printStackTrace();
}
}
}
@AfterThrowing(throwing="ex", pointcut = "webLog()")
public void doThrowing(Throwable ex){
LogResponse logRespOnse= new LogResponse(startTime.get(), HttpStatus.INTERNAL_SERVER_ERROR.value(), ex.getMessage(), System.currentTimeMillis() - startTime.get());
log.info(JSON.toJSONString(logResponse));
if(kafkaEnable) {
try {
kafkaTemplate.send("httplog", JSON.toJSONString(logResponse));
log.info("Send message to kafka successfully");
} catch (Exception e) {
log.error("Send message to kafka unsuccessfully", e);
e.printStackTrace();
}
}
}
@Data
@AllArgsConstructor
class LogRequest {
private long traceId;
private String url;
private String httpMethod;
private String classMethod;
private String args;
}
@Data
@AllArgsConstructor
class LogResponse {
private long traceId;
private int status;
private Object response;
private long spendTime;
}
}
完整的示例代码请见:https://github.com/yejingtao/fw-tester
在elasticsearch中尽量用“小索引”,利用Kibana的“大索引”做上层的封装,这样一旦出现问题方便索引的重建和恢复。
举例:
http日志每天都用新的索引来保存记录httplog-2019.03.02,在kibana中大索引配置成httplog-2019*,如果某一天因为新属性导致插入失败,只需要重建当天索引就好。









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
