写在前面
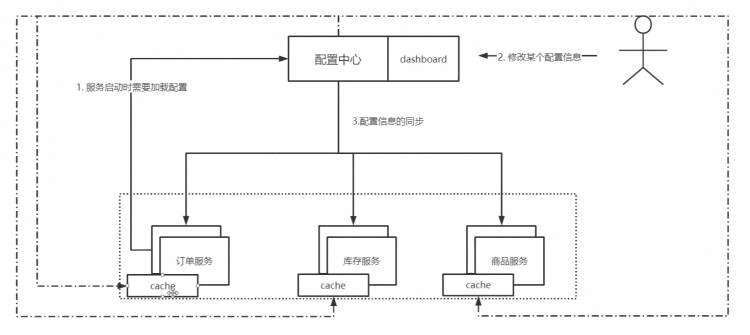
一个web app的实际使用场景中,有一些情景的交互要求,是记录用户的浏览状态的。最常见的就是在列表页进入详情页之后,再返回到列表页,用户希望返回到进入详情页之前的状态继续操作。但是有些使用场景,用户又是希望能够获取最新的数据,例如同级列表页之间切换的时候。
如此,针对上述两种使用场景,需要实现按需读取页面缓存。由于SPA应用的路由逻辑也是在前端实现的,因此可以在前端对路由的逻辑进行设置以实现所需效果。
使用技术
总体思路
keep-alive判断当前组件是否读取缓存的节点,在整个生命周期里面非常靠后,在afterEach之后,基本在组件实例创建之前。(因此在此之前对当前组件是否读取缓存进行处理都是可行的,我选择在全局前置守卫进行处理)
而判断当前组件是否缓存的节点,则早于组件的beforeRouteLeave钩子。
基于上述逻辑,本方案解决的逻辑是,对当前打开的页面进行判断,动态生成需要keepAlive的组件数组配置,对有可能需要缓存的先行进行缓存,然后在每次路由切换的时候,再进行判断,按需读取页面缓存。
具体实现
1. 使用include属性控制路由缓存
此处需要注意的是,include匹配首先检查组件自身的 name 选项,如果 name 选项不可用,则匹配它的局部注册名称 (父组件 components 选项的键值)。匿名组件不能被匹配。
但是vue-router的环境下,是没有局部注册名称的,只能为组件补全name属性。
因此,请务必给组件添加 name 选项,否则匿名组件将全部应用缓存。
2. 添加全局路由缓存配置
// store/index.js
const store = new vuex.Store({
state: {
// 缓存的路由列表
cachedRouteNames: [],
},
mutations: {
UPDATE_CACHEDROUTENAMES(state,{ action, route }) {
const methods = {
'add': () => {
state.cachedRouteNames.push(route)
},
'delete': () => {
state.cachedRouteNames.splice(state.cachedRouteNames.findIndex((e) => { return e === route}),1)
}
}
methods[action]()
}
}
})
3. 配置路由元信息,对需要缓存的路由进行配置
keepAlive表明路由需要被缓存,必须,否则不缓存
cacheWhenFromRoutes为数组,非必须,若为falsy值,则任何时候均缓存;若为空数组,则任何时候均不缓存
// router/index.js
{
path: '/productslist',
name: 'ProductsList',
component: ProductsList,
meta: {
keepAlive: true,
cacheWhenFromRoutes: ['ProductDetail'] // 此处配置的是路由的name
}
},
4. 配置全局前置守卫,按需读取缓存
// routeControl.js
// 需要缓存的路由名称数组
const cachedRouteNames = store.state.cachedRouteNames;
// 定义添加缓存组件name函数,设置的是组件的name
const addRoutes = (route) => {
const routeName = route.components.default.name
if (routeName && cachedRouteNames.indexOf(routeName) === -1) {
store.commit('UPDATE_CACHEDROUTENAMES', { action: 'add', route: routeName })
}
}
// 定义删除缓存组件name函数,设置的是组件的name
const deleteRoutes = (route) => {
const routeName = route.components.default.name
if (routeName && cachedRouteNames.indexOf(routeName) !== -1) {
store.commit('UPDATE_CACHEDROUTENAMES', { action: 'delete', route: routeName })
}
}
router.beforeEach((to, from, next) => {
// 处理缓存路由开始
// 在读取缓存之前,先对该组件是否读取缓存进行处理
to.matched.forEach((item, index) => {
const routes = item.meta.cacheWhenFromRoutes;
/**
* 此处有几种情况
* 1. 没有配置cacheWhenFromRoutes, 则一直缓存;
* 2. 配置了cacheWhenFromRoutes,但是首次打开此web app,则from.name为空,此时应该将该页面组件的name添加到缓存配置文件中
* 3. 配置了cacheWhenFromRoutes,from.name不为空,若命中cacheWhenFromRoutes,则添加该页面组件的name到缓存配置文件中,否则删除。
*
**/
if (item.meta.keepAlive && (!routes || (routes && (!from.name || routes.indexOf(from.name) !== -1)))) {
addRoutes(item)
} else {
deleteRoutes(item)
}
})
// 处理缓存路由结束
new Promise(( resolve, reject ) => {
// ..other codes
}).then( res => {
if ( res ) {
next(res)
} else {
next()
}
})
})
// 全局混入。此步骤的目的是在该组件被解析之后,若是属于需要缓存的组件,先将其添加到缓存配置中,进行缓存。
// 导航守卫的最后一个步骤就是调用 beforeRouteEnter 守卫中传给 next 的回调函数,此时整个组件已经被解析,DOM也已经更新。
Vue.mixin({
beforeRouteEnter(to, from, next) {
next(vm => {
to.matched.forEach((item) => {
const routeName = item.components.default.name
if (to.meta.keepAlive && routeName && cachedRouteNames.indexOf(routeName) === -1) {
store.commit('UPDATE_CACHEDROUTENAMES', { action: 'add', route: routeName })
}
})
})
},
})
写在最后
坑点
以上是实践过程中摸索出来的一种解决方案,我相信存在更加优雅高效的解决方式。如果你正好实践过相关方法,烦请指正,谢谢。
更多参考
github.com/vuejs/vue/i…
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。



![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有