作者:玄天战猫 | 来源:互联网 | 2023-09-25 23:34
我们都知道,链表的好处是插入和删除方便,但是遍历则比较慢。如果要找到链表最末尾的元素,那么需要查找时间复杂度是O(n)。
跳跃表就是为了解决这个问题而提出,跳跃表可以理解为在链表的基础上加上了多级索引。
为了保证插入的均衡以及查询的速率,跳跃表的新节点插入时,会计算一个随机的层数(不大于最大层数)。然后从该层逐步向最底层插入,当该层没有元素时,那么这个新的节点就是第一个元素。而如果该层已经有元素时,则在插入时会保证该层的全体元素整体有序。
插入的代码如下(其中MAXLEVEL是跳表的最大层数):
//在跳表内插入记录
void insert(SkipList *skipList, int key, int val) {Node *update[MAXLEVEL];int i=0;for(i=0;iheader;}int curLevel = getRandomLevel();Node *node = (Node*)malloc(sizeof(Node));node->level = curLevel;node->key = key;node->val = val;for(i=0;inext[i] = NULL;}for(i = curLevel - 1;i>=0;i--){if(update[i]->next[i] == NULL){update[i]->next[i] = node;}else{//找到一个链表当前层最后的,且小于它的Node *p = update[i];while(p->next[i] != NULL && p->next[i]->key next[i];}node->next[i] = p->next[i];p->next[i] = node;}}if(curLevel > skipList->level) {skipList->level = curLevel;}
}
具体演示一下插入过程(假设定义的跳表最大层数为2),插入的第一个元素是key:5,val:5(随机出的5的层数是2):
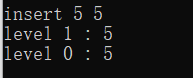
因为每一层都没有其他元素,所以每一层的指针都是指向元素5。
插入的第二个元素是key:2val:2(随机出的2的层数是2):

因为2是小于5的,所以它在header指针之后,而在5元素之前。
插入的第三个元素是key:3val:3(随机出的3的层数是1):

插入的第四个元素是key:4val:4(随机出的4的层数是1):

接下来看查找过程,从最顶层开始向下查找。当找到当前层最后一个小于等于待查找值的元素,如果元素的值已经等于待查找值了,直接返回即可;如果仅仅只是小于,那么就从这个元素的指针继续向下层查找。
查找代码如下:
//在跳表里查找记录
int find(SkipList *skipList, int key) {Node *p = skipList->header;for(int i=skipList->level-1;i>=0;i--){while(p->next[i] != NULL && p->next[i]->key <= key) {if(p->next[i]->key == key){printf("level %d:%d", i, p->next[i]->key);}else{printf("level %d:%d -> ", i, p->next[i]->key);}p = p->next[i];}if(p->key == key){printf("\n");return p->val;}}return -1;
}
例如查找4:

第二层只找到小于它的最后一个元素2,接着的5就已经比它大了。那么就由2的指针,继续到第一层找,那么就可以找到4。
如果是普通链表,找到4需要比对4次,而这里只用比对3次。
再看看查找5,由于第二层已经可以直接找到它了,那么实际上只比对了2次 。

可以看到,跳跃表的查找性能相比于普通链表已经有了很大提升。所以,它属于一种用空间来换时间的算法。
完整代码如下:
#include
#include
#include
#define MAXLEVEL 2typedef struct node{int key;int val;struct node *next[MAXLEVEL];int level;
}Node;typedef struct {int level;Node *header;
}SkipList;int getRandomLevel() {return rand()%MAXLEVEL+1;
}//在跳表内插入记录
void insert(SkipList *skipList, int key, int val) {Node *update[MAXLEVEL];int i=0;for(i=0;iheader;}int curLevel = getRandomLevel();Node *node = (Node*)malloc(sizeof(Node));node->level = curLevel;node->key = key;node->val = val;for(i=0;inext[i] = NULL;}for(i = curLevel - 1;i>=0;i--){if(update[i]->next[i] == NULL){update[i]->next[i] = node;}else{//找到一个链表当前层最后的,且小于它的Node *p = update[i];while(p->next[i] != NULL && p->next[i]->key next[i];}node->next[i] = p->next[i];p->next[i] = node;}}if(curLevel > skipList->level) {skipList->level = curLevel;}
}//在跳表里查找记录
int find(SkipList *skipList, int key) {Node *p = skipList->header;for(int i=skipList->level-1;i>=0;i--){while(p->next[i] != NULL && p->next[i]->key <= key) {if(p->next[i]->key == key){printf("level %d:%d", i, p->next[i]->key);}else{printf("level %d:%d -> ", i, p->next[i]->key);}p = p->next[i];}if(p->key == key){printf("\n");return p->val;}}return -1;
}//展示跳表构造
void display(SkipList *skipList) {int i;for(i=skipList->level-1;i>=0;i--){printf("level %d : ", i);Node *p = skipList->header->next[i];while(p != NULL){printf("%d ", p->key);p = p->next[i];}printf("\n");}
}int main() {//初始化,跳表头指针SkipList *skipList = (SkipList*)malloc(sizeof(SkipList));skipList->level = 0;Node header;header.key = INT_MIN;header.val = INT_MIN;int i=0;for(i=0;iheader = &header;insert(skipList, 5, 5);printf("\n");printf("insert 5 5 \n");display(skipList);insert(skipList, 2, 2);printf("\n");printf("insert 2 2 \n");display(skipList);insert(skipList, 3, 3);printf("\n");printf("insert 3 3 \n");display(skipList);insert(skipList, 4, 4);printf("\n");printf("insert 4 4 \n");display(skipList);printf("\n");printf("find val:%d\n", find(skipList,4));printf("find val:%d\n", find(skipList,5));free(skipList);return 1;
}







 京公网安备 11010802041100号
京公网安备 11010802041100号