本节涉及点:
在前面的三好学生问题中,学校改变了评三好的标准 —— 总分>= 95,即可当三好。计算总分公式不变 —— 总分 = 德*0.6+智*0.3+体*0.1
但学校没有公布这些规则,家长们希望通过神经网络计算出学校的上述规则
这个问题显然不是线性问题,也就是无法用一个类似 y = w*x + b 的公式来从输入数据获得结果
虽然总分和各项成绩是线性关系,但总分与是否评比上三好并不是线性关系,而是一个阶跃函数
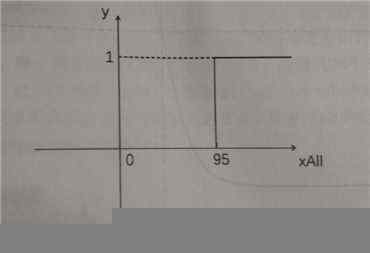
# 如果在一连串的线性关系中有一个非线性关系出现,整个问题都将成为非线性的问题
一、激活函数 sigmoid把评选结果 是不是三好学生 定义为 1 / 0
那么由总分 ——> 评选结果的过程 就是 0~100的数字得出1 或 0 的计算过程 ——> sidmoid 函数
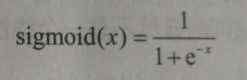 e 为自然底数
e 为自然底数
(1)sigmoid 函数
可以把任意数字变成 0 - 1 范围内的数字
在图中可以观察到,-5~5 的范围是个快速的从0 变1的过程,非常像这个问题出现的阶跃函数 ————> 常常用来进行 二分类
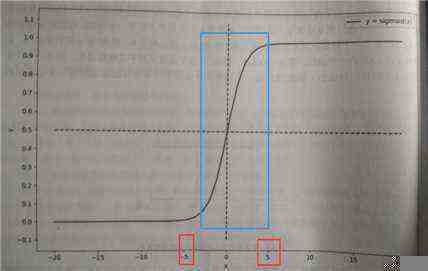
# 在神经网络中,像sigmoid 这种把线性化的关系转化为非线性化关系的函数叫做 激活函数
(2)使用sigmoid 函数后的神经网络模型
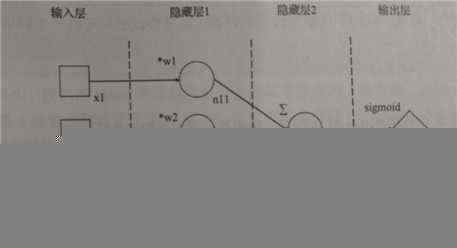
隐藏层中的节点 n11,n12,n13 分别接收来自输入层节点 x1 x2 x3的输入数据,与权重 w1 w2 w3 分别相乘后都送到 隐藏层 2 的节点 n2 ,n2将这些数据汇总求和后再 送到输出层,输出层节点将来自n2 的数据使用激活函数 sigmoid 处理后面作为神经网络最后输出的计算结果
import tensorflow as tf x = tf.placeholder(dtype=tf.float32) yTrain = tf.placeholder(dtype=tf.float32) w = tf.Variable(tf.zeros([3]),dtype=tf.float32) n1 = w* x n2 = tf.reduce_sum(n1) y = tf.nn.sigmoid(n2)
上面的代码中 使用了以向量来组织数据的简单的实现方法 x —— [x1,x2,x3]
输出层节点则是 调用了tf.nn.sigmoid() 函数
二、产生随机训练数据随机数:
import random random.seed() r = random.random() * 10 print(r) x = int (r) print(x)
6.999030147748621 6
random包 提供的函数 random 产生 [0,1) 范围内的随机小数
int (r) ———— 对小数r 向下取
计算机产生的随机数都是伪随机数,随机性并不好,最好运行函数 random.seed() 来产生新的 随机数种子
import random random.seed() xData = [int (random.random() * 101),int (random.random() * 101),int(random.random() * 101)] xAll = xData[0]* 0.6 + xData[1] * 0.3 + xData[2]*0.1 if xAll >= 95: yTrainData = 1 else: yTrainData = 0 print(xData) print(yTrainData)
我们用xData 来存放随机产生的某个学生的三个分数 ———— 这是一个 一维数组来存放的三维向量
xAll 用来存放 总分
接着 用条件判断语句生成目标值,满足 总分 >= 95 时为1, 否则为0
结果:
[52, 70, 7] 0
虽然该数据理论上是正确的,但一名学生一科7分,有点不正常,所以优化下
import random random.seed() xData = [int (random.random() * 41+60),int (random.random() *41+60),int(random.random() *41+60)] xAll = xData[0]* 0.6 + xData[1] * 0.3 + xData[2]*0.1 if xAll >= 95: yTrainData = 1 else: yTrainData = 0 print(xData) print(yTrainData)
产生随机数在 [60,100],是数据更合理
但符合三好学生的条件的数据太少,不利于神经网络的训练,所以更大概率的产生一些 符合三好学生调节的数据:
xData = [int (random.random() * 8+93),int (random.random() *8+93),int(random.random() *8+93)]
使数据介于[93,100]
但为了避免出现太多符合三好学生条件的数据,会交替使用这两种方法产生更平衡的训练数据
三、使用随机数据训练本段代码一共循环执行 5 轮,每一轮两次训练,第一次是 三好学生概率大的一些随机分数,第二次使用一般的随机分数
import tensorflow as tf import random random.seed() x = tf.placeholder(dtype=tf.float32) yTrain = tf.placeholder(dtype=tf.float32) w = tf.Variable(tf.zeros([3]), dtype=tf.float32) wn = tf.nn.softmax(w) n1 = wn * x n2 = tf.reduce_sum(n1) y = tf.nn.sigmoid(n2) loss = tf.abs(yTrain - y) optimizer = tf.train.RMSPropOptimizer(0.1) train = optimizer.minimize(loss) sess = tf.Session() sess.run(tf.global_variables_initializer()) for i in range(5): xData = [int(random.random() * 8 + 93), int(random.random() * 8 + 93), int(random.random() * 8 + 93)] xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1 if xAll >= 95: yTrainData = 1 else: yTrainData = 0 result = sess.run([train, x, yTrain, w, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData}) print(result) xData = [int(random.random() * 41 + 60), int(random.random() * 41 + 60), int(random.random() * 41 + 60)] xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1 if xAll >= 95: yTrainData = 1 else: yTrainData = 0 result = sess.run([train, x, yTrain, w, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData}) print(result)
[None, array([96., 98., 95.], dtype=float32), array(1., dtype=float32), array([0., 0., 0.], dtype=float32), 96.33334, 1.0, 0.0] [None, array([85., 91., 61.], dtype=float32), array(0., dtype=float32), array([0., 0., 0.], dtype=float32), 79.0, 1.0, 1.0] [None, array([95., 96., 94.], dtype=float32), array(1., dtype=float32), array([0., 0., 0.], dtype=float32), 95.0, 1.0, 0.0] [None, array([94., 87., 68.], dtype=float32), array(0., dtype=float32), array([0., 0., 0.], dtype=float32), 83.0, 1.0, 1.0] [None, array([99., 93., 95.], dtype=float32), array(1., dtype=float32), array([0., 0., 0.], dtype=float32), 95.66667, 1.0, 0.0] [None, array([98., 75., 63.], dtype=float32), array(0., dtype=float32), array([0., 0., 0.], dtype=float32), 78.66667, 1.0, 1.0] [None, array([99., 95., 95.], dtype=float32), array(1., dtype=float32), array([0., 0., 0.], dtype=float32), 96.33334, 1.0, 0.0] [None, array([83., 89., 74.], dtype=float32), array(0., dtype=float32), array([0., 0., 0.], dtype=float32), 82.0, 1.0, 1.0] [None, array([ 98., 100., 95.], dtype=float32), array(1., dtype=float32), array([0., 0., 0.], dtype=float32), 97.66667, 1.0, 0.0] [None, array([62., 79., 61.], dtype=float32), array(0., dtype=float32), array([0., 0., 0.], dtype=float32), 67.333336, 1.0, 1.0]

import tensorflow as tf import random random.seed() x = tf.placeholder(dtype=tf.float32) yTrain = tf.placeholder(dtype=tf.float32) w = tf.Variable(tf.zeros([3]), dtype=tf.float32) b = tf.Variable(80, dtype=tf.float32) wn = tf.nn.softmax(w) n1 = wn * x n2 = tf.reduce_sum(n1) - b y = tf.nn.sigmoid(n2) loss = tf.abs(yTrain - y) optimizer = tf.train.RMSPropOptimizer(0.1) train = optimizer.minimize(loss) sess = tf.Session() sess.run(tf.global_variables_initializer()) for i in range(500): xData = [int(random.random() * 8 + 93), int(random.random() * 8 + 93), int(random.random() * 8 + 93)] xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1 if xAll >= 95: yTrainData = 1 else: yTrainData = 0 result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData}) print(result) xData = [int(random.random() * 41 + 60), int(random.random() * 41 + 60), int(random.random() * 41 + 60)] xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1 if xAll >= 95: yTrainData = 1 else: yTrainData = 0 result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData}) print(result)
程序中,我们让 n2 在计算总分的 基础上 - b,目的是为了让 n2向[-5,5]这个区间范围靠拢。
根据前面代码的输出,我们随便预估了 b 的取值,80
输出:

参数w 和 b 的值明显变化,n2的值也在 0 附近跳动,误差也出现了小数上的调整,这说明神经网络的训练已经进入良性的循环了
尝试增加训练次数,并把输出结果信息中的w 改为 wn,最后几次的输出结果如下:
import tensorflow as tf import random random.seed() x = tf.placeholder(dtype=tf.float32) yTrain = tf.placeholder(dtype=tf.float32) w = tf.Variable(tf.zeros([3]), dtype=tf.float32) b = tf.Variable(80, dtype=tf.float32) wn = tf.nn.softmax(w) n1 = wn * x n2 = tf.reduce_sum(n1) - b y = tf.nn.sigmoid(n2) loss = tf.abs(yTrain - y) optimizer = tf.train.RMSPropOptimizer(0.1) train = optimizer.minimize(loss) sess = tf.Session() sess.run(tf.global_variables_initializer()) for i in range(500): xData = [int(random.random() * 8 + 93), int(random.random() * 8 + 93), int(random.random() * 8 + 93)] xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1 if xAll >= 95: yTrainData = 1 else: yTrainData = 0 result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData}) print(result) xData = [int(random.random() * 41 + 60), int(random.random() * 41 + 60), int(random.random() * 41 + 60)] xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1 if xAll >= 95: yTrainData = 1 else: yTrainData = 0 result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData}) print(result)

可以看到, 三项分数的权重变量wn 非常接近于期待值 [0.6,0.3,0.1] ,可变参数b 非常接近这个问题中判断是否是 三好学生的门槛 95 ——— 总分门槛95分,会有一个评选结果从 0-1的跳变,,而 sigmoid 函数的输入值在 [-5,5] 之间时,会有一个从 0 到 1 的巨变,那么总分减去偏移量 b 就可以得到引起模型输出结果巨变的数值,显然可以看出,偏移量b 为 95
即b 的值为95左右时,优化器可以“感受到” 调整可变参数 w 后对输出结果的影响,因而能够有效的调整可变参数,使误差越来越小
b 为啥不等于95? ———— sigmoid函数比较不是从0直接跳变成1,是连续的,这个渐变的过程中,输出的数值会导致优化器判断出现误判,这是正常的。可以通过增加大量在这个边界附近的训练数据,可以有效的减少误差
四、进阶:批量生产随机训练数据在训练前 一次性 批量生成 一批训练数据以备训练
import tensorflow as tf import random import numpy as np random.seed() rowCount = 5 #np.full 生成一个多维数组,并用预定的值来填充 xData = np.full(shape=(rowCount, 3), fill_value=0, dtype=np.float32)#生成了一个形态为 (rowCount,3)的多维数组,并全部用0填充 #rowCount 是准备生成的训练数据的条数 yTrainData = np.full(shape=rowCount, fill_value=0, dtype=np.float32) goodCount = 0#符合三好学生条件的数据的个数 # 生成随机训练数据的循环 for i in range(rowCount): xData[i] = [int(random.random() * 11 + 90), int(random.random() * 11 + 90), int(random.random() * 11 + 90)] xAll = xData[i][0] * 0.6 + xData[i][1] * 0.3 + xData[i][2] * 0.1 if xAll >= 95: yTrainData[i] = 1 goodCount = goodCount + 1 else: yTrainData[i] = 0 print("xData=%s" % xData) print("yTrainData=%s" % yTrainData) print("goodCount=%d" % goodCount) x = tf.placeholder(dtype=tf.float32) yTrain = tf.placeholder(dtype=tf.float32) w = tf.Variable(tf.zeros([3]), dtype=tf.float32) b = tf.Variable(80, dtype=tf.float32) wn = tf.nn.softmax(w) n1 = wn * x n2 = tf.reduce_sum(n1) - b y = tf.nn.sigmoid(n2) loss = tf.abs(yTrain - y) optimizer = tf.train.RMSPropOptimizer(0.1) train = optimizer.minimize(loss) sess = tf.Session() sess.run(tf.global_variables_initializer()) for i in range(2): for j in range(rowCount): result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: xData[j], yTrain: yTrainData[j]}) print(result) #最后,在训练的时候,每一轮训练会训练rowCount 次,也就是5次,每次训练会把 xData yTrainData 中对应小标序号的数据“喂”给神经网络
结果如下:
xData=[[ 96. 90. 97.] [ 95. 100. 98.] [ 97. 91. 94.] [ 96. 92. 95.] [100. 97. 100.]] yTrainData=[0. 1. 0. 0. 1.] goodCount=2 [None, array([96., 90., 97.], dtype=float32), array(0., dtype=float32), array([0.33333334, 0.33333334, 0.33333334], dtype=float32), 80.0, 14.333336, 0.9999994, 0.9999994] [None, array([ 95., 100., 98.], dtype=float32), array(1., dtype=float32), array([0.33333334, 0.33333337, 0.33333334], dtype=float32), 80.0, 17.666672, 1.0, 0.0] [None, array([97., 91., 94.], dtype=float32), array(0., dtype=float32), array([0.33333334, 0.33333337, 0.33333334], dtype=float32), 80.0, 14.000008, 0.99999917, 0.99999917] [None, array([96., 92., 95.], dtype=float32), array(0., dtype=float32), array([0.33333328, 0.33333337, 0.33333328], dtype=float32), 80.0, 14.333328, 0.9999994, 0.9999994] [None, array([100., 97., 100.], dtype=float32), array(1., dtype=float32), array([0.33333325, 0.3333334 , 0.3333333 ], dtype=float32), 80.0, 19.0, 1.0, 0.0] [None, array([96., 90., 97.], dtype=float32), array(0., dtype=float32), array([0.33333325, 0.3333334 , 0.3333333 ], dtype=float32), 80.0, 14.333328, 0.9999994, 0.9999994] [None, array([ 95., 100., 98.], dtype=float32), array(1., dtype=float32), array([0.33333325, 0.33333346, 0.33333328], dtype=float32), 80.0, 17.666672, 1.0, 0.0] [None, array([97., 91., 94.], dtype=float32), array(0., dtype=float32), array([0.33333325, 0.33333346, 0.33333328], dtype=float32), 80.0, 14.0, 0.99999917, 0.99999917] [None, array([96., 92., 95.], dtype=float32), array(0., dtype=float32), array([0.33333322, 0.3333335 , 0.33333328], dtype=float32), 80.0, 14.333336, 0.9999994, 0.9999994] [None, array([100., 97., 100.], dtype=float32), array(1., dtype=float32), array([0.3333332 , 0.33333352, 0.33333328], dtype=float32), 80.0, 19.0, 1.0, 0.0]

随时生成数据的方法能够最大限度地提高神经网络训练的覆盖范围(因为每一次 训练都是使用新产生的随机数据),进而最大限度地提高它的准确性,缺点是训练速度相对较慢;
一次性生成一批随机数据的方法则反之, 训练速度会很快,因为每轮训练都是同一批数据, 神经网络中的参数可以很快地被调节到合适的取值,但是这样训练出来的神经网络会比较“依赖”于这批数据,换一批数据时 会发现准确度明显下降
TensorFlow 用神经网络解决非线性问题







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有