作者:无敌BUG | 来源:互联网 | 2023-02-01 13:01
这篇文章主要讲解了“TVM编译器的介绍及用法”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“TVM编译器的介绍及用法”吧!
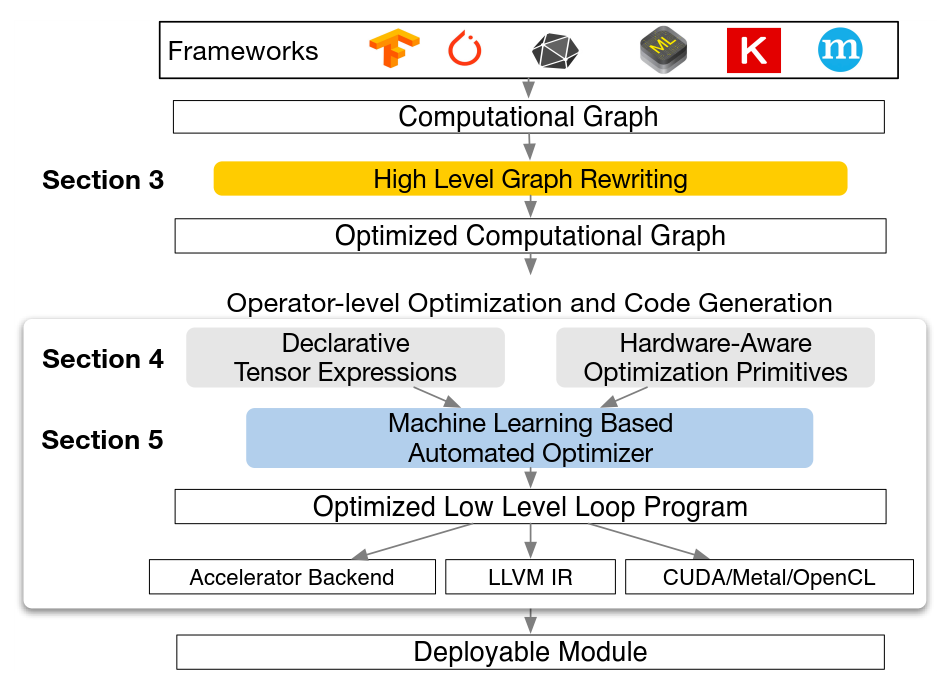
TVM是一个端到端的指令生成器。它从深度学习框架中接收模型输入,然后进行图的转化和基本的优化,最后生成指令完成到硬件的部署。整个架构是基于图描述结构,不论是对指令的优化还是指令生成,一个图结构清晰的描述了数据流方向,操作之间的依赖关系等。基于机器学习的优化器是优化过程中的重点,指令空间很大,通过优化函数来寻找最优值是一个很合理的想法。它的主要特点如下:
1) 基于GPU、TPU等硬件结构,将张量运算作为一个基本的算符,通过把一个深度学习网络描述成图结构来抽象出数据计算流程。在这样的图结构基础上,更方便记性优化。同时能够有更好的向上向下兼容性,同时支持多种深度学习框架和硬件架构。
2) 巨大的优化搜索空间。在优化图结构方面,其不再局限于通过某一种方式,而是通过机器学习方法来搜索可能的空间来最大化部署效率。这种方式虽然会导致编译器较大的计算量,但是更加通用。
TVM提供了一个非常简单的端到端用户接口,通过调用TVM的API可以很方便的进行硬件部署。比如:
以上就是将Keras的模型输入到TVM,指定部署的硬件GPU,然后进行优化和代码生成。
TVM也提供了Java、C++和Python界面供用户调用。
图结构是大多数深度学习框架中普遍采用的描述方式。这种图是一种高层次的描述,将一个张量运算用一个算符描述,而不是拆分的更细。这样更有利于优化,而且也符合GPU、TPU的硬件架构,在这些芯片中计算核算力很大,通常可以完成一个较大的计算,比如卷积、矩阵运算等。以下是一个卷积计算的例子,整个计算图包含了2D卷积、ReLu,dense、softmas等。这样的图结构也正好符合FPGA加速器的结构,在FPGA中也是用一个计算核来专门计算某个大的计算。TVM图中节点描述一个张量数据或者算符,而边表示了不同计算的依赖关系。
基于图结构,TVM采用了很多图优化策略。包括算符融合,将可以在硬件上用一个算符完成的多个连续运算合并;常量折叠,将可以预先计算的数据放在编译器中完成,减少硬件计算;存储规划,预先为中间数据分配存储空间来储存中间值,避免中间数据无法存储在片上而增加片外存储开销;数据规划,重新排列数据有利于硬件计算。
1) 算符融合
TVM中将运算划分为4种:1对1运算,比如加法、点乘;降运算,比如累加;复杂运算,比如2D卷积,融合了乘法和累加;不透明的,比如分类、数据排列等,这些不能被融合。算符融合可以减少存储开销,实现pipeline,特别是在FPGA中更有利。比如我们目前的项目中是开发一款通用RNN架构IP,其中涉及到矩阵乘法,加法。其中加法就可以融合到矩阵乘中,这样就减少了单独加法模块计算开销以及读写cache开销。
2) 数据规划
以我们XRNN来说,片上有一个矩阵运算阵列,由于阵列大小固定,一次计算矩阵大小也是固定的。比如计算一个32x32对应32x1的矩阵向量乘法,那么就要求权重和向量必须要按照32倍数进行对齐,这就需要对权重数据等进行规划。
TVM中使用的张量描述语言是透明的,可以根据硬件需要进行修改。这样更加灵活和有利于进行优化。但是这样可能增加了编译器优化的复杂性。TVM描述例子如下:
描述算符中包含结果大小,计算方式。但是这其中没有涉及到循环结构和更多数据操作细节。TVM采用了Halide思想,通过使用schedule来对张量计算进行等价变换,从中计算出执行效率最高的schedule结构。整个schedule流程如下图:
从中可以看出,TVM除了采用了Halide的schedule方式外,还增加了三种针对GPU和TPU的schedule方式:specile memory scope,tensorization,latency hiding。这些schedule方式可以对一个张量运算进行等价变换,产生多种代码结构,从中选择出最有利于硬件执行的代码结构。
并行计算是提高硬件执行效率的重要一步,因为诸如卷积、矩阵计算等都是大量的可以并发进行的计算,如何优化并行结构对改善硬件性能很关键。在这里需要考虑两点问题:一个是并行度,另外一个是数据共享。如果数据不共享那么就会增加数据读写消耗。而尽量利用可共享数据,则需要尽心设计一个计算结构。
TVM提出了memory scope的概念,其将数据计算进行可并行和不可并行分类,对于可以并行计算的,就可以使用多线程来并行计算,而不可并行,则需要等待被依赖数据计算完成。比如一个矩阵乘法例子:
在XRNN中也会遇到类似的问题,对于不同的计算比如矩阵乘法和激活函数,如果没有依赖的话,就是可以并行执行的。
在FPGA中读写cache或者external ddr也是一笔开销。如何将存储读写开销降低也有利于提高硬件执行效率。比如在我们的XRNN中,save数据到ddr会消耗很多时间,而这个数据下一次又会被利用,同时又增加了load的时间。如果将数据缓存到片上,那么就减少了load和save开销。还有比如片上cache也会来回读写数据,如果可以将一个计算完成的数据直接送给下一个计算核,实现流水,那么读写cache开销也节省了。
对于隐藏存储读写开销还有一种方法,在下一次计算开始前而这一次计算正在进行的时候,就进行片外数据加载,就将加载和计算重合了,减少额外加载消耗的时间。
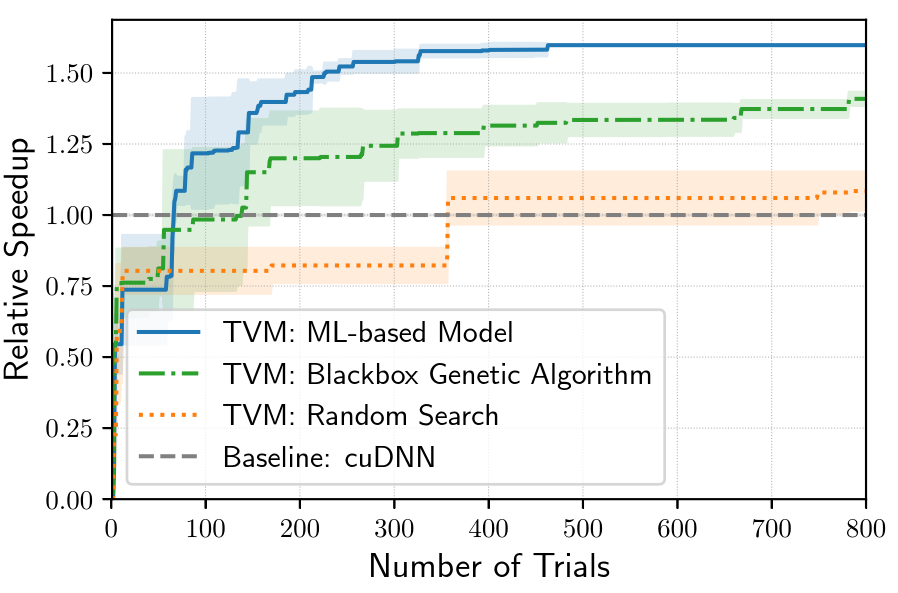
TVM在丰富的schedule方式基础上,提出了一个机器学习模型来寻找最优化的schedule结构。其包含两部分:一部分是基于schedule方式产生所有可能的计算结构;另外一个是机器学习代驾模型来预测性能。
Schedule空间是巨大的,它可能产生很多种计算流结构,而对其中进行探索,找到最合适的结构。这会产生大量的计算。不过在我们的XRNN结构中,因为受到硬件内核的限制,还是可以对空间进行缩减的。只采用最可能影响性能schedule方式。比如矩阵乘、加法、点乘、激活这些不同的计算可以进行并发和非并发安排,这样的空间相对小,有利于加速编译器生成工作。
机器学习代价模型主要考虑了不同操作的延时来预测性能:存储访问方式,数据重利用,pipeline等。TVM中对代价函数的求解不是通过随机统计方式,而是使用实时的配置数据进行训练,周期性更替代码结构。人为的探寻更合理的优化结构,然后提供给模型,让其不断更替。这种方式避免了探索大量schedule空间的时间消耗,同时也能更接近于实际情况。
以上简要介绍了TVM的整体架构和基本方法,其实还挺符合FPGA加速硬件结构的。很多方法还是可以借用的。而且TVM是一个兼容更广的编译器架构,针对我们自身的FPGA特性,也会有很多不一样的设计。
感谢各位的阅读,以上就是“TVM编译器的介绍及用法”的内容了,经过本文的学习后,相信大家对TVM编译器的介绍及用法这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程笔记,小编将为大家推送更多相关知识点的文章,欢迎关注!














 京公网安备 11010802041100号
京公网安备 11010802041100号