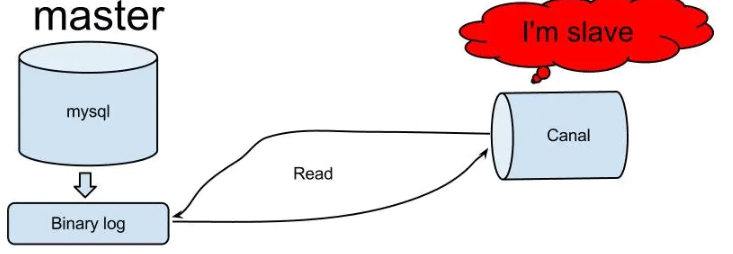
在 MySQL 配置文件 my.cnf 设置如下信息:
[mysqld]
# 打开binlog
log-bin=mysql-bin
# 选择ROW(行)模式
binlog-format=ROW
# 配置MySQL replaction需要定义,不要和canal的slaveId重复
server_id=1
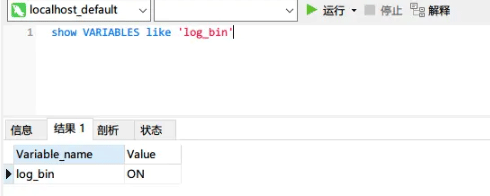
改了配置文件之后,重启 MySQL,使用命令查看是否打开 binlog 模式:
SHOW VARIABLES LIKE 'log_bin';
查看 binlog 日志文件列表:SHOW BINARY LOGS;
查看当前正在写入的 binlog 文件:SHOW MASTER STATUS; 记录文件名 File 和 Position 值。
详细配置可以参考:
conf\example\instance.properties
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0 //每个instance都会伪装成一个mysql slave , 此id对于canal前端的Mysql实例而言,必须是唯一的,但是同一个Canal中相同的instance,此slaveld应该一样
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=127.0.0.1:3306 //需要连接的数据库地址及端口
canal.instance.master.journal.name= //需要读取的起始的binlog文件
canal.instance.master.position= //需要读取的起始的binlog文件的偏移量
canal.instance.master.timestamp= //需要读取的起始的binlog的时间戳
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true //v1.0.25版本新增,是否开启table meta的时间序列版本记录功能
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb //v1.0.25版本新增,table meta的时间序列版本的本地存储路径,默认为instance目录
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal //数据库账号
canal.instance.dbPassword=canal //数据库密码
canal.instance.cOnnectionCharset= UTF-8 //数据库解析编码格式
canal.instance.defaultDatabaseName =test //数据库连接时默认schema
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..* //mysql 数据解析关注的表,Perl正则表达式.
# table black regex
canal.instance.filter.black.regex= //canal将会过滤那些不符合要求的table,这些table的数据将不会被解析和传送
#################################################
conf\canal.properties
#################################################
######### common argument #############
#################################################
canal.id= 1 #每个canal server实例的唯一标识
canal.ip= #canal server绑定的本地IP信息,如果不配置,默认选择一个本机IP进行,
canal.port=11111 #canal server提供socket tcp服务的端口
canal.metrics.pull.port=11112
canal.zkServers= #canal server链接zookeeper集群的链接信息
# flush data to zk
canal.zookeeper.flush.period = 1000 #canal持久化数据到zookeeper上的更新频率,单位毫秒
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = tcp
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir} #canal持久化数据到file上的目录
canal.file.flush.period = 1000 #canal持久化数据到file上的更新频率,单位毫秒
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384 #canal内存store中可缓存buffer记录数,需要为2的指数
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024 # 内存记录的单位大小,默认1KB,和buffer.size组合决定最终的内存使用大小
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE #canal内存store中数据缓存模式
1. ITEMSIZE : 根据buffer.size进行限制,只限制记录的数量
2. MEMSIZE : 根据buffer.size * buffer.memunit的大小,限制缓存记录的大小
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false #是否开启心跳检查
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1 #心跳检查sql
canal.instance.detecting.interval.time = 3 #心跳检查频率,单位秒
canal.instance.detecting.retry.threshold = 3 #心跳检查失败重试次数
##非常注意:interval.time * retry.threshold值,应该参考既往DBA同学对数据库的故障恢复时间,
##“太短”会导致集群运行态角色“多跳”;“太长”失去了活性检测的意义,导致集群的敏感度降低,Consumer断路可能性增加。
canal.instance.detecting.heartbeatHaEnable = false #心跳检查失败后,是否开启自动mysql自动切换
#说明:比如心跳检查失败超过阀值后,如果该配置为true,canal就会自动链到mysql备库获取binlog数据 false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024 # 最大事务完整解析的长度支持超过该长度后,一个事务可能会被拆分成多次提交到canal store中,无法保证事务的完整可见性
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSecOnds= 60 #canal发生mysql切换时,在新的mysql库上查找 binlog时需要往前查找的时间,单位秒
说明:mysql主备库可能存在解析延迟或者时钟不统一,需要回退一段时间,保证数据不丢
# network config
canal.instance.network.receiveBufferSize = 16384 #网络链接参数,SocketOptions.SO_RCVBUF
canal.instance.network.sendBufferSize = 16384 #网络链接参数,SocketOptions.SO_SNDBUF
canal.instance.network.soTimeout = 30 #网络链接参数,SocketOptions.SO_TIMEOUT
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false #ddl语句是否隔离发送,开启隔离可保证每次只返回发送一条ddl数据,不和其他dml语句混合返回.(otter ddl同步使用)
canal.instance.filter.query.dml = false #是否忽略DML的query语句,比如insert/update/delete table.(mysql5.6的ROW模式可以包含statement模式的query记录)
canal.instance.filter.query.ddl = false #是否忽略DDL的query语句,比如create table/alater table/drop table/rename table/create index/drop index. (目前支持的ddl类型主要为table级别的操作,create databases/trigger/procedure暂时划分为dcl类型)
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info //关于时间序列版本
canal.instance.tsdb.enable=true
canal.instance.tsdb.dir=${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url=jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername=canal
canal.instance.tsdb.dbPassword=canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval=24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire=360
# rds oss binlog account
canal.instance.rds.accesskey =
canal.instance.rds.secretkey =
#################################################
######### destinations #############
#################################################
canal.destinatiOns= example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true #开启instance自动扫描
如果配置为true,canal.conf.dir目录下的instance配置变化会自动触发:
a. instance目录新增: 触发instance配置载入,lazy为true时则自动启动
b. instance目录删除:卸载对应instance配置,如已启动则进行关闭
c. instance.properties文件变化:reload instance配置,如已启动自动进行重启操作
canal.auto.scan.interval = 5 #instance自动扫描的间隔时间,单位秒
canal.instance.tsdb.spring.xml=classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml=classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring #instance管理模式,Production级别我们要求使用spring
canal.instance.global.lazy = false #全局lazy模式
#canal.instance.global.manager.address = 127.0.0.1:1099 #全局的manager配置方式的链接信息
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml #全局的spring配置方式的组件文件
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
1)canal.deployer-1.1.5\conf\canal.properties 进行全局配置,可以修改 IP、端口号或实例
# 默认有一个 example,需要增加实例的可以配置
canal.destinatiOns= example
2)canal.deployer-1.1.5\conf\example\instance.properties 进行局部实例配置,可以修改数据库账号和密码、数据库表名、binlog 文件名和 position 等
# 没有改变的就没有贴出来,注意 MySQL 的用户名和密码
canal.instance.master.address=192.168.58.131:3306
# username/password
canal.instance.dbUsername=test
canal.instance.dbPassword=liubihao
canal.instance.cOnnectionCharset= UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
ysql 数据解析m关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
bin/start.sh 启动服务(Windows 系统为 bin/start.bat)
package org.nwpu.atcss.util;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import org.springframework.stereotype.Component;
import java.util.List;
import java.net.InetSocketAddress;
@Component
public class CanalClient {
private static void printEntries(List
for (Entry entry : entries) {
if (entry.getEntryType() != EntryType.ROWDATA) {
continue;
}
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
EventType eventType = rowChange.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));
for (RowData rowData : rowChange.getRowDatasList()) {
switch (rowChange.getEventType()) {
case INSERT:
System.out.println("INSERT ");
printColumns(rowData.getAfterColumnsList());
break;
case UPDATE:
System.out.println("UPDATE ");
printColumns(rowData.getAfterColumnsList());
break;
case DELETE:
System.out.println("DELETE ");
printColumns(rowData.getBeforeColumnsList());
break;
default:
break;
}
}
}
}
private static void printColumns(List
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
public static void main(String[] args) throws Exception {
// hostname, port, destination, username, password
CanalConnector cOnnector= CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
try {
connector.connect();
// 监听的表,格式为数据库.表名,数据库.表名
connector.subscribe(".*\\..*");
connector.rollback();
while (true) {
Message message = connector.getWithoutAck(100); // 获取指定数量的数据
long batchId = message.getId();
if (batchId == -1 || message.getEntries().isEmpty()) {
Thread.sleep(1000);
continue;
}
// System.out.println(message.getEntries());
printEntries(message.getEntries());
connector.ack(batchId); // 提交确认,消费成功,通知server删除数据
// connector.rollback(batchId);// 处理失败, 回滚数据,后续重新获取数据
}
} catch (Exception e) {
System.out.println("Something Error.");
} finally {
connector.disconnect();
}
}
}
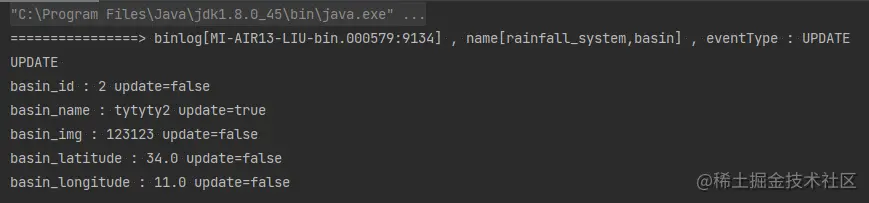
启动 CanalClient.java;
修改本地数据库内容之后,控制台成功监听并报告更新信息。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有