本文主要总结Spark及其生态圈,包括spark概述,产生背景,特点,以及与Hadoop的差异等,希望读者能从概念层面对spark有一个直观的认识。
Spark概述及特点
Apache Spark™ is a unified analytics engine for large-scale data processing.
这是来自Spark官网的描述(http://spark.apache.org/)。我们可以看到Spark是对大规模数据处理的一个统一分析引擎。有一种说法是:Spark给Hadoop这头大象插上了翅膀,足以看出Spark处理速度之快。Spark官网中,概括了Spark的几个特点:
1. Speed:执行速度很快,无论是在批处理还是流处理中都很快。官网指出逻辑回归使用hadoop(指的是MapReduce作业)执行需要110秒,使用spark执行只需要0.9秒。执行快的原因有:①spark使用了一种DAG执行引擎,能提供基于内存的计算,相比Hadoop对磁盘读写要快很多。②MapReduce中的Map作业和Reduce都是基于进程的,而进程的启动和销毁都有一定的开销。spark中作业是基于线程池的,任务启动的开销要比Hadoop快。
2. Ease of Use:易用性。主要体现在①Spark支持Java,Scala,Python,R,SQL等多种语言,便于我们选择自己熟悉的语言进行应用开发。②Spark提供了80多种高级别的算子,比起MapReduce中仅有的map和reduce操作更广泛,例如join,groupby等,也方便了我们进行应用开发。③Spark还支持交互式的命令行操作。而MapReduce需要写完之后打包再运行,代码量大,步骤繁琐。
3. Generality:通用性。Spark之上有不同的子框架用于处理不同的业务场景,如下图所示。这样降低了环境搭建成本,运维成本和学习成本。可以说是一栈式解决多种场景问题。
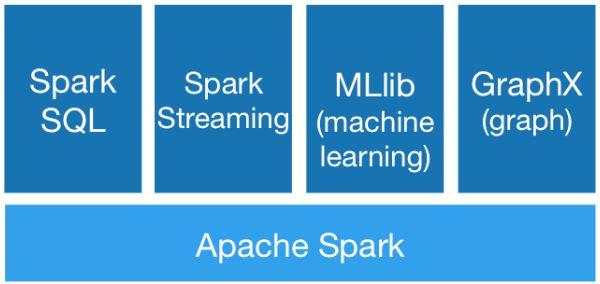
4. Runs Everywhere:Spark可以有Hadoop(yarn),Mesos,standalone,Kubernetes等多种运行模式。它还可以访问多种数据源,例如HDFS,Cassandra,HBase,Hive等,这样就为在现有的复杂多样的生产环境中使用spark提供了无限可能。
spark的产生背景
1.MapReduce的局限性:
① 代码繁琐。拿wordcount举例,使用MapReduce实现,需要我们自己开发map函数和reduce函数,并进行打包部署运行,代码量大,步骤繁琐,一单出错就需要重新提交。
② MapReduce只能够支持map和reduce方法,对于像Join,group by等的操作的开发比较繁琐。
③执行效率不够高,原因主要有:
map阶段的结果写入磁盘,reduce阶段再从磁盘上读取相应的数据进行有关计算,中间有磁盘参与的过程。
每一个作业是以进程(一个JVM)的方式,运行启动和销毁的成本很高。
数据交互通过磁盘进行,不能充分发挥集群的作用。
不适合迭代多次(如机器学习和图计算的场景),交互式学习(如使用命令行操作的场景),流式的处理(MapReduce处理的数据是静态不能变化的,不能处理流式处理)的场景。
2.框架多样化
在spark之前,有很多框架用于处理不同的任务。主要可以分为以下几种:
① 批处理(或者称之为离线处理)框架,如MapReduce、Hive、Pig。
② 流式处理(或者称为实时处理)框架,如Storm,JStorm。
③ 交互式计算计算,如Impala
如果要进行不同场景的业务处理,则就需要借助不同的框架。如果以上三种都涉及,就要搭建多个集群,这样的成本是很高的:包括对于框架的学习成本以及对实际环境的运维成本。
而spark能够完成以上所有框架可以做的事情。较好的解决了框架多样性的问题。能够完成批处理,流式处理,交互式处理等。spark包含的组件有:Spark SQL处理SQL的场景(离线处理),MLlib用于进行机器学习,Graphx用作图计算,Spark Streaming 用来进行流式处理。
spark生态对比Hadoop生态
关于Hadoop 生态系统的各个组件我们在前面文章中提到过,可以参考Hadoop基础知识总结中关于Hadoop生态系统的描述。
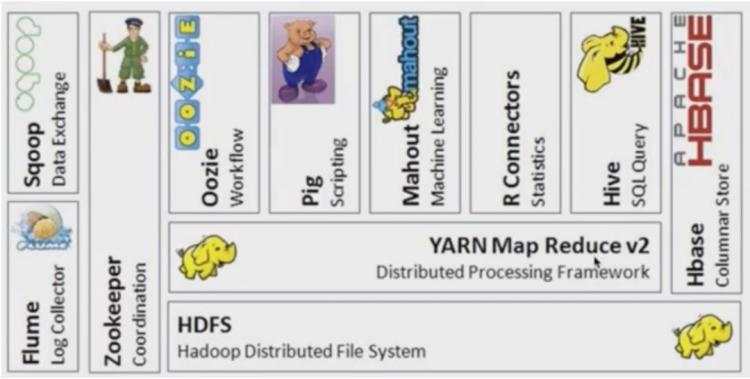
我们来看一下spark生态系统的架构,可以简写为BDAS,其全称是Berkeley Data Analytics Stack,即伯克利数据分析栈,如下图所示,图片来源:
https://yq.aliyun.com/articles/371357

从下往上看,各个组件的作用如下:
Mesos:分布式资源管理和调度框架,和Yarn类似。
HDFS:分布式文件存储系统。它是外部的相关系统,严格意义上不属于BDAS。
tachyan:后来改名为alpha,是一个分布式内存文件系统,使得我们的数据可以存储在内存中。
spark:即:spark core。基于内存优化的执行引擎,支持多种语言如Java,Python,Scala的编程API。
spark之上有不同的子模块用来满足不同的应用场景:Spark Streaming 用来做流处理。GraphX用于做图计算,MLlib用来做机器学习,Spark SQL(前身是Shark)用于支持SQL的查询。
storm和spark是没有关系的(外部系统),它是用来做流处理的框架,但是spark内部已经有了spark streaming可以用于做流处理,安装成本和学习成本相对都小很多。
BlinkDB:用于在海量数据之上运行交互式SQL查询的大规模并行查询引擎,通过牺牲数据的精度提高查询的响应时间。
spark与Hadoop的对比
对比1:hadoop生态系统与Spark BDAS 的对比,如下表所示。

批处理的场景:Hadoop生态系统中我们只能使用MapReduce,Spark中我们可以使用RDD以及相应的编程语言。
SQL查询的场景:Hadoop中可以使用Hive,Spark中我们可以使用Spark SQL,二者在使用上具有相当大的相似性。
流处理的场景:Hadoop生态系统通常使用kafka+storm,spark中使用的是 spark streaming,它也可以整合kafka使用。
机器学习的场景:Hadoop生态中使用mahout,但是目前不对MapReduce更新了,spark中则是单独的MLlib模块。
实时数据查询:Hadoop生态系统中使用Hbase等NoSQL数据库,而spark中虽然没有专门的组件,但是也能够使用spark core的API处理NoSQL查询的场景。spark是一个快速的分布式计算框架,所以没有提供存储的组件,但可以访问多种数据源。
对比2:Hadoop和Spark内部构成的对比

对比3:MapReduce 与Spark 的对比

如上图所示:
MapReduce执行时,从HDFS读取数据,结果写入到HDFS,下一个作业再从HDFS读数据,处理完之后再写回去。多个作业之间的数据共享借助于HDFS完成。
Spark则是把磁盘换成了内存,第一个作业将结果写入内存而不是磁盘,后面的作业也直接从内存中读取数据,这样可以减少序列化,磁盘,网络的开销。
Spark和Hadoop的协作性:
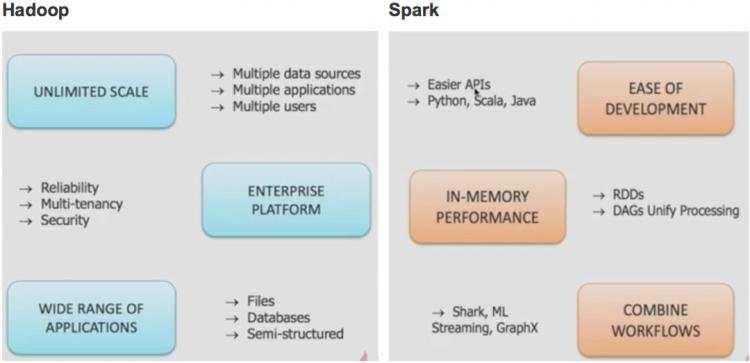
Hadoop 的优势:
数据规模方面:Hadoop在存储空间和计算能力方面,都可以进行扩展,支持多数据源,多应用,多用户。
企业级平台:高可用(reliability),多租户(Multi-tenancy),安全性(Security)
多种应用场景:文件,数据库,半结构化数据
Spark的优势:
易于部署:API简单,支持多种语言
基于内存的计算框架:使用RDD的方式处理数据,使用DAG的处理模式
综合多个工作流和子框架:例如spark SQL,ML,streaming,Graphx等组合使用
因此实际工作中常常将二者综合起来,这样使应用程序可以在内存中计算,提高计算效率。通常二者协作的框架大致如下图所示:

大致的逻辑是:
数据存储在HDFS之上,由Yarn进行统一的资源管理和作业调度。
在yarn之上,可以运行各种作业,如批处理的MR,流处理的Storm,S4,内存计算的spark任务。
我们看到,Hadoop和Spark在生产生是相辅相成的,各自的模块负责各自的功能。
至此我们完成了对Spark的基本知识的学习,如产生背景,架构组成,主要子框架,并进行了与Hadoop的对比,主要在一些概念上和逻辑上形成一个直观的认识,为今后的学习奠定一些基础。欢迎大家留言交流~

(完)










 京公网安备 11010802041100号
京公网安备 11010802041100号