参考:https://www.cnblogs.com/edisonchou/p/4669098.html
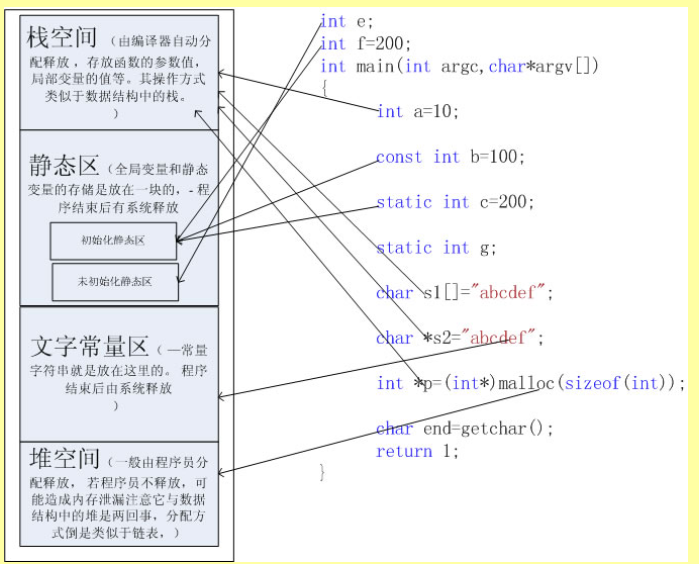
一个由C/C++编译的程序占用的内存分为以下几个部分:
1、栈区(stack):又编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构的栈。
2、堆区(heap):一般是由程序员分配释放,若程序员不释放的话,程序结束时可能由OS回收,值得注意的是他与数据结构的堆是两回事,分配方式倒是类似于数据结构的链表。
3、全局区(static):也叫静态数据内存空间,存储全局变量和静态变量,全局变量和静态变量的存储是放一块的,初始化的全局变量和静态变量放一块区域,没有初始化的在相邻的另一块区域,程序结束后由系统释放。
4、文字常量区:常量字符串就是放在这里,程序结束后由系统释放。
5、程序代码区:存放函数体的二进制代码。
数据结构的栈和堆
参考:https://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
首先在数据结构上要知道堆栈,尽管我们这么称呼它,但实际上堆栈是两种数据结构:堆和栈。
堆和栈都是一种数据项按序排列的数据结构。
栈就像装数据的桶或箱子
我们先从大家比较熟悉的栈说起吧,它是一种具有后进先出性质的数据结构,也就是说后存放的先取,先存放的后取。
这就如同我们要取出放在箱子里面底下的东西(放入的比较早的物体),我们首先要移开压在它上面的物体(放入的比较晚的物体)。
堆像一棵倒过来的树
- 而堆就不同了,堆是一种经过排序的树形数据结构,每个结点都有一个值。
- 通常我们所说的堆的数据结构,是指二叉堆。
- 堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。
由于堆的这个特性,常用来实现优先队列,堆的存取是随意,这就如同我们在图书馆的书架上取书,虽然书的摆放是有顺序的,但是我们想取任意一本时不必像栈一样,先取出前面所有的书,书架这种机制不同于箱子,我们可以直接取出我们想要的书。
内存分配中的栈和堆
内存分配中的堆区和栈区并不是数据结构的堆和栈,之所以要说数据结构的堆和栈是为了和后面我要说的堆区和栈区区别开来,请大家一定要注意。
下面就说说C语言程序内存分配中的堆和栈,这里有必要把内存分配也提一下,大家不要嫌我啰嗦,一般情况下程序存放在Rom(只读内存,比如硬盘)或Flash中,运行时需要拷到RAM(随机存储器RAM)中执行,RAM会分别存储不同的信息,如下图所示:

内存中的栈区处于相对较高的地址以地址的增长方向为上的话,栈地址是向下增长的。
栈中分配局部变量空间,堆区是向上增长的用于分配程序员申请的内存空间。另外还有静态区是分配静态变量,全局变量空间的;只读区是分配常量和程序代码空间的;以及其他一些分区。
1 int a = 0; //全局初始化区
2 char *p1; //全局未初始化区
3 main()
4 {
5 int b; //栈
6 char s[] = "abc"; //栈
7 char *p2; //栈
8 char *p3 = "123456"; //123456\0在常量区,p3在栈上。
9 static int c =0; //全局(静态)初始化区
10 p1 = (char *)malloc(10); //堆
11 p2 = (char *)malloc(20); //堆
12 }
0.申请方式和回收方式不同
不知道你是否有点明白了。
堆和栈的第一个区别就是申请方式不同:栈(英文名称是stack)是系统自动分配空间的,例如我们定义一个 char a;系统会自动在栈上为其开辟空间。而堆(英文名称是heap)则是程序员根据需要自己申请的空间,例如malloc(10);开辟十个字节的空间。
由于栈上的空间是自动分配自动回收的,所以栈上的数据的生存周期只是在函数的运行过程中,运行后就释放掉,不可以再访问。而堆上的数据只要程序员不释放空间,就一直可以访问到,不过缺点是一旦忘记释放会造成内存泄露。还有其他的一些区别我认为网上的朋友总结的不错这里转述一下:
1.申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的 delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
也就是说堆会在申请后还要做一些后续的工作这就会引出申请效率的问题。
2.申请效率的比较
根据第0点和第1点可知。
栈:由系统自动分配,速度较快。但程序员是无法控制的。
堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。
3.申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
4.堆和栈中的存储内容
由于栈的大小有限,所以用子函数还是有物理意义的,而不仅仅是逻辑意义。
栈: 在函数调用时,第一个进栈的是主函数中函数调用后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
5.存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;放在栈中。
而bbbbbbbbbbb是在编译时就确定的;放在堆中。
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
入栈顺序:
A:函数参数的入栈顺序:自右向左
原因:
函数参数的入栈顺序和具体编译器的实现有关。有些参数是从左向右入栈,如:Pascal语言从左到右入栈(不支持变参),被调用者清栈;有些语言还可以通过修饰符进行指定,如:Visual C++;但是C语言(cdecl)采用自右向左的方式入栈,调用者清栈。
这是因为自右向左入栈顺序的好处就是可以动态的变化参数个数。通过堆栈分析可知,自左向右入栈方式中,最前面的参数会被压入栈底。除非知道参数个数,否则无法通过栈指针的相对位移求得最左边的参数。这样就无法实现可变参数。因此,C语言采用自右向左入栈顺序,主要是因为实现可变长参数形式(如:printf函数)。可变长参数主要通过第一个定参数来确定参数列表,所以自右向左入栈后,函数调用时栈顶指针指向的就是参数列表的第一个确定参数,这样就可以了。
例子1:
1 #include
2
3 void print(int x, int y, int z)
4 {
5 printf("x = %d addr %p\n", x, &x);
6 printf("y = %d addr %p\n", y, &y);
7 printf("z = %d addr %p\n", z, &z);
8 }
9
10 int main()
11 {
12 print(1,2,3);//自右向入压栈
13 return 0;
14 }
运行结果:
1 x = 1 addr 0xbfb5c760 //栈顶,后压栈
2 y = 2 addr 0xbfb5c764
3 z = 3 addr 0xbfb5c768 //栈底,先入栈
B:局部变量的入栈顺序:
在没有栈溢出保护机制下编译时,所有局部变量按系统为局部变量申请内存中栈空间的顺序,即:先申请哪个变量,哪个先入栈,正向的。也就是说,编译器给变量空间的申请是直接按照变量申请顺序执行的。(见例子2)
在有栈溢出保护机制下编译时,入栈顺序有所改变,先按照类型划分,再按照定义变量的先后顺序划分,即:char型先申请,int类型后申请(与编译器溢出保护时的规定相关);然后栈空间的申请顺序与代码中变量定义顺序相反(后定义的先入栈)。(见例子2)
例子2:stack.c
1 #include
2
3 int main()
4 {
5 int a[5] = {1,2,3,4,5};
6 int b[5] = {6,7,8,9,10};
7 char buf1[6] = "abcde";
8 char buf2[6] = "fghij";
9 int m = -1;
10 int n = -2;
11 printf("a[0] = %3d, addr: %p\n", a[0], &a[0]);
12 printf("a[4] = %3d, addr: %p\n", a[4], &a[4]);
13 printf("b[0] = %3d, addr: %p\n", b[0], &b[0]);
14 printf("b[4] = %3d, addr: %p\n", b[4], &b[4]);
15 printf("buf1[0] = %3d, addr: %p\n", buf1[0], &buf1[0]);
16 printf("buf1[5] = %3d, addr: %p\n", buf1[5], &buf1[5]);
17 printf("buf2[0] = %3d, addr: %p\n", buf2[0], &buf2[0]);
18 printf("buf2[5] = %3d, addr: %p\n", buf2[5], &buf2[5]);
19 printf("m = %3d, addr: %p\n", m, &m);
20 printf("n = %3d, addr: %p\n", n, &n);
21 }
没有栈溢出保护机制下的编译:
1 $ gcc stack.c -g -o stack -fno-stack-protector
2 $ ./stack
3 a[0] = 1, addr: 0xbfa5185c //数组内部,地址由低到高不变
4 a[4] = 5, addr: 0xbfa5186c //栈底,高地址
5 b[0] = 6, addr: 0xbfa51848
6 b[4] = 10, addr: 0xbfa51858
7 buf1[0] = 97, addr: 0xbfa51842
8 buf1[5] = 0, addr: 0xbfa51847
9 buf2[0] = 102, addr: 0xbfa5183c
10 buf2[5] = 0, addr: 0xbfa51841
11 m = -1, addr: 0xbfa51838
12 n = -2, addr: 0xbfa51834 //栈顶,低地址
可以看出入栈顺序:a -> b -> buf1 -> buf2 -> m -> n(先定义,先压栈)
栈溢出保护机制下的编译:
1 $ gcc stack.c -g -o stack
2 $ ./stack
3 a[0] = 1, addr: 0xbfc69130 //栈顶
4 a[4] = 5, addr: 0xbfc69140
5 b[0] = 6, addr: 0xbfc69144
6 b[4] = 10, addr: 0xbfc69154
7 buf1[0] = 97, addr: 0xbfc69160 //char类型,优先入栈
8 buf1[5] = 0, addr: 0xbfc69165
9 buf2[0] = 102, addr: 0xbfc69166
10 buf2[5] = 0, addr: 0xbfc6916b //栈底
11 m = -1, addr: 0xbfc69158
12 n = -2, addr: 0xbfc6915c //int类型,后压栈
可以看出入栈顺序:buf2 -> buf1 -> n -> m -> b -> a(char类型先入栈,int类型后入栈;先定义,后压栈)
3).指针越界输出:
例子3:stack1.c
1 #include
2
3 int main()
4 {
5 char buf1[6] = "abcef";
6 char buf2[6] = "fghij";
7 int a[5] = {1,2,3,4,5};
8 int b[5] = {6,7,8,9,10};
9 int m = -1;
10 int n = -2;
11 char *p = &buf2[0];
12 printf("a[0] = %3d, addr: %p\n", a[0], &a[0]);
13 printf("a[4] = %3d, addr: %p\n", a[4], &a[4]);
14 printf("b[0] = %3d, addr: %p\n", b[0], &b[0]);
15 printf("b[4] = %3d, addr: %p\n", b[4], &b[4]);
16 printf("buf1[0] = %3d, addr: %p\n", buf1[0], &buf1[0]);
17 printf("buf1[5] = %3d, addr: %p\n", buf1[5], &buf1[5]);
18 printf("buf2[0] = %3d, addr: %p\n", buf2[0], &buf2[0]);
19 printf("buf2[5] = %3d, addr: %p\n", buf2[5], &buf2[5]);
20 printf("m = %3d, addr: %p\n", m, &m);
21 printf("n = %3d, addr: %p\n", n, &n);
22 printf("p[0] = %3d, addr: %p\n", p[0], &p[0]);
23 printf("p[6] = %3d, addr: %p\n", p[6], &p[6]);
24 printf("p[-6] = %3d, addr: %p\n", p[-6], &p[-6]);
25 printf("p[-42] = %3d, addr: %p\n", p[-42], &p[-42]);
26 printf("p[-43] = %3d, addr: %p\n", p[-43], &p[-43]);
27 printf("p[-53] = %3d, addr: %p\n", p[-53], &p[-53]);
28 printf("p[-54] = %3d, addr: %p\n", p[-54], &p[-54]);
29 printf("p[-55] = %3d, addr: %p\n", p[-55], &p[-55]);
30 printf("p[-56] = %3d, addr: %p\n", p[-56], &p[-56]);
31 printf("p[-57] = %3d, addr: %p\n", p[-57], &p[-57]);
32 printf("p[-58] = %3d, addr: %p\n", p[-58], &p[-58]);
33 printf("p[-59] = %3d, addr: %p\n", p[-59], &p[-59]);
34 }
栈溢出保护机制下的编译:
1 $ gcc stack1.c -g -o stack1
2 $ ./stack1
3 a[0] = 1, addr: 0xbff5ab6c //栈顶,0xbff5ab6c,低地址
4 a[4] = 5, addr: 0xbff5ab7c
5 b[0] = 6, addr: 0xbff5ab80
6 b[4] = 10, addr: 0xbff5ab90
7 buf1[0] = 97, addr: 0xbff5aba0 //&p[-6]
8 buf1[5] = 0, addr: 0xbff5aba5
9 buf2[0] = 102, addr: 0xbff5aba6 //&p[0]
10 buf2[5] = 0, addr: 0xbff5abab //栈底,0xbff5abab,高地址--->&p[6]:越界,值随机
11 m = -1, addr: 0xbff5ab94
12 n = -2, addr: 0xbff5ab98
13 p[0] = 102, addr: 0xbff5aba6 //&buf2[0]
14 p[6] = 0, addr: 0xbff5abac //&buf2[6],越界,无初始值,值随机
15 p[-6] = 97, addr: 0xbff5aba0 //&buf1[0],越界,已有初始值,buf1[0],p[-6]为97
16 p[-42] = 5, addr: 0xbff5ab7c //&a[4]
17 p[-43] = 0, addr: 0xbff5ab7b //&a[4] - 1字节,大小0x00 = 0
18 p[-53] = 0, addr: 0xbff5ab71 //&a[1] + 1字节,大小0x00 = 0
19 p[-54] = 2, addr: 0xbff5ab70 //&a[1]
20 p[-55] = 0, addr: 0xbff5ab6f //p[-55]到p[-58]能看出Linux是小端存储。
21 p[-56] = 0, addr: 0xbff5ab6e //小端存储:低地址存低位,高地址存高位
22 p[-57] = 0, addr: 0xbff5ab6d //a[0]=1,即:0x01 0x00 0x00 0x00(低位到高位)
23 p[-58] = 1, addr: 0xbff5ab6c //&a[0]
24 p[-59] = -65, addr: 0xbff5ab6b //&a[0] - 1字节,越界,无初始值,值随机
入栈顺序:
(栈底:高地址)buf2 -> buf1 -> n -> m -> b -> a[4] -> a[0](栈顶:低地址)
&p[6]—&p[0]—&p[-6]——————&p[-42]—&p[-58]—&p[-59]
提醒:指针p越界会出现问题,如果在p[-6] = ‘k’;那么会导致因越界覆盖内存里面buf1[0]的值。
每个函数栈空间内存如何分配
参考:https://blog.csdn.net/u013318019/article/details/104040516
关于函数在调用过程中的压栈和出栈问题在学习的时候就感觉很经典,对程序的把握可以提升一个台阶。
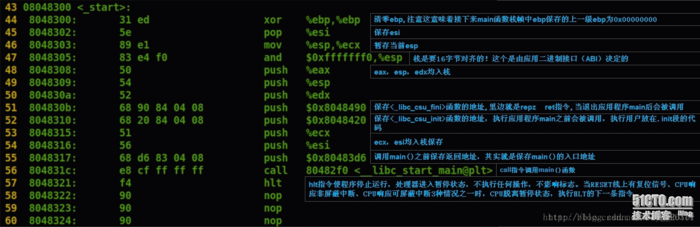
一.首先让我们写出一个简单的函数。(我是在vc6.0中实现,并不表示vs编译器底下不可以实现)。
1 #include
2
3 int add(num1,num2)
4 {
5 int ret = 0;
6 ret = num1+num2;
7 return ret;
8 }
9
10 int main()
11 {
12 int num1 = 1;
13 int num2 = 2;
14 int ret = add(num1,num2);
15 printf("%d ",ret);
16 return 0;
17 }
一、需要声明是add函数中可以直接写成"return num1+num2",我在写博客的时候是故意写成这样,以便于后面的分析。
二、接下来,我们首先明确几个知识点。
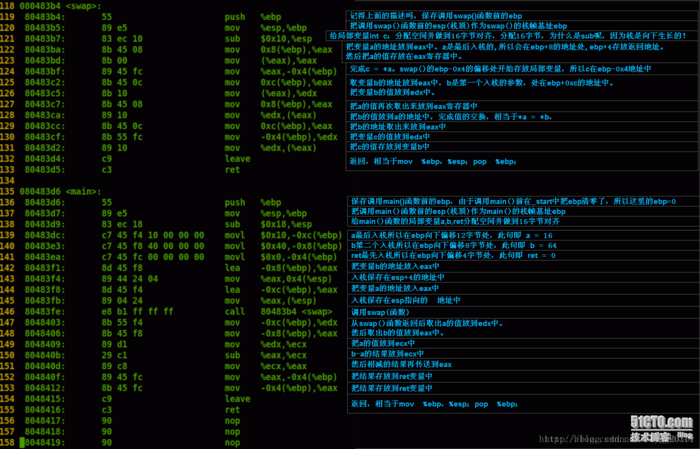
1).栈
首先必须明确一点也是非常重要的一点,栈是向下生长的,所谓向下生长是指从内存高地址->低地址的路径延伸,那么就很明显了,栈有栈底和栈顶,那么栈顶的地址要比栈底低。对x86体系的CPU而言,其中
—> 寄存器ebp(base pointer )可称为“帧指针”或“基址指针”,其实语意是相同的。
—> 寄存器esp(stack pointer)可称为“ 栈指针”。
要知道的是:
—>ebp 在未受改变之前始终指向栈帧的开始,也就是栈底,所以ebp的用途是在堆栈中寻址用的。
—>esp是会随着数据的入栈和出栈移动的,也就是说,esp始终指向栈顶。
2).
假设函数A调用函数B,我们称A函数为"调用者",B函数为“被调用者”则函数调用过程可以这么描述:
(1)先将调用者(A)的堆栈的基址(ebp)入栈,以保存之前任务的信息。
(2)然后将调用者(A)的栈顶指针(esp)的值赋给ebp,作为新的基址(即被调用者B的栈底)。
(3)然后在这个基址(被调用者B的栈底)上开辟(一般用sub指令)相应的空间用作被调用者B的栈空间。
(4)函数B返回后,从当前栈帧的ebp即恢复为调用者A的栈顶(esp),使栈顶恢复函数B被调用前的位置;然后调用者A再从恢复后的栈顶可弹出之前的ebp值(可以这么做是因为这个值在函数调用前一步被压入堆栈)。这样,ebp和esp就都恢复了调用函数B前的位置,也就是栈恢复函数B调用前的状态。
如下图所示:

自己的理解:(栈空间中的局部变量如何访问)
即在函数调用时先保存调用函数的现场情况到栈空间中之后将被调用函数的栈空间区间重新设置(重新设置栈顶和栈底指针),这样被调用函数的局部变量保存在新开辟出来的栈空间中,其中的局部变量可以随机访问,而调用函数的栈空间不属于调用函数的栈空间,所以调用函数不能访问其他函数的栈空间(局部变量),在被调用函数执行完毕后,先将调用函数的现场恢复,然后重设栈顶指针和栈底指针恢复调用者的空间,继续往下执行。
三.在明确了这些知识之后,让我们返回上面那个简单的函数。
1).首先来看看我画出的图:

上面的图片能够粗略的表现函数调用的过程。
2)所产生的汇编代码:


上面两幅图片是mian函数的栈帧。

上面的图片是add函数的栈帧。
3).在liunx平台下的汇编代码
函数中使用的变量在栈上是如何申请空间的
参考:https://www.cnblogs.com/TaoR320/p/12680124.html
在定义变量之前,我们首先要知道,函数中使用的变量在栈上申请空间,至于原因我们下次在讨论。那么对于栈这种数据结构来说,它是由高地址向低地址生长的一种结构。像我们平时在 main函数或是普通的函数中定义的变量都是由栈区来进行管理的。下面进行几个实例以便于我们更加了解栈区的使用。
编写如下C程序:
1 int main()
2 {
3
4 char str[] = { "hello world" };
5 char str2[10];
6
7 printf("%s \n",str);
8 printf("%s\n",str2);
9
10 return 0;
11 }
在 VS 2019中运行
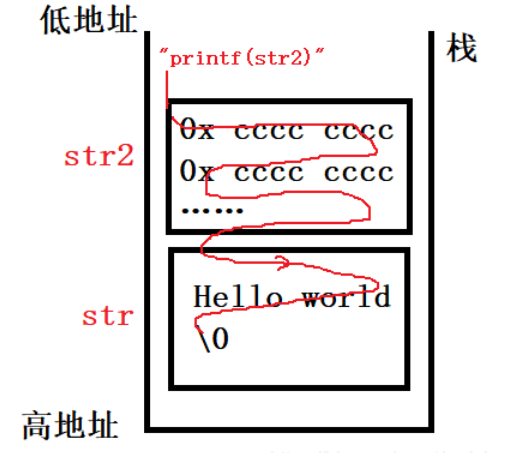
我们在C源码中,给 str 赋值为“Hello World”,而 str2 没有进行赋值。
那为什么打印str2的时候会出现烫烫烫烫烫烫烫烫烫烫Hellow World这种情况呢?
这里要说明一点,在函数内部会根据函数所用到的空间大小生成函数的栈帧,而后对其内存空间进行 0xcccc cccc 的初始化赋值。而\'cc\' 在中文编码下就是“烫”字符。有时候我们会说申请的局部变量(函数的作用域下)没有进行赋值其内容会是随机值。这么说其实也没错,原因很简单,在内存中的某个内存块上,无时无刻不伴随着大量程序的使用,而在程序使用过后就会在该内存块处留下一些数据,这些数据我们无法使用在我们看来就是随机值。而在 VS 编译器中为了防止随机值对程序运行结果造成干扰,就通过用初始化为 0xcccc cccc的方式进行统一的初始化。而字符串的输出时靠字符串末尾的 \0 结束符来确定的,str2 ,中并没有该字符,因此在输出时一直顺着栈向高地址寻找,直到找到 str 中的 \0 结束符。
还有一个有趣的例子:
代码:
1 #include
2
3 int main(void)
4 {
5 int a[10];
6 int i;
7
8 for(i = 0; i<=10; ++i)
9 {
10 a[i] = 0;
11 }
12 /* .... */
13 }
这是一段最简单不过的数组初始化代码了,可是因为边界判断错误,导致数组访问越界,运行时出现问题。
Linux环境下,运行程序,结果如下:

出现的结果,直接报出栈粉碎错误,程序奔溃。
win10环境下,运行程序,结果如下:

出现的结果,程序一直在运行,并没有奔溃。
对于Linux有保护措施,程序直接奔溃,不容易发现问题。可以从win10的结果中分析,为什么程序会进入死循环??要想完整回答这个问题,需要认识C语言局部变量的栈空间分配。
局部变量的栈空间分配
我们知道,函数局部变量是调用该函数的时候才进行内存分配的,如果有多个局部变量,那么变量的分配应该有一个顺序,C语言对局部变量的分配机制是采用栈的方式,贴出栈的概念图:

参考以下文章:
https://blog.csdn.net/qq_19406483/article/details/77511447
在上述代码中,C语言函数中的同类型局部变量,分配顺序就是:顺序局部变量、顺序参数
假设有如下函数:
1 void fun(int a,int b)
2 {
3 int c;
4 int d;
5 /* ... */
6 }
那么调用这个函数的时候,局部变量分配顺序是c、d、b、a,也就是先从上到下顺序分配局部变量,再从右往左(视编译器而定)顺序分配参数。
回答程序进入死循环的问题********(重要)
现在可以完整回答程序为什么会进入死循环了,按照局部变量的栈空间分配,程序中变量储存顺序如下:

对于
1 for(i = 0; i<=10; ++i)
2 {
3 a[i] = 0;
4 }
最后的a[10]经过地址计算a+10之后就会指向变量 i 所在的内存,然后赋值为0,于是循环变量 i 又从10变到0,再次开启下一次循环,周而复始,于是出现了死循环。
可以验证这一说法,只需要输出 i 的值查看即可:
1 for(i = 0; i<=10; ++i)
2 {
3 a[i] = 0;
4 printf("i=%d\n",i);
5 }
gcc运行结果:
最后,for循环中应该遵循左闭右开的区间规则,因为非常容易阅读出循环次数,而上述的左闭右闭,阅读的时候还要心算一会儿(10-0+1=11次)。











 京公网安备 11010802041100号
京公网安备 11010802041100号