作者:mobiledu2502938445 | 来源:互联网 | 2022-09-28 13:45
本文带领大家学习如何使用Java压缩文件打包tar.gz包,主要通过Apachecompress工具打包,通过示例代码给大家介绍的非常详细,感兴趣的朋友跟随小编一起看看吧
一、背景
最近,小哈主要在负责日志中台的开发工作, 等等,啥是日志中台?

俺只知道中台概念,这段时间的确很火,但是日志中台又是用来干啥的?
这里小哈尽量地通俗的说下日志中台的职责,再说日志中台之前,我们先扯点别的?

相信大家对集中式日志平台 ELK 都知道一些,生产环境中, 稍复杂的架构,服务一般都是集群部署,这样,日志就会分散在每台服务器上,一旦发生问题,想要查看日志就会非常繁琐,你需要登录每台服务器找日志,因为你不确定请求被打到哪个节点上。另外,任由开发人员登录服务器查看日志本身就存在安全隐患,不小心执行了 rm -rf * 咋办?
通过 ELK , 我们可以方便的将日志收集到一处(Elasticsearch 集群)来进行多维度的分析。
但是部署高性能、高可用的 ELK 是有门槛的,业务组想要快速的拥有集中式日志分析的能力,往往需要经过前期的技术调研,测试,踩坑,才能将这个平台搭建起来。
日志中台的使命就是让业务线能够快速拥有这种能力,只需傻瓜式的在日志平台完成接入操作即可。

臭嗨!说了这么多,跟你这篇文章的主题有啥关系?
额,小哈这就进入主题。
既然想统一管理日志,总得将这些分散的日志采集起来吧,那么,就需要一个日志采集器,Logstash 和 Filebeat 都有采集日志的能力,但是 Filebeat 相较于 Logstash 的笨重, 它更轻量级,几乎零占用服务器系统资源,这里我们选型 Filebeat。
业务组在日志平台完成相关接入流程后,平台会提供一个采集器包。接入方需要做的就是,下载这个采集器包并扔到指定服务器上,解压运行,即可开始采集日志,然后,就可以在日志平台的管控页面分析&搜索这些被收集的日志了。
这个 Filebeat 采集器包里面,包含了采集日志文件路径,输出到 Kafka 集群,以及一些个性化的采集规则等等。
怎么样?是不是感觉很棒呢?
二、如何通过 Java 打包文件?
2.1 添加 Maven 依赖
org.apache.commons
commons-compress
1.12
2.2 打包核心代码
通过 Apache compress 工具打包思路大致如下:
①:创建一个 FileOutputStream 到输出文件(.tar.gz)文件。
②:创建一个GZIPOutputStream,用来包装FileOutputStream对象。
③:创建一个TarArchiveOutputStream,用来包装GZIPOutputStream对象。
④:接着,读取文件夹中的所有文件。
⑤:如果是目录,则将其添加到 TarArchiveEntry。
⑥:如果是文件,依然将其添加到 TarArchiveEntry 中,然后还需将文件内容写入 TarArchiveOutputStream 中。
接下来,直接上代码:
import org.apache.commons.compress.archivers.tar.TarArchiveEntry;
import org.apache.commons.compress.archivers.tar.TarArchiveOutputStream;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.util.zip.GZIPOutputStream;
/**
* @author 犬小哈 (公众号: 小哈学Java)
* @date 2019-07-15
* @time 16:15
* @discription
**/
public class TarUtils {
/**
* 压缩
* @param sourceFolder 指定打包的源目录
* @param tarGzPath 指定目标 tar 包的位置
* @return
* @throws IOException
*/
public static void compress(String sourceFolder, String tarGzPath) throws IOException {
createTarFile(sourceFolder, tarGzPath);
}
private static void createTarFile(String sourceFolder, String tarGzPath) {
TarArchiveOutputStream tarOs = null;
try {
// 创建一个 FileOutputStream 到输出文件(.tar.gz)
FileOutputStream fos = new FileOutputStream(tarGzPath);
// 创建一个 GZIPOutputStream,用来包装 FileOutputStream 对象
GZIPOutputStream gos = new GZIPOutputStream(new BufferedOutputStream(fos));
// 创建一个 TarArchiveOutputStream,用来包装 GZIPOutputStream 对象
tarOs = new TarArchiveOutputStream(gos);
// 若不设置此模式,当文件名超过 100 个字节时会抛出异常,异常大致如下:
// is too long ( > 100 bytes)
// 具体可参考官方文档: http://commons.apache.org/proper/commons-compress/tar.html#Long_File_Names
tarOs.setLongFileMode(TarArchiveOutputStream.LONGFILE_POSIX);
addFilesToTarGZ(sourceFolder, "", tarOs);
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
tarOs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void addFilesToTarGZ(String filePath, String parent, TarArchiveOutputStream tarArchive) throws IOException {
File file = new File(filePath);
// Create entry name relative to parent file path
String entryName = parent + file.getName();
// 添加 tar ArchiveEntry
tarArchive.putArchiveEntry(new TarArchiveEntry(file, entryName));
if (file.isFile()) {
FileInputStream fis = new FileInputStream(file);
BufferedInputStream bis = new BufferedInputStream(fis);
// 写入文件
IOUtils.copy(bis, tarArchive);
tarArchive.closeArchiveEntry();
bis.close();
} else if (file.isDirectory()) {
// 因为是个文件夹,无需写入内容,关闭即可
tarArchive.closeArchiveEntry();
// 读取文件夹下所有文件
for (File f : file.listFiles()) {
// 递归
addFilesToTarGZ(f.getAbsolutePath(), entryName + File.separator, tarArchive);
}
}
}
public static void main(String[] args) throws IOException {
// 测试一波,将 filebeat-7.1.0-linux-x86_64 打包成名为 filebeat-7.1.0-linux-x86_64.tar.gz 的 tar 包
compress("/Users/a123123/Work/filebeat-7.1.0-linux-x86_64", "/Users/a123123/Work/tmp_files/filebeat-7.1.0-linux-x86_64.tar.gz");
}
}
至于,代码每行的作用,小伙伴们可以看代码注释,说的已经比较清楚了。
接下来,执行 main 方法,测试一下效果,看看打包是否成功:
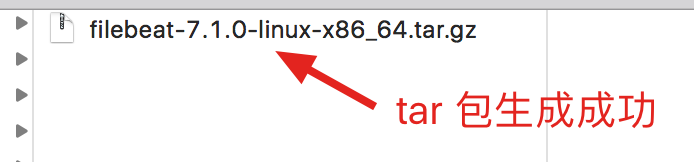
生成采集器 tar.gz 包成功后,业务组只需将 tar.gz 下载下来,并扔到指定服务器,解压运行即可完成采集任务啦~

三、结语
本文主要还是介绍如何通过 Java 来完成打包功能,关于 ELK 相关的知识,小哈会在后续的文章中分享给大家,本文只是提及一下,欢迎小伙伴们持续关注哟,下期见~
到此这篇关于使用Java 压缩文件打包tar.gz 包的详细教程的文章就介绍到这了,更多相关Java 压缩文件打包tar.gz 包内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!












 京公网安备 11010802041100号
京公网安备 11010802041100号