作者:马黛茶总部 | 来源:互联网 | 2023-06-13 19:32
在一篇已经被ICCV 2017接收的论文中,诺丁汉大学的研究人员提出了他们号称是迄今最大3D人脸对齐数据集,以及精准实现2D、3D以及2D到3D人脸对齐的网络。研究人员用《我们距离解决2D&3D人脸对齐问题还有多远》为题,首次调查了在所有现有2D人脸对齐数据集和新引入的大型3D数据集上,距离达到接近饱和性能(saturating performance)还有多远。
ImageNet百万级精准标记数据集开启了图像识别新时代,人们也由此意识到,数据跟算法同样重要。为了构建更好的模型和算法,越来越多的研究人员开始在数据集方面展开探索,而且,标记数据的方法也不仅仅限于耗时耗力的人工。
这方面最新的一项成果,是诺丁汉大学计算机视觉实验室的研究人员即将在ICCV 2017发表的论文,研究人员在论文中描述了他们创建的迄今最大的3D人脸对齐数据集(约230,000幅精准标记图像),以及他们使用2D到3D转换生成标记的方法。
论文标题名为《我们距离解决2D&3D人脸对齐还有多远?》(How far are we from solving the 2D & 3D Face Alignment problem? And a dataset of 230,000 3D facial landmarks)。研究人员希望,在此数据集的基础上,人脸对齐问题将迎来更大更快的发展。

效果展示:使用论文提出的网络(被作者称为“世界上最准确的人脸对齐网络”)检测面部特征点,2D和3D坐标都适用。来源:项目的Github
人脸对齐,计算机视觉过去几十年研究最多的一个议题
随着深度学习的出现和大规模注释数据集的发展,近来的工作已经显示出即使在最具挑战性的计算机视觉任务上也达到前所未有的准确性。在这项工作中,作者专注于特征点定位(landmark localization),尤其是人脸特征点定位,也被称为人脸对齐(face alignment),“人脸对齐”也可以说是过去几十年来计算机视觉中研究最多的主题之一。
近来关于使用卷积神经网络(CNN)的特征点定位的工作已经推动了其他领域的界限,例如如人体姿态估计,但目前尚不清楚在人脸对齐方面取得怎样的成果。
历史上,根据任务的不同,有不同的技术已被用于特征点定位。例如,在神经网络出现之前,人体姿态估计的工作主要是基于图结构(pictorial structure)和各种复杂的扩展(extension),因为它们能够模拟大的外观变化, 适应广泛的人类姿势。这些方法虽然没有被证明能够实现用于人脸对齐任务的级联回归方法(cascaded regression method)表现出的高精确度,但另一方面,级联回归方法的性能在初始化不准确的情况下,或有大量的自我封闭的特征点或大的平面内旋转时会变差。
最近,基于热图回归(heatmap regression)的完全卷积神经网络架构彻底改变了人体姿态估计,即使对于最具挑战性的数据集也得到非常高的准确度。由于它们对端到端训练和人工工程的需求很少,这种方法可以很容易地应用于人脸对齐问题。
5大贡献,包括首次构建强大基准,使用2D-3D方法构建迄今最大数据集
作者表示,按照这个路径,“我们的主要贡献是构建和训练这样一个强大的人脸对齐网络,并首次调查在所有现有的2D人脸对齐数据集和新引入的大型3D数据集上距离达到接近饱和性能(saturating performance)有多远”。
更具体地说,他们的贡献是:
1. 首次构建了一个非常强大的基准(baseline),结合state-of-the-art的特征点定位架构和state-of-the-art的 residual block,并在非常大的综合扩展的2D人脸特征点数据集训练。然后,我们对所有其他2D数据集(约230000张图像)进行评估,调查我们距离解决2D人脸对齐问题还有多远。
2. 为了解决3D人脸对齐数据集少的问题,我们进一步提出了一种将2D注释转换为3D注释的2D特征点CNN方法,并使用它创建LS3D-W数据集,这是迄今最大、最具挑战性的3D人脸特征点数据集(约230000张图像),这是将现有的几乎所有数据集统一起来得到的。
3. 然后,我们训练了一个3D人脸对齐网络,并在新的大型3D人脸特征点数据集进行评估,调查我们距离解决3D人脸对齐问题尚有多远。
4. 我们进一步研究影响人脸对齐性能的所有“传统”因素,例如大姿态,初始化和分辨率,并引入“新的”因素,即网络的大小。
5. 我们的研究结果显示,2D和3D人脸对齐网络都实现了非常高准确度的性能,这可能是接近了所使用的数据集的饱和性能。
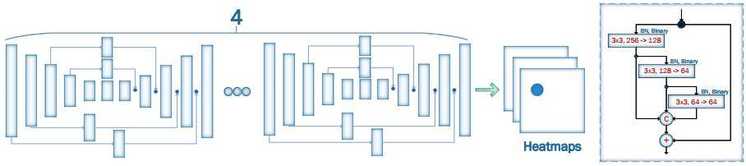
2D-FAN结构:通过堆叠四个HG构建的人脸对齐网络(Face Alignment Network ,FAN),其中所有的 bottleneck blocks(图中矩形块)被替换为新的分层、并行和多尺度block。
方法及数据:2D、3D标注及2D-3D转换都接近饱和性能
作者首先构建了一个人脸对齐网络“FAN”(Facee Alignment Network),然后基于FAN,构建了2D-to-3D-FAN,也即将给定图像2D面部地标转换为3D的网络。作者表示,据他们所知,在大规模2D/3D人脸对齐实验中训练且评估FAN这样强大的网络,还尚属首次。
他们基于人体姿态估计最先进的架构之一HourGlass(HG)来构建FAN,并且将HG原有的模块bottleneck block替换为一种新的、分层并行多尺度结构(由其他研究人员提出)。
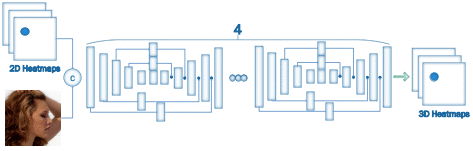
2D-to-3D-FAN网络架构:基于人体姿态估计架构HourGlass,输入是RGB图像和2D面部地标,输出是对应的3D面部地标。

2D-FAN标记结果
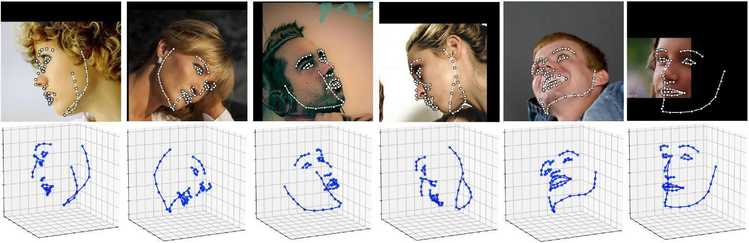
3D-FAN标记结果
下面是跟现有方法(红色)的对比,这样看更能明显地看出新方法的精度:


除了构建FAN,作者的目标还包括创建首个超大规模的3D面部地标数据集。目前3D面部地标的数据还十分稀少,因此也让这项工作贡献颇大。鉴于2D-FAN卓越的效果,作者决定使用2D-to-3D-FAN来生成3D面部地标数据集。
但是,这也带来了一个问题,那就是评估2D转3D数据很难。现有的最大同类数据集是AFLW2000-3D。于是,作者先使用2D-FAN,生成2D面部地标标注,再使用2D-to-3D-FAN,将2D数据转换为3D面部地标,最后将生成的3D数据与AFLW2000-3D进行比较。
结果发现,两者确实有差异,下图展示了差异最大的8幅图像标记结果(白色是论文结果):

作者表示,造成差异的最大原因是,以前的方法半自动标记管道对一些复杂姿态没有生成准确的结果。于是,在改进数据后,他们将AFLW2000-3D纳入现有数据集,创建了LS3D-W(Large Scale 3D Faces in-the-Wild dataset),一共包含了大约230,000幅标记图像,也是迄今最大的3D人脸对齐数据集。
作者之后从各个方面评估了LS3D-W数据集的性能。研究结果表明,他们的网络已经达到了数据集的“饱和性能”,在构图、分辨率,初始化以及网络参数数量方面表现出了超高的弹性(resilience)。更多信息参见论文。
作者表示,虽然他们还没有在这些数据集中去探索一些罕见姿态的效果,但只要有足够多的数据,他们确信网络也能够表现得一样好。
论文:我们距离解决2D&3D人脸对齐还有多远?

摘要
本文研究了一个非常深的神经网络在现有的2D和3D人脸对齐数据集上达到接近饱和性能的程度。为这个目的,我们提出做了5个贡献:(a)结合最先进的人脸特征点定位(landmark localization)架构和最先进的残差模块(residual block),我们首次构建了一个非常强大的基准,在一个非常大的2D人脸特征点数据集(facial landmark dataset)上训练,并在所有其他人脸特征点数据集上进行评估。(b)我们创建了一个将2D特征点标注转换为3D,并统一所有现有的数据集,从而创建了迄今最大、最具有挑战性的3D人脸特征点数据集LS3D-W(约230000张图像)。(c)然后,我们训练一个神经网络来进行3D人脸对齐(face alignment),并在新的LS3D-W数据集上进行评估。(d)我们进一步研究影响人脸对齐性能的所有“传统”因素,例如大姿态( large pose),初始化和分辨率,并引入一个“新的”因素,即网络的大小。(e)我们的研究显示2D和3D人脸对齐网络都实现了非常高的性能,这很可能接近所使用的数据集的饱和性能。训练和测试代码以及数据集可以从 https://www.adrianbulat.com/face-alignment/ 下载。
以及模型下载
-
2D-FAN:https://www.adrianbulat.com/downloads/FaceAlignment/2D-FAN-300W.t7
-
3D-FAN:https://www.adrianbulat.com/downloads/FaceAlignment/3D-FAN.t7
-
2D-to-3D FAN:https://www.adrianbulat.com/downloads/FaceAlignment/2D-to-3D-FAN.tar.gz
-
3D-FAN-depth:https://www.adrianbulat.com/downloads/FaceAlignment/3D-FAN-depth









 京公网安备 11010802041100号
京公网安备 11010802041100号