def backprop(self, x, y):
"""返回一个元组(nabla_b, nabla_w)代表目标函数的梯度."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activatiOns= [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
"""l = 1 表示最后一层神经元,l = 2 是倒数第二层神经元, 依此类推."""
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
4.完整代码实现
# -*- coding: utf-8 -*-
import random
import numpy as np
class Network(object):
def __init__(self, sizes):
"""参数sizes表示每一层神经元的个数,如[2,3,1],表示第一层有2个神经元,第二层有3个神经元,第三层有1个神经元."""
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
def feedforward(self, a):
"""前向传播"""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):
"""随机梯度下降"""
if test_data:
n_test = len(test_data)
n = len(training_data)
for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in xrange(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print "Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test)
else:
print "Epoch {0} complete".format(j)
def update_mini_batch(self, mini_batch, eta):
"""使用后向传播算法进行参数更新.mini_batch是一个元组(x, y)的列表、eta是学习速率"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
def backprop(self, x, y):
"""返回一个元组(nabla_b, nabla_w)代表目标函数的梯度."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# 前向传播
activation = x
activatiOns= [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
"""l = 1 表示最后一层神经元,l = 2 是倒数第二层神经元, 依此类推."""
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def evaluate(self, test_data):
"""返回分类正确的个数"""
test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
return (output_activations-y)
def sigmoid(z):
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""sigmoid函数的导数"""
return sigmoid(z)*(1-sigmoid(z))
5.简单应用
# -*- coding: utf-8 -*-
from network import *
def vectorized_result(j,nclass):
"""离散数据进行one-hot"""
e = np.zeros((nclass, 1))
e[j] = 1.0
return e
def get_format_data(X,y,isTest):
ndim = X.shape[1]
nclass = len(np.unique(y))
inputs = [np.reshape(x, (ndim, 1)) for x in X]
if not isTest:
results = [vectorized_result(y,nclass) for y in y]
else:
results = y
data = zip(inputs, results)
return data
#随机生成数据
from sklearn.datasets import *
np.random.seed(0)
X, y = make_moons(200, noise=0.20)
ndim = X.shape[1]
nclass = len(np.unique(y))
#划分训练、测试集
from sklearn.cross_validation import train_test_split
train_x,test_x,train_y,test_y = train_test_split(X,y,test_size=0.2,random_state=0)
training_data = get_format_data(train_x,train_y,False)
test_data = get_format_data(test_x,test_y,True)
net = Network(sizes=[ndim,10,nclass])
net.SGD(training_data=training_data,epochs=5,mini_batch_size=10,eta=0.1,test_data=test_data)
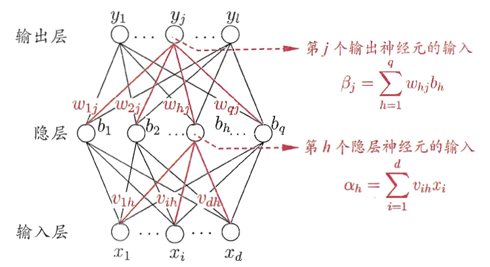
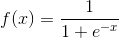
 ,即计算导数十分方便。
,即计算导数十分方便。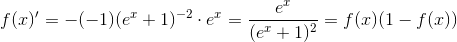
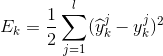 ,公式中的1/2是为了计算导数方便。
,公式中的1/2是为了计算导数方便。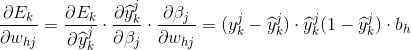















 京公网安备 11010802041100号
京公网安备 11010802041100号