作者:流寇仏翔_609 | 来源:互联网 | 2023-06-03 11:05
篇首语:本文由编程笔记#小编为大家整理,主要介绍了机器学习算法简介人工神经网络算法相关的知识,希望对你有一定的参考价值。
篇首语:本文由编程笔记#小编为大家整理,主要介绍了机器学习算法简介人工神经网络算法相关的知识,希望对你有一定的参考价值。
人工神经网络(Artificial Neural Network,即ANN )算法是一种模仿生物神经网络运行机制,进行分布式并行信息处理的算法模型。神经网络模型由大量的节点(或称神经元)相互联接构成,每个节点代表一种特定的函数,即激励函数(activation function);输入信号被赋予不同的权重,并汇总到相应节点;人工神经网络的输出信号则因网络的连接方式、权重值和激励函数的不同而不同。
人工神经网络是建立在模仿大脑活动的基础上的,因此,在理解人工神经网络算法之前,我们首先需要了解生物神经的运作机制。如下图所示,首先,神经元细胞通过树突接收到输入信号;然后,神经元会根据信号的相对重要程度或频率判断信号的重要程度,并不断积累信号;当信号累积达到一定的阈值后,神经元细胞就会被激活,产生一个输出信号,并通过轴突向外传递。

单层的人工神经网络模型和神经元细胞的运行机制十分相似。

图2结构描述了单层人工神经网络模型中,输入信号(x1,x2,x3)和输出信号y之间的传递机制。和神经元的运行原理一样,不同的输入信号x被赋予不同的权重w后,汇总到一个节点,通过激活函数f判断后,产生一个输出信号y。
上述内容就是简单的人工神经网络算法的运行机制,实际运用中,人工神经网络算法更加复杂,如可能拥有更多的层、更多的节点等,但总体上,人工神经网络算法都是由以下三个要素组成:
1.激活函数,根据输入信号判断并产生输出信号;
2.网络拓扑结构,体现人工神经网络中的节点数量、层级数量以及它们的联系结构;
3.训练算法,用于决定不同输入信号的权重如何确定。
激活函数是人工神经网络处理和传递信号的机制,常见的激活函数由以下几种:
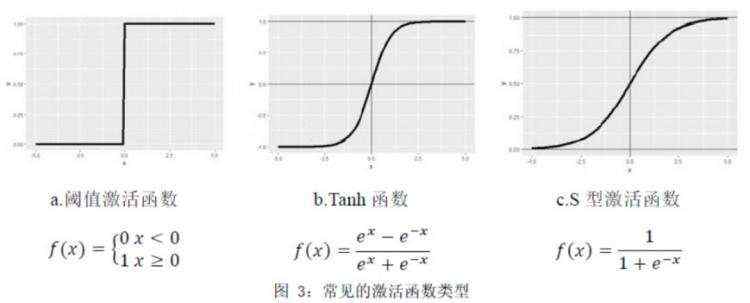
除上述3中激活函数外,较为常用的还用ReLU函数、ELU函数和PReLU函数等。
网络拓扑结构决定了人工神经网络算法的学习能力,一般来说,拥有越庞大、越复杂的拓扑结构的算法具有越强的学习能力,能够识别更加细微的特征。虽然人工神经网络模型可以有无数种拓扑结构,但其基本要素仅以下三种:(1)层数;(2)信息是否可以反向传播;(3)每一层中节点的数量。
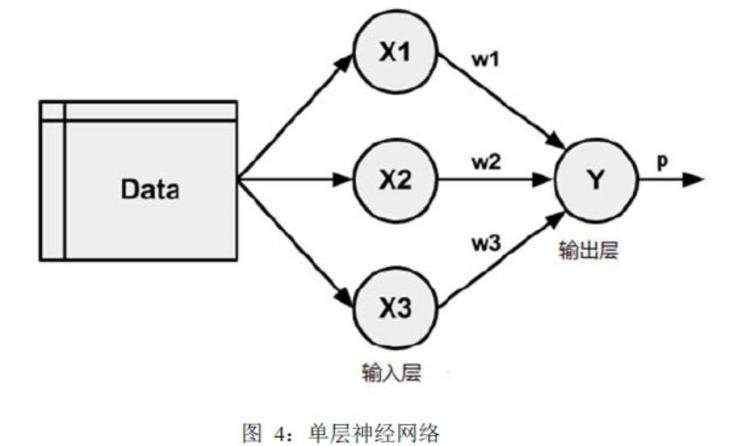
如图4所示,从样本数据中获得输入信号的节点成为输入节点,由其组成的层称为输入层;对外输出信号的节点称为输出节点,其对应的层称为输出层。图4的拓扑结构中仅含有一组权重,因此,称该结构为单层人工神经网络。单层人工神经网络主要用于简单的图片识别,尤其是用于线性可分的图形。
为了创建更复杂的拓扑结构,我们经常使用的方法就是加入更多的层,即加入隐含层,如下图所示。
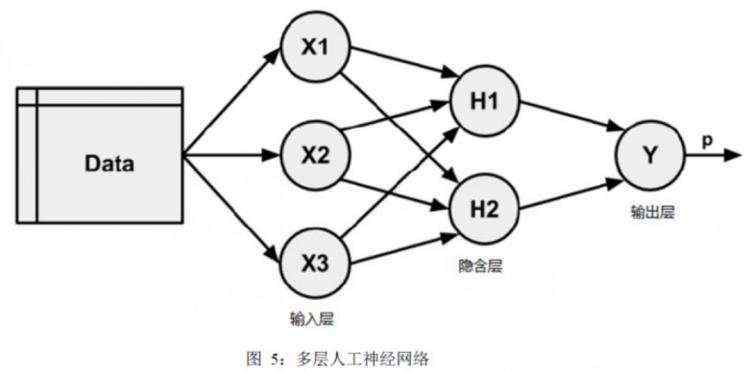
根据信息传播方向,人工神经网络算法可以分为前馈式神经网络,即仅允许信息从输入节点至输出节点的单向传播;以及回归神经网络,即允许信息反向传播。其中,回归神经网络的发展和运用还不成熟,目前最常用的人工神经网络算法主要是前馈式神经网络。
除了层数和信息传播方向之外,人工神经网络的拓扑结构还会随着每一层中节点数量的变化而变化。输入节点的数量取决于样本数据,输出节点的数量取决于事先预设的结果数量,因此,节点数量的改变主要是指隐含层中节点数量的变化。不幸的是,实际操作中,我们没有办法确定最佳的节点数量。虽然,增加节点的数量可以使人工神经网络算法的学习能力提高,但过多的节点数量可能会导致过度拟合的问题,而且会增加训练的难度。因此,为了避免上述问题,常用的标准是在模型结果足够好的基础上,采用尽量少的节点。
反向传播(Backpropagation,BP)方法是最常用的人工神经网络训练方法。通常,BP人工神经网络算法采用重复迭代的方式进行计算,其步骤如下:
1.由于神经网络结构中没有先验知识,初始权重通常是随机设定的;
2.利用该权重,计算获得输出信号;
3.将计算得出的输出信号与训练组中的实际值进行比较,利用输出信号与实际值之间的误差反向追溯,修改权重,从而减小误差。
4.重复步骤2和3,直到达到预先设定的标准。
那么,在BP方法中,如何修改权重才能够达到减小误差的目的?我们通常采用的办法就是梯度下降法。梯度下降法的原理跟探险者在丛林中寻找水源的方法相似,检查地形并沿着倾斜度最大的斜坡向下走,最终到达地势最低的山谷,从而找到水源。

BP方法通过计算激活函数的导数来确定输入信号与误差之间的斜率,该斜率代表了输入信号的变化所引起误差的变化,同时该斜率也是权重的函数。因此,BP方法试图通过改变权重达到最大程度地降低误差的目的。


![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)









 京公网安备 11010802041100号
京公网安备 11010802041100号