本文由编程笔记#小编为大家整理,主要介绍了图像识别原理--CNN卷积神经网络相关的知识,希望对你有一定的参考价值。
前言
卷积神经网络不同于神经网络,在图片处理这方面有更好的表现。本文主要对神经网络和卷积神经网络做了简要的对比,着重介绍了卷积神经网络的层次基础,同时也简要介绍了卷积神经网络参数更新方式和其优缺点,并结合具体实例对卷积神经网络的工作方式做了介绍。
神经网络与卷积神经网络
神经网络对于各种各样的数据都具有一个很强的非线性拟合能力,但是在语音、图像这类“raw data”数据处理上,我们迟迟得不到突破。这些数据属于人类一出生就能接受到的信息,在这方面数据,我们很难用机器学习的方法去驱动产出很好的效果。
在机器学习中有个很重要的东西叫做特征。在解决很多机器学习问题时,对于 feature,我们用的是 Handcraft Feature,就是手工造出来的特征。手造出来的特征在有一定物理含义的问题当中具有一定作用。
但是,在图像问题处理当中,我们很难从原始的像素点上,人工的抽取一些特征,去描述表达图像。
所以在图像这类 raw data 问题上,迟迟得不到进展。直到 DNN 的出现,给图像这类数据的处理带来了希望。
虽然 DNN 能用到图像处理问题上,但用的较多的还是 CNN(conclusion neural network)。为什么呢?接下来我们进行详细解释。
如下图,是一个 DNN 的神经网络结构
所有层和层之间,是一个全连接(fully connection)。全连接指的是,每一个output,实际上是上一层的 input 去做一个:
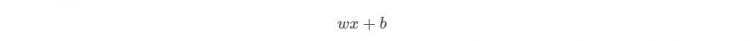
每一个前一层的向量当中的每一个元素都需要去参与这个运算。
平常,为了保证图像的质量,尽可能多的保存图像的信息,我们图像数据的分辨率会很高,分辨率高,意味着原始输入的图像数据是一个高维度向量。
举个例子,输入是 1000* 1000* 3 的一张图片,DNN 会对其做一个拉伸处理,拉长成一个向量。那么这个向量维度就是 300w 。那么就会有一个 300w 个值的输入向量。下一层的隐层的节点个数就不能取的太少,太少的话,原始的输入又多,这就导致很难捕捉到更多的信息。假设隐层取4000 ,那么输入和隐层之间有多少个权重参数 w 呢?
即:300w * 4K 个权重 w 。
这样会导致参数量过大,单单一层就有 300w * 4K 参数,过多的参数会带来两方面问题:
1.参数量太大,对于工程上是一个很大的挑战,最后更新参数时压力较大;
2.参数量大,容易导致 过拟合(overfitting),参数量大,会导致模型的拟合能力非常强,这个时候会带来过拟合问题,而且很难控制;
这两个问题导致了 DNN 在图像上应用十分困难。
这就使得人们开始寻找对 DNN 的优化方法,使得其在图像上应用更适合。
在之前我们提到的问题中,可以知道DNN应用的主要问题在于参数量过大。那么有没有一个办法能够保持它的学习能力,使得它能够在图像上捕捉到尽可能多的信息,又能把参数量降下来呢?
在此需求下,卷积神经网络这类的网络由此出现。
卷积神经网络结构图如下图所示:

注释:上图中,输入是一张图片,输出是结果的概率向量,告诉你属于结果中每个类别的概率有多大。
卷积神经网络层级结构
在CNN中,每一层网络叫做 fully connection layer(全连接层)。白色字体 CONV 叫做卷积层(最重要一层,特征抽取就在这一层进行),黄色字体 RELU 是激活层,有激活函数,可以取不同方式去完成激活层运算。红色字体 POOL 叫做池化层。

数据输入层
一般一张图片进行输入,我们会进行一些操作,对于图像数据,不会把一张图片原始数据都输入进去,一般采取去均值化的处理手段。

去均值
接下来对去均值的方法进行讲解,如下图:

original data 图中,数据分布如下,可以求出一个均值点(图中小红方框),然后把图像中每一个点减去均值这个点的坐标或者对应的向量的维度的值,就得到了zero-centered data这张图,相当于做了一个平移,把中心点移动到原点,让数据分布更合理。这即是取均值的原理。
归一化
在机器学习中,我们一般会对数据进行一个归一化的处理。如果各个 特征(feature) 的scale,即幅度是不一样的,这会对优化算法造成一定的影响。比如,这个feature的数据都在1000~2000之间,而另外一个feature数据大部分在个位数,这样会对训练造成很大的影响,因此我们会对其进行幅度缩放的处理。
大体归一化就是(数据-数据均值)/标准差,效果如上图的normalized data图所示。
去相关化与白化
PCA 一般用于去相关,用在降维当中,经过 PCA 处理之后,每一个维度之间是不相关的。
所以,我们可以看到下图中original data 与 decorrelated data 之间的差异。做完 PCA 处理后,每一个 feature 可能又会有幅度不一致的问题,因此再对它进行幅度缩放处理。最后我们可以看到,最标准的分布如whitened图所示。

图像数据一般是 W * H * C的一个三维矩阵,这个数据非常的“乖巧”,即这些数据每一个点的值都处于0~255之间。也因此,对于图像数据,我们采取的是去均值处理,归一化的方法在这里是不太需要的。
如果我们不对数据进行去均值处理,它的分布可能具有偏向性,偏向某个位置。
从图像上来说,比如区分不同颜色或者颜色的程度,不同颜色会有深浅,如果对红色进行区分,有深红有浅红,如果我们求出其均值,做一个差,他们之间的对比度会明显变高。
对于去均值的处理,主要有两种方式,一种是Alex,一种是Vgg。
Alex
假设你原始输入图片是一个200* 200* 3的矩阵,如果现在有100万张图片,它会把这100万张图片去做求和,然后再除以100万。到最后,Alex的均值矩阵还是一个200* 200* 3的一个维度。
所以我们在训练集上会训练出这样一个均值矩阵,然后减去它。而测试集也是需要减去训练集的均值矩阵。
Vgg
vgg的处理是直接求了RGB三个颜色通道的均值,所以其最后均值结果是三个数。当有新的图片进来后,在R上会减去R的均值,其他通道也对应。
对于训练集和测试集,一定要注意做同样的处理操作。
卷积计算层
接下来我们看看,卷积层如何计算的。在DNN中我们会遇到参数量过大的问题,我们想着如何能降低参数量同时又尽量捕捉到图像上所有的信息。为了捕捉图像上所有的信息,那么将不可避免图像上所有点都要参与运算。如果都要参与运算,如何降低参数量呢?
这里就要提到一个处理方式——“参数共享”。
下面讲讲卷积神经网络(conclusion layer)如何完成参数的共享。
参数共享,无非就是要“看”完整张图片的内容,当神经元得到激活时(睁开眼睛),一睁开眼,由于采取的是全连接的方式,所以后面的每个位置和前面的都有连接,一经激活整张图都看到了,这是 DNN 做的事情。
在 CNN 这里采取的是分块的方式读取数据,下一层有多少神经元,深度就是多少。

神经元取一个窗口块,大小是4 * 4* 3,从红圈位置开始滑动遍历图像所有的位置。每个神经元只与每个特定位置区域的窗口有连接,所以连接的权重,只取决于神经元与特点区域窗口之间连线的权重w。
滑窗之间可能会有重叠,从上一个窗口滑动多少步到下一个滑窗,这个叫做步长(stride)。
0填充值。比如一张图片是32* 32* 3的图片,如果卷积核kernel,是3* 3* 3的,每次滑动的步长又是3,不重叠,这就无法整除,即没办法刚好从左侧滑动到右侧,这个时候就引入了0填充的概念,不够的地方就填充0。
为什么参数量会降下来?
DNN 神经元间的参数量没有降下来的原因是其神经元和前一层每个点连接时,都是一个不同对的w值,所以参数量较大。
而卷积神经网络做法就不一样了,神经元和上一层窗口连接,因为只和窗口连接,所以就固定住4* 4* 3的这一组权重w,只是在滑动窗口看到不同的输入值,与输入值做运算的这一组权重的数是固定的。
先从第一个神经元来看,固定住它和窗口连接的权重,然后后去滑动不同的图像数据。

接下来用一组连续图来解释,如下:



上图黄色的窗口就是我们的卷积核,它在不停的移动。只有一个卷积核,所以输出只有一组output,一个feature map。黄色框右下角是一组权重,它是没有动的,唯一不同的是卷积核在看不同的区域。
具体运算如下图所示,对应的位置与对应的位置做乘积。

有人可能会问,权重W怎么来的?其实权重W这个参数是学习得来的。
那么卷积核心意义是什么意思呢?
我们可以将下图中每一组权重,看成是抽特征的一个滤波器,所以当它对你的图像输入过一遍的时候,会从它的角度抽取一些特征。后续的神经元也会相应的抽取他自己理解的重要的特征,这些特征最后是一起输出的。


有时候图像不只是灰白,比如三色通道的图片,这就使得卷积核变成一个同等的三维的卷积核。

通俗来讲,就拿高考来说吧,假如说你要去参加高考,高考有不同的科目,你为了学好这些科目去面对高考,你应该给不同的学科不同的学习方法。可以类比上面的三个权重,要注意的是,上面三个小权重加在一起才算一个卷积核。
图片最右边的图片加了个 biase 项,是因为有时候我们光靠 wx 无法达到我们想要的结果,所以为了去拟合,给它一个偏制项--biase。三个通道是指我们的输入是一个“厚度”为三的输入。
接下来再对深度/depth 的概念进行讲解。因为每一个神经元输出的都是一个相同维度的矩阵,最后的输出是前面各个神经元输出的叠加,所以我们称其为深度。下图中的一个个神经元是在同一层的,深度是5。

参数共享机制

激励层
激励层涉及到的激活函数是一个非线性的函数,执行的是点对点的运算。假定输出的是一个32* 32 * 6的一个矩阵,(6是指6个神经元)。而激活函数会对这个矩阵的每一个点去做运算。

非线性映射
下图是一些常见的激活函数。

函数图像如下所示:

关于激活函数
一般建议优先尝试 RELU,因为其速度快,因为是分段函数所以求导也方便。

这里讲讲RELU失效的表现。当你发现你训练到一段时间,Loss不往下降低时,即loss function的值一直停留在某个值间震荡,不往下降,说明 RELU 失效了。
sigmoid激活函数能够把值映射到0~1之间的一个概率值,不好的地方在于,如果你是以层级的方式去叠加的话,假设现在有一个复合函数:

其求导为各函数的导数的乘积。由sigmoid函数的图像表示可以知道,在某个取值时,其导数近似为0,那么一旦复合函数求导中某个函数导数为零,根据复合函数求导链式法则,导致结果为0,SGD(随机梯度下降)无法更新参数。
Leaky ReLU,其图像是上图中左手边第二幅图,可以发现,如果我们的输入数据都分布在第二象限,那么就会导致神经元挂掉,无法激活。
关于激活函数的选取,只要你的神经网络不挂掉,选取不同的激活函数可能训练的速度不一样,但是结果的差异不会太大。

池化层(POOLING LAYER)
之前我们说DNN的时候,提到其参数量过大,一个原因是神经元连接的方式,第二个原因是输入的图像数据维度太高,如果输入维度降低了,那么参数量也会有所下降。所以,这里又提出了一种想法,能不能在对数据降维的同时捕捉到尽可能多的信息呢?

如下图,原始灰度图像为224* 224,通过伸缩变化,变成了112* 112,可以发现,大部分的信息都在。这个时候,从原始灰度图像到处理后的灰度图像,如果能在这个过程中保留大部分信息,同时又能够降维,这样对于后面层次的运算有很大的帮助。

Max pooling & Average pooling
基于以上想法,我们整理出来两种方式,如下图所示:

这两种的处理都是降维,又常被称为降维层。
接下来介绍下Max pooling做的操作。在这一层中,我们采取的也是滑窗的形式,假设这里滑窗大小是2* 2,这里也涉及一个概念叫stride(滑动步长),这里假设stride为2。
在滑窗中,对每个不同的位置我们可以做不同的处理,比如说Max pooling。Max pooling做的是,拿下图中4* 4图像的黄色部分来讲,Max pooling就是提取该部分最大的值——3,下面过程也是如此。Max pooling 被广泛的用在大部分CNN的网络中,经由实验证明,其在图像识别问题中,效果要优于Average pooling。
而Average pooling做的就是取平均(求整)。

pooling layer这一层意义是降维和降低过拟合的风险,其实也是一回事,你维度越高,过拟合的风险也越大,可以理解为做的是模糊化处理。
全连接层
全连接层,顾名思义,就是每个神经元和每个神经元之间都会有权重的连接,input和每个神经元之间都有权重的连接。通常,全连接层我们会放在卷积神经网络层级中的尾部,因为其计算量大。

对于卷积层,有时候会把卷积和激励层拼凑在一起视为一个卷积层。
卷积层可视化理解
卷积大部分时候做的事情就是抽特征,如下图所示:

上图中 layer1 是输入图像,从这副图向上把每一层的权重w做一个可视化,如layer2、layer3所示。
通过可视化后,我们可以发现,它每一层有不同的形状或者结构,如果把它当作滤波器来看,它就是不同的算子,不同的filter。每一个神经元会做一个算子,对前一层的输入做特征的处理,去提取更强的、更高层的表示。
下图中圈出来的为第二层中第一、二、三个神经元的权重可视化。

具体例子
输入的图像如下:

第一层卷积层如下:

上图的filter和data个数不一样,因为data只拿了一部分结果出来,无需care。
filter是对layer1的权重w做可视化,得到一个算子,而这个算子对图像做filter之后,会发现每个算子/神经元/filter,关注的东西不一样。
比如下面中间那个圈的filter更关注轮廓,右下方filter更关注颜色的深浅,其他的神经元可能关注的是我们肉眼看不见,有物理学意义的一些东西。

所以每个filter对图像做的是一个滤波,保留的是“自己” 关心、需要的信息。
接下来是第二层:

第二层会从第一层抽取出来的feature上再去进一步抽取,可能会是一些组合特征,这个时候我们就很难看出它在捕捉什么信息了,这些信息就是它根据它的目标总结出来的抽取方式。
接下来的三四五层,就更加难以去解释了。如下图所示:

卷积神经网络训练算法
神经网络要做的就是学到如何去抽特征,而抽的特征就是它的权重w,实际上,就是训练它的权重w。
上篇文章给大家分享了DNN如何训练权重w,我们说这主要依赖BP和SGD这两种方法,通过反向传播拿到它的gradient,也就是当前位置我希望我下一步应该往哪个方向走,然后顺着这个方向,根据SGD(随机梯度下降)算法去做优化。
那么DNN做的是全连接跟CNN有所区别,这两种方法还适用嘛?
我们举个例子,拿Pooling layer中的Max pooling举个例子。Max pooling的函数如下:

g(a,b,c,d)的取值,取决于哪个最大。这个分段函数,如果取到最大值,求导则为1,如果没有取到,gradient则为0.相当于max(x,y)求导。
所以,相对于DNN而言,卷积神经网络每一层都有不同的数学表示,但是不管它数学表示怎么变化,我们总是有办法去求得其梯度。分段函数有分段函数的求法,卷积层求导也有相应的方法,只不过会比较复杂。

卷积神经网络优缺点

关于卷积神经网络的基础内容就分享到这里,希望大家能有所收货。
码字不易,希望大家如果觉得“文”有所值,帮忙我转发一下吧,谢谢大家~



![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)









 京公网安备 11010802041100号
京公网安备 11010802041100号