作者:poohyxp | 来源:互联网 | 2022-01-13 01:03
这篇文章主要介绍了Scala之文件读取、写入、控制台操作的方法示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
Scala文件读取
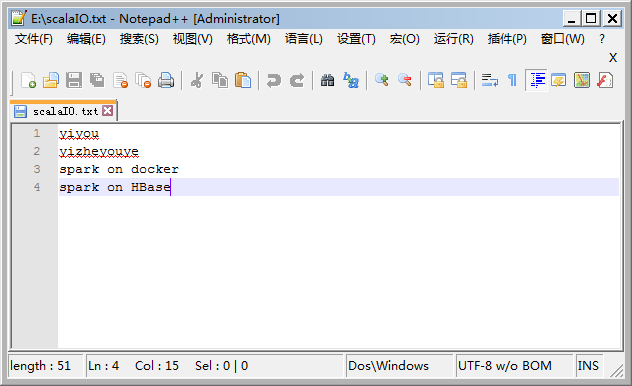
E盘根目录下scalaIO.txt文件内容如下:
文件读取示例代码:
//文件读取
val file=Source.fromFile("E:\\scalaIO.txt")
for(line <- file.getLines)
{
println(line)
}
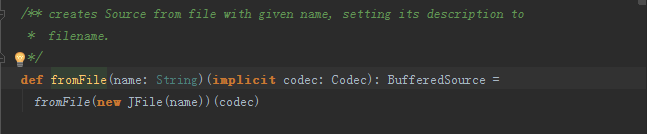
file.close

说明1:file=Source.fromFile(“E:\scalaIO.txt”),其中Source中的fromFile()方法源自 import scala.io.Source源码包,源码如下图:
file.getLines(),返回的是一个迭代器-Iterator;源码如下:(scala.io)

Scala 网络资源读取
//网络资源读取
val webFile=Source.fromURL("http://spark.apache.org")
webFile.foreach(print)
webFile.close()
fromURL()方法源码如下:
/** same as fromURL(new URL(s))
*/
def fromURL(s: String)(implicit codec: Codec): BufferedSource =
fromURL(new URL(s))(codec)
读取的网络资源资源内容如下:
Apache Spark™ is a fast and general engine for large-scale data processing.
Speed
Run programs up to 100x faster than
Hadoop MapReduce in memory, or 10x faster on disk.
Spark has an advanced DAG execution engine that supports cyclic data flow and
in-memory computing.

Logistic regression in Hadoop and Spark
Ease of Use
Write applications quickly in Java, Scala, Python, R.
Spark offers over 80 high-level operators that make it easy to build parallel apps.
And you can use it interactively
from the Scala, Python and R shells.
text_file = spark.textFile("hdfs://...")
text_file.flatMap(lambda line: line.split())
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a+b)
Word count in Spark's Python API
Generality
Combine SQL, streaming, and complex analytics.
Spark powers a stack of libraries including
SQL and DataFrames, MLlib for machine learning,
GraphX, and Spark Streaming.
You can combine these libraries seamlessly in the same application.
Runs Everywhere
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, or on Apache Mesos.
Access data in HDFS, Cassandra, HBase,
Hive, Tachyon, and any Hadoop data source.
Community
Spark is used at a wide range of organizations to process large datasets.
You can find example use cases at the Spark Summit
conference, or on the
Powered By
page.
There are many ways to reach the community:
Contributors
Apache Spark is built by a wide set of developers from over 200 companies.
Since 2009, more than 800 developers have contributed to Spark!
The project's
committers
come from 16 organizations.
If you'd like to participate in Spark, or contribute to the libraries on top of it, learn
how to
contribute.
Getting Started
Learning Spark is easy whether you come from a Java or Python background:
Process finished with exit code 0








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有