作者:hanhff | 来源:互联网 | 2023-09-13 14:49
本文重点介绍下如何在 Zeppelin 里高效的开发 PyFlink Job,特别是解决 PyFlink 的环境问题。
大家都知道PyFlink 的开发环境不容易搭建,稍有不慎,PyFlink 环境就会乱掉,而且很难排查原因
本文使用miniconda、conda-pack、mamba分别制作JobManager 上的 PyFlink Conda 环境、TaskManager 上的 PyFlink Conda 环境,然后在 Zeppelin 里使用 PyFlink 以及指定 Conda 环境,这样就可以在一个 Yarn 集群里同时使用多个版本的 PyFlink。
本文使用环境:flink 1.13.2, zeppelin:0.10.0-bin-all
需要改进的地方:
- 需要创建 2 个 conda env ,原因是 Zeppelin 支持 tar.gz 格式,而 Flink 只支持 zip 格式
- apache-flink 目前包含了 Flink 的 jar 包,导致打出来的 conda env 特别大(500MB以上),yarn container 在初始化的时候耗时会比较长,这个需要 Flink 社区提供一个轻量级的 Python 包 (不包含 Flink jar 包),就可以大大减小 conda env 的大小。
1. 搭建 PyFlink 环境
1.1.制作 JobManager 上的 PyFlink Conda 环境
- 注意dependencies所列的第三方包是在 PyFlink 客户端 (JobManager) 需要的包,比如 Matplotlib ,并且确保至少安装了所列的这些包:
- jupyter,grpcio,protobuf 是Zeppelin 需要的
- apache-flink 指定flink的版本
echo "name: pyflink_env
channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
dependencies:- Python=3.7- pip- pip:- apache-flink==1.13.2- jupyter- grpcio- protobuf- matplotlib- pandasql- pandas- scipy- seaborn- plotnine" > pyflink_env.ymlmamba env remove -n pyflink_env
mamba env create -f pyflink_env.ymlrm -rf pyflink_env.tar.gz
conda pack --ignore-missing-files -n pyflink_env -o pyflink_env.tar.gzhadoop fs -rmr /tmp/pyflink_env.tar.gz
hadoop fs -put pyflink_env.tar.gz /tmp
hadoop fs -chmod 644 /tmp/pyflink_env.tar.gz
1.2.制作 TaskManager 上的 PyFlink Conda 环境
echo "name: pyflink_tm_env
channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
dependencies:- Python=3.7- pip- pip:- apache-flink==1.13.2- pandas" > pyflink_tm_env.ymlmamba env remove -n pyflink_tm_env
mamba env create -f pyflink_tm_env.ymlrm -rf pyflink_tm_env.zip
conda pack --ignore-missing-files --zip-symlinks -n pyflink_tm_env -o pyflink_tm_env.ziphadoop fs -rmr /tmp/pyflink_tm_env.zip
hadoop fs -put pyflink_tm_env.zip /tmp
hadoop fs -chmod 644 /tmp/pyflink_tm_env.zip
1.3.安装本地的flink
下载 flink 1.13并解压,然后:
- 把 opt目录下的flink-python-*.jar 这个 jar 包 copy 到flink 的 lib 文件夹下;
- 把 opt/python 这个文件夹 copy 到flink 的 lib 文件夹下。
1.4. 在 PyFlink 中使用 Conda 环境
在 Zeppelin 里配置 Flink,主要配置的选项有:
- flink.execution.mode 为 yarn-application, 本文所讲的方法只适用于 yarn-application 模式;
- 指定 yarn.ship-archives,zeppelin.pyflink.Python 以及 zeppelin.interpreter.conda.env.name 来配置 JobManager 侧的 PyFlink Conda 环境;
- 指定 Python.archives 以及 Python.executable 来指定 TaskManager 侧的 PyFlink Conda 环境;
- 指定其他可选的 Flink 配置,比如这里的 flink.jm.memory 和 flink.tm.memory。
FLINK_HOME /data/flink/flink-1.13.2
HADOOP_CONF_DIR /etc/hadoop/conf
HIVE_CONF_DIR /etc/hive/conf
flink.execution.mode yarn-applicationzeppelin.pyflink.python pythonyarn.ship-archives /data/flink/pyflink_env.tar.gz
zeppelin.interpreter.conda.env.name pyflink_env.tar.gz
zeppelin.pyflink.Python pyflink_env.tar.gz/bin/python Python.archives hdfs://172.25.21.170:8020/tmp/pyflink_tm_env.zip
Python.executable pyflink_tm_env.zip/bin/python3.7 flink.jm.memory 2048
flink.tm.memory 2048zeppelin.interpreter.connect.timeout 600000
1.5. 使用示例
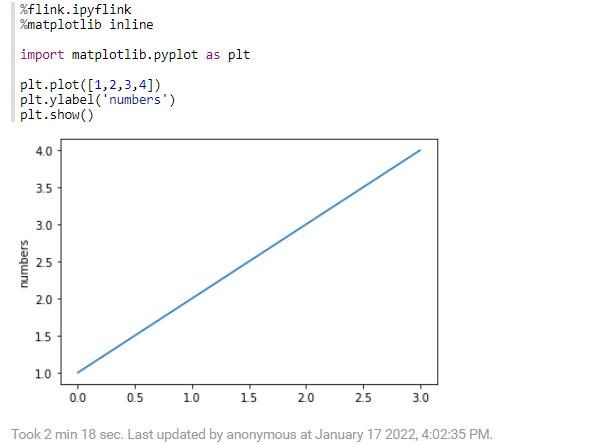
%flink.ipyflink
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot([1,2,3,4])
plt.ylabel('numbers')
plt.show()%flink.ipyflink
import time
class PandasVersion(ScalarFunction):def eval(self,s):import pandas as pdreturn pd.__version__ + " " + s
bt_env.register_funtion("pandas_version",udf(PandasVersion(),DataTypes.STRING,DataTypes.STRING)%bsql
select pandas_version('hello world')
附录
准备conda环境
在centos 7.x上安装miniconda
安装miniconda
miniconda是一个免费的conda最小安装程序。
它是Anaconda的一个小型的引导版本,只包含conda、Python、它们所依赖的包,以及少量其他有用的包,包括pip、zlib和其他一些包
下载并安装
根据实际需要,下载对应的版本,latest表示最新的python版本,是python3.9.5
- Miniconda3-py37_4.10.3-Linux64.sh
- Miniconda3-py38_4.10.3-Linux-x86_64.sh
- Miniconda3-py39_4.10.3-Linux-x86_64.sh
curl -O https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
检查环境配置
- 检查是否在文件尾添加如下内容
vi /root/.bashrc - 加载环境变量
source /root/.bashrc
__conda_setup="$('/data/flink/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; theneval "$__conda_setup"
elseif [ -f "/data/flink/miniconda3/etc/profile.d/conda.sh" ]; then. "/data/flink/miniconda3/etc/profile.d/conda.sh"elseexport PATH="/data/flink/miniconda3/bin:$PATH"fi
fi
unset __conda_setup
修改镜像地址
将镜像地址修改为国内源
通过如下命令检查配置
conda config --show 或 conda info
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --set show_channel_urls yes
default_channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
show_channel_urls: true
channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
安装conda-pack
conda-pack是一个命令行工具,用于创建conda环境的存档文件【archives 】,这些存档文件可以安装在其他系统上,这对于在一致的环境中部署代码非常有用。
安装
conda install -c conda-forge conda-pack
使用conda pack进行环境迁移
conda create -n py3.7 python=3.7
conda activate py3.7
conda deactivate
conda info -e
conda pack --n-threads=`nproc` -n py3.7
mkdir /home/test/miniconda3/envs/py3.7
tar -zxvf /tmp/py3.7.tar.gz -C /home/test/miniconda3/envs/py3.7
conda info -e
conda activate py3.7
mamba安装
mamba是c++中conda包管理器的重新实现,可以认为是更高级的conda。
有以下特点
- 使用多线程并行下载repository 数据和包文件,实现更高效的安装
- libsolv可以更快地解决依赖关系,libsolv是Red Hat、Fedora和OpenSUSE的RPM包管理器中使用的最新库
- mamba的核心部分是用c++实现的,以获得最大的效率
与此同时,mamba利用了相同的命令行解析器、包安装和卸载代码以及事务验证例程,以尽可能保持与conda的兼容性。
安装
conda install mamba -n base -c conda-forge
额外功能
- 查找软件包
mamba repoquery search "pandas>0.20.3" - 查看软件包的依赖(已安装软件包)
mamba repoquery depends --tree six - 查看软件包被谁依赖
mamba repoquery whoneeds openssl
切换pip镜像源
切换pip镜像源,加速软件包【如flink】的安装
创建或修改~/.pip/pip.conf文件
pip.conf文件的内容如下:
[global]
timeout = 6000
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
use-mirrors =true
mirrors =http://mirrors.aliyun.com/pypi/simple/
trusted-host =mirrors.aliyun.com
参考链接
Centos 安装 Miniconda
miniconda
conda-pack
mamba
Anaconda、Jupyter的安装部署及使用问题总结
python–切换pip镜像源,加速软件包的安装


![hive和mysql的区别是什么[mysql教程]](https://img1.php1.cn/3cd4a/25047/ae9/df36f34f7ab80f36.jpeg)



 京公网安备 11010802041100号
京公网安备 11010802041100号