作者介绍
杜艮魁,GraphQL Calculator作者,GraphQL Java 和GraphQL Spec Contributor。先后在美团、快手从事GraphQL的平台化开发。
问题背景
GraphQL对于数据的聚合治理和按需查询具有天然的优势,数据平台可将各个部门的数据映射到一张数据图上、即GraphQL的Schema,客户端可通过一次请求查询数据图中的多个资源。与传统sql不同,graphql经常是面向业务的,旨在提供可直接在页面展示的数据。
真实业务场景除了获取基础数据外,还会有业务定制的加工转换、请求控制和依赖数据编排。当前业界对数据的加工计算方案大致分为两种:
计算逻辑由客户端完成,或者在graphql之上构建计算层,本质上都是将计算任务交给其他系统模块负责;
使用schema指令加工后的数据映射为schema中的字段,典型如graphql-tools社区给出的方案。
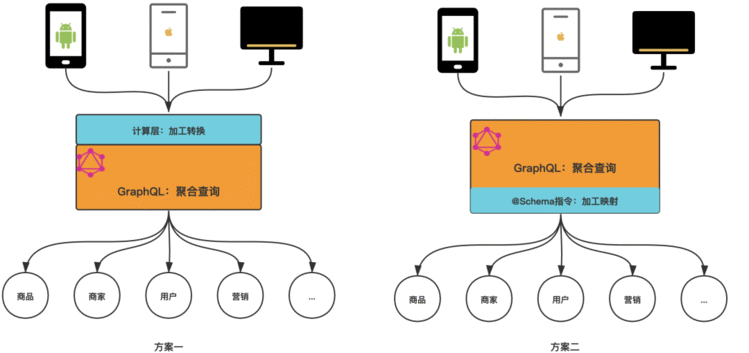
这两种方案存在如下问题:
将计算逻辑交由其他模块使得业务数据的产出链路变长,且对于数据之间存在依赖的情况仍然需要对GraphQL模块多次调用,实际上并没有解决GraphQL计算能力不足导致的硬编码加工问题;
使用schema指令将加工后的数据定义为Schema中的字段将导致业务计算和schema定义相耦合,数据图会存在噪声而变得难以维护。
本文从数据和算法分离的角度出发,对问题进行了分析拆解,并对基于查询指令的方案进行说明。
问题分析
GraphQL中的数据结构和算法
计算机科学家Niklaus Wirth提出程序=数据结构+算法,GraphQL系统也不例外。
很多GraphQL用户将查询仅仅视为Schema的子图、从数据图中匹配出要获取的数据,忽略了查询更是基于Schema数据结构的、对业务数据需求的算法描述,包括参数验证、数据聚合和计算处理等。GraphQL提供指令机制描述用户自定义的计算和验证行为,规范原文如下:
Directives provide a way to describe alternate runtime execution and type validation behavior in a GraphQL document.
In some cases, you need to provide options to alter GraphQL’s execution behavior in ways field arguments will not suffice, such as conditionally including or skipping a field. Directives provide this by describing additional information to the executor.
指令按照可用位置可分为schema指令和query指令,前者是对schema额外信息的描述,后者是对查询的描述,同一个指令可以既是schema指令、又是query指令。
正如前文所述,使用schema指令对业务计算进行描述会使得Schema定义存在噪声、增加Schema的维护难度。例如优惠价的展示,不同的业务场景需要转换为不同的文案,例如“优惠价95.50元”、“限时优惠¥95.50”、“神秘价¥*5.50元”等,这些处理后的数据不应该作为Schema中的字段存在。
我们通过query指令在查询层面定义产品需求要求的数据计算行为,对Schema中的数据做个性化的处理。
数据计算行为的归纳总结
任何复杂的业务处理都是基于基本的数据结构组合和有限的操作行为组合。针对读场景(也就是graphql的Query操作),我们对计算行为归纳如下:
字段加工:对结果数据进行加工处理,包括对列表的过滤、排序、去重。例如优惠价的不同展示文案、根据商品销量对商品列表进行排序等;
参数转换:包括参数整体转换,列表类型参数的过滤、转换等。例如将userId拼接为redis的key,过滤掉userIdList中为0的参数元素;
数据编排:当请求某一字段的参数来自同一查询其他字段的查询结果时,数据之间便存在需要编排的依赖关系。例如请求商品列表的参数来源于优惠券绑定的商品id列表,而grpahql查询变量只有券id;
控制流:根据请求变量或者其他字段结果判断是否请求某一字段。
解题思路
确认业务计算行为应该放在query指令中完成,并对计算行为进行归纳总结后,我们在简单分析GraphQL的执行引擎。
执行查询的本质是从Query节点开始,对其子节点进行遍历解析,并递归解析子孙节点,Query节点可理解为Schema数据图的根节点。GraphQL规范中详细描述了graphql的执行算法,详情参考sec-Execution。
GraphQL的java实现GraphQL Java基于CompatableFuture框架,对数据图进行了并行、异步的遍历处理,其Instrumentationj接口可获取查询执行各个阶段的运行时上下文、包括指令信息,并具备更改查询运行时行为和上下文数据的能力。可将其理解为GraphQL执行引擎的切面,其生效的位置包括查询的解析、验证以及每个数据节点的请求和完成过程。
综上,我们对查询计算问题做如下总结:
Schema作为GraphQL数据平台的“数据结构”,只应存在复用性强的领域数据,不可为具体业务做扩展;
查询作为描述业务所需数据和计算行为的“算法载体”,通过指令机制和Instrumentation系统为业务计算行为提供描述和实现;
业务涉及的数据类型和计算行为是有限的,可对其进行总结归纳,抽象为对数据图各元素的原子操作。
解决方案
以电商经典场景“优惠券去使用”为例,我们对基于查询指令的解决方案进行说明,该方案框架已落地为开源项目GraphQL Calculator。
项目地址:https://github.com/graphql-calculator/graphql-calculator
问题描述
产品需求
当用户点击店铺优惠券时跳转到优惠券承接页,承接页包括如下数据:
优惠券使用门槛描述文案,例如threshold==5000(分);couponAmout=30000(分)对应的描述文案为“以下商品可使用满300减50的优惠券”;
优惠券绑定的商品列表,列表按照销量降序排序;价格从“分”转换到“元文案”,例如price=18590分,则在客户端展示为“¥185.90”;
只有版本大于v10的客户端才展示商品标签。

优惠券信息是营销部门的服务接口,商品详情列表和商品标签是商品部门的两个服务接口。
传统方案
基于原生的graphql系统,客户端需要如下操作:
通过客户端版本计算出是否跳过商品标签获取布尔值参数,能力由graphql规范内置指令@skip支持;
获取优惠券详情,并解析优惠券绑定的商品id列表;
根据1、2结果同时请求商品基本信息、商品标签;
对数据做业务定制的处理,例如生成优惠券描述文案、商品排序、商品价格处理等。
业务方仍需要对数据进行繁杂的解析处理来弥补GraphQL原生查询计算能力的不足。
方案详情
基于问题分析,graphql定义一组查询指令用于数据的计算处理和编排控制,计算行为由计算引擎支持,默认使用aviatorscript。指令的名称和语义参考java.util.stream.Stream,易于理解和使用。如何优雅地扩展 GraphQL 系统能力 对基础指令的实现进行了说明。
参数处理&依赖编排
参数处理包括过滤掉无效参数,例如userIdList中为0的元素。而当需要将另外一个字段的结果作为入参时,两者存在依赖关系,例如该例中绑定了商品id列表的优惠券和商品详情列表。
GraphQL Calculator使用@argumentTransform和@fetchSource进行参数处理和编排依赖数据。@argumentTransform定义了对参数的加工转换,@fetchSource可将指定字段的解析器获取的结果作为其他计算指令可获取的上下文,详情可参考graphql-calculator#fetchsource。两者定义如下:
directive @fetchSource(name: String!, sourceConvert:String) on FIELDdirective @argumentTransform(argumentName:String!, operateType:ParamTransformType = MAP, expression:String, dependencySources:[String!]) on FIELDenum ParamTransformType{# 参数转换MAP # 列表类型参数过滤FILTER# 列表类型参数元素转换LIST_MAP
}
基于查询指令的方案与传统方案对比如下:前者省去了客户端的硬编码解析和二次调用。 
技术上,GraphQL Calculator框架会对基于指令的查询进行解析,识别@fetchSource注解的需要保存的数据,并在bindingItemIds节点和itemList节点之间建立依赖关系。在执行阶段会基于解析信息,保存上下文数据、并改变节点之间的调度关系。
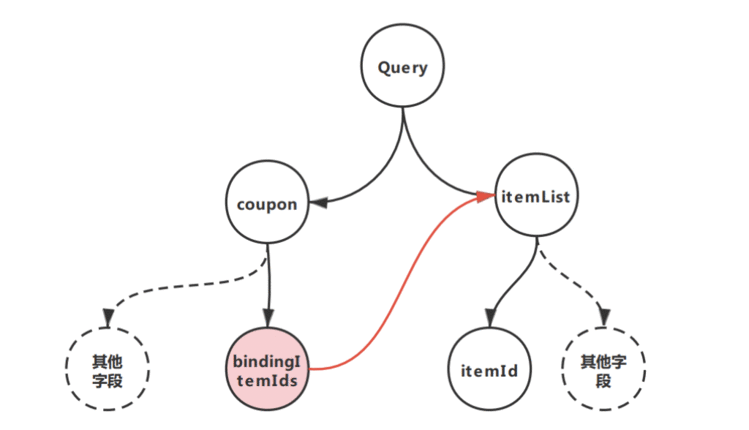
GraphQL Calculator提供了校验该指令集合法性的规则,对包括被编排的数据可能存在循环依赖的情况进行校验。对于@fetchSource 注解的节点,框架实际构造了对应的任务树,该例中为Query->coupon->bindingItemIds,来描述@fetchSource节点可能存在于数组中的情况,并解决父节点解析失败时依赖其数据的节点空等的问题。
加工转换&集合处理
数据的定制加工和列表的排序、过滤是产品需求中常见的计算逻辑。GraphQL Calculator参考java.util.stream.Stream,声明了 @map、@sortBy、@filter和@distinct对数据进行加工转换和对列表进行排序、过滤、去重。
以生成优惠券描述文案、对商品列表按照销量降序排序为例,查询如下:
query mapAndSortCase{coupon{threadHoldcouponAmountdesc @map(mapper:"'满'(threadHold/100)'减'(couponAmount/100)")}commodityList@sortBy(comparator:"soldAmount",isReversed:true){namepricesoldAmount}
}
当产品需求微调迭代时,修改查询指令表达式即可。如果出现两个并存的业务需要对数据进行不同的处理时,也只需拷贝查询语句、修改表达式,不用在开发计算逻辑。在实际应用中,查询指令对业务的快速迭代具有明显的帮助。
流程控制
有些需求随着客户端版本进行迭代,需要通过版本号决定是否请求某些字段,例如该例中的商品标签信息。GraphQL Calculator实现了内置指令 @skip 和 @include的扩展版本@skipBy和 @includeBy。与内置指令只可将布尔类型数据作为判断是否请求被注解字段的参数不同,@skipBy和 @includeBy可使用以查询变量为参数的表达式计算结果判断是否请求被注解的字段。示例如下:
query mapAndSortCase($clientVersion:String, ...){# ...commodityList# ...{namepricesoldAmount# 客户端版本号大于1.2.3时才会请求商品标签列表tagList @skipBy("greaterThan(clientVersion,'1.2.3')"){texticon}}
}
总结
相比于将计算逻辑交由其他模块系统,通过查询指令定义计算的优势如下:
快速响应:修改查询dsl即可,即时生效,无需编码、部署;
配置简单:指令命名和语义简单,基于结构化的查询dsl使得计算表意更加方便明确;
性能优势:通过查询指令在GraphQL引擎层面完成数据的加工调度,不用等待整个查询结束,且尽可能减少与客户端的交互次数;
解耦业务计算行为和领域数据定义:查询通过指令对要获取的数据和进行的加工行为进行直观的表示,Schema专注于领域数据治理。
在业务实践中,查询指令集可以轻易的覆盖80%以上的计算需求,很大程度上减少了业务方因为业务定制逻辑产生的硬编码解析计算工作。尤其是当产品需求没有过于定制的复杂逻辑或者产品逻辑微调时,只需配置查询语句即可满足数据和计算需求,不必在编码上线,实现了业务的快速迭代。
后记&感悟
重视提供能力
数据平台经常会同时对接很多产品需求,该因素决定了平台如果只是作为提供特定数据的部门存在,将会耗费大量时间精力进行业务的理解和对接。
建设者应关注到业务迭代时获取预期数据时遇到的问题,并将这些问题及其处理方案进行归纳,抽象为一种通用的能力提供给平台用户。相比于提供可复用的数据,有时候提供可复用的能力对数据平台更加重要。
将问题进行合理的抽象并实现为业务可用的通用能力,将能有效减少团队对接具体业务的工作量。
二八原则
将问题范围内80%工作的效率提升80%即是很有价值的提升,不必要求平台100%满足业务方的数据和能力需求。一味追求大而全可能导致过于复杂的系统设计、使得平台的理解和使用成本更加高昂,团队也可能要付出远超20%的时间成本去实现维护“剩下20%的能力”。
平台应该有明确的能力边界,在尝试对平台做能力拓展之前应该进行审慎地分析评估。能力扩展经常意味着数据结构的变化和维护成本的增加。
忠于业务
不同于学术研究,工程领域项目的建设往往始于一定的业务背景,平台的价值和意义最终都要回归到具体的业务问题上进行评估。
参考资料
[1] https://spec.graphql.org
[2] https://tech.meituan.com/2021/05/06/bff-graphql.html
[3] https://www.infoq.cn/article/uqQ20tkA6eELUQec4o97
[4] https://www.graphql-tools.com/docs/schema-directives
[5] https://www.graphql-java.com/documentation/v17/instrumentation
[6] https://www.graphql-java.com/blog/threads
[7] https://github.com/graphql-calculator/graphql-calculator
参考阅读:
百度信息流和搜索业务中的KV存储实践
如何优雅地记录操作日志?
爱奇艺本地实时Cache方案
Go 语言网络库 getty 的那些事
架构设计-复杂度是不灭的
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
高可用架构
改变互联网的构建方式








 京公网安备 11010802041100号
京公网安备 11010802041100号