挖了很久的CDC坑,今天打算填一填了。本文我们首先来介绍什么是CDC,以及CDC工具选型,接下来我们来介绍如何通过Flink CDC抓取mysql中的数据,并把他汇入Clickhouse里,最后我们还将介绍Flink SQL CDC的方式。
CDC首先什么是CDC ?它是Change Data Capture的缩写,即变更数据捕捉的简称,使用CDC我们可以从数据库中获取已提交的更改并将这些更改发送到下游,供下游使用。这些变更可以包括INSERT,DELETE,UPDATE等操作。

其主要的应用场景:
异构数据库之间的数据同步或备份 / 建立数据分析计算平台
微服务之间共享数据状态
更新缓存 / CQRS 的 Query 视图更新
CDC 它是一个比较广义的概念,只要能捕获变更的数据,我们都可以称为 CDC 。业界主要有基于查询的 CDC 和基于日志的 CDC ,可以从下面表格对比他们功能和差异点。
| 基于查询的 CDC | 基于日志的 CDC | |
|---|---|---|
| 概念 | 每次捕获变更发起 Select 查询进行全表扫描,过滤出查询之间变更的数据 | 读取数据存储系统的 log ,例如 MySQL 里面的 binlog持续监控 |
| 开源产品 | Sqoop, Kafka JDBC Source | Canal, Maxwell, Debezium |
| 执行模式 | Batch | Streaming |
| 捕获所有数据的变化 | ❌ | ✅ |
| 低延迟,不增加数据库负载 | ❌ | ✅ |
| 不侵入业务(LastUpdated字段) | ❌ | ✅ |
| 捕获删除事件和旧记录的状态 | ❌ | ✅ |
| 捕获旧记录的状态 | ❌ | ✅ |
Debezium是一个开源项目,为捕获数据更改(change data capture,CDC)提供了一个低延迟的流式处理平台。你可以安装并且配置Debezium去监控你的数据库,然后你的应用就可以消费对数据库的每一个行级别(row-level)的更改。只有已提交的更改才是可见的,所以你的应用不用担心事务(transaction)或者更改被回滚(roll back)。Debezium为所有的数据库更改事件提供了一个统一的模型,所以你的应用不用担心每一种数据库管理系统的错综复杂性。另外,由于Debezium用持久化的、有副本备份的日志来记录数据库数据变化的历史,因此,你的应用可以随时停止再重启,而不会错过它停止运行时发生的事件,保证了所有的事件都能被正确地、完全地处理掉。
ClickHouseDebezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong
实时数据分析数据库,俄罗斯的谷歌开发的,推荐OLAP场景使用
Clickhouse的优点.
真正的面向列的 DBMS
ClickHouse 是一个 DBMS,而不是一个单一的数据库。它允许在运行时创建表和数据库、加载数据和运行
查询,而无需重新配置和重新启动服务器。
数据压缩
一些面向列的 DBMS(InfiniDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实提高了性能。
磁盘存储的数据
在多个服务器上分布式处理
SQL支持
数据不仅按列存储,而且由矢量 - 列的部分进行处理,这使开发者能够实现高 CPU 性能
Clickhouse的缺点
没有完整的事务支持,
缺少完整的Update/Delete操作,缺少高频率、低延迟的修改或删除已存在数据的能力,仅能用于批量删
除或修改数据
聚合结果必须小于一台机器的内存大小:
不适合key-value存储,
什么时候不可以用Clickhouse?
事物性工作(OLTP)
高并发的键值访问
Blob或者文档存储
超标准化的数据
Flink cdc connector 消费 Debezium 里的数据,经过处理再sink出来,这个流程还是相对比较简单的
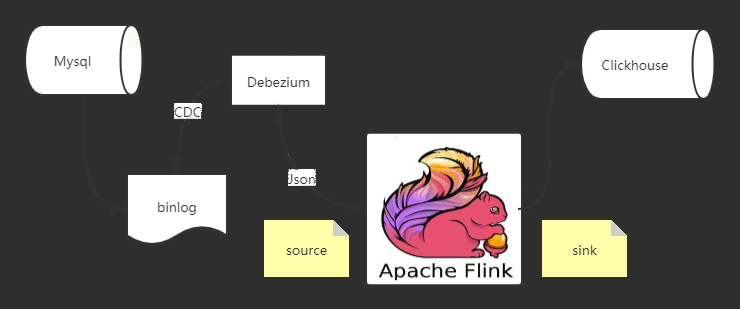
首先创建 Source 和 Sink(对应的依赖引用,在文末)
SourceFunction
这里用到的JsonDebeziumDeserializationSchema,是我们自定义的一个序列化类,用于将Debezium输出的数据,序列化
// 将cdc数据反序列化public static class JsonDebeziumDeserializationSchema implements DebeziumDeserializationSchema {@Overridepublic void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception {Gson jsstr = new Gson();HashMap
这里是将数据序列化成如下Json格式
{"database":"test","data":{"name":"jacky","description":"fffff","id":8},"type":"insert","table":"test_cdc"}
接下来就是要创建Sink,将数据变化存入Clickhouse中,这里我们仅以insert为例
public static class ClickhouseSink extends RichSinkFunction
完整代码案例:
package name.lijiaqi.cdc;import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import com.google.gson.Gson;
import com.google.gson.internal.LinkedTreeMap;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.source.SourceRecord;import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.util.HashMap;public class MySqlBinlogSourceExample {public static void main(String[] args) throws Exception {SourceFunction
}
执行查看结果
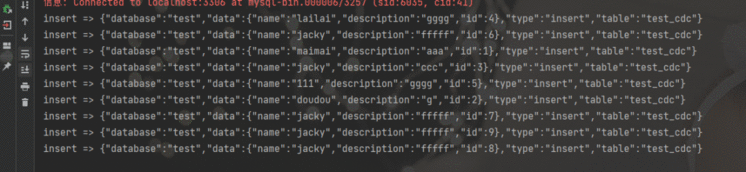
数据成功汇入
接下来,我们看一下如何通过Flink SQL实现CDC ,只需3条SQL语句即可。
创建数据源表
// 数据源表String sourceDDL ="CREATE TABLE mysql_binlog (\n" +" id INT NOT NULL,\n" +" name STRING,\n" +" description STRING\n" +") WITH (\n" +" 'connector' = 'mysql-cdc',\n" +" 'hostname' = 'localhost',\n" +" 'port' = '3306',\n" +" 'username' = 'flinkcdc',\n" +" 'password' = 'dafei1288',\n" +" 'database-name' = 'test',\n" +" 'table-name' = 'test_cdc'\n" +")";
创建输出表
// 输出目标表String sinkDDL ="CREATE TABLE test_cdc_sink (\n" +" id INT NOT NULL,\n" +" name STRING,\n" +" description STRING,\n" +" PRIMARY KEY (id) NOT ENFORCED \n " +") WITH (\n" +" 'connector' = 'jdbc',\n" +" 'driver' = 'com.mysql.jdbc.Driver',\n" +" 'url' = '" + url + "',\n" +" 'username' = '" + userName + "',\n" +" 'password' = '" + password + "',\n" +" 'table-name' = '" + mysqlSinkTable + "'\n" +")";
这里我们直接将数据汇入
// 简单的聚合处理String transformSQL ="insert into test_cdc_sink select * from mysql_binlog";
完整参考代码
package name.lijiaqi.cdc;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;public class MysqlToMysqlMain {public static void main(String[] args) throws Exception {EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, fsSettings);tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);// 数据源表String sourceDDL ="CREATE TABLE mysql_binlog (\n" +" id INT NOT NULL,\n" +" name STRING,\n" +" description STRING\n" +") WITH (\n" +" 'connector' = 'mysql-cdc',\n" +" 'hostname' = 'localhost',\n" +" 'port' = '3306',\n" +" 'username' = 'flinkcdc',\n" +" 'password' = 'dafei1288',\n" +" 'database-name' = 'test',\n" +" 'table-name' = 'test_cdc'\n" +")";String url = "jdbc:mysql://127.0.0.1:3306/test";String userName = "root";String password = "dafei1288";String mysqlSinkTable = "test_cdc_sink";// 输出目标表String sinkDDL ="CREATE TABLE test_cdc_sink (\n" +" id INT NOT NULL,\n" +" name STRING,\n" +" description STRING,\n" +" PRIMARY KEY (id) NOT ENFORCED \n " +") WITH (\n" +" 'connector' = 'jdbc',\n" +" 'driver' = 'com.mysql.jdbc.Driver',\n" +" 'url' = '" + url + "',\n" +" 'username' = '" + userName + "',\n" +" 'password' = '" + password + "',\n" +" 'table-name' = '" + mysqlSinkTable + "'\n" +")";// 简单的聚合处理String transformSQL ="insert into test_cdc_sink select * from mysql_binlog";tableEnv.executeSql(sourceDDL);tableEnv.executeSql(sinkDDL);TableResult result = tableEnv.executeSql(transformSQL);// 等待flink-cdc完成快照result.print();env.execute("sync-flink-cdc");}}
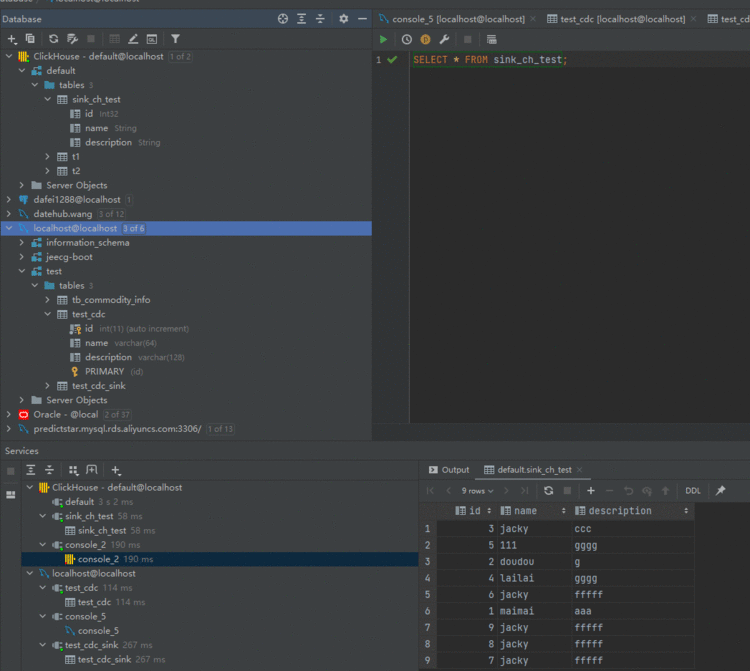
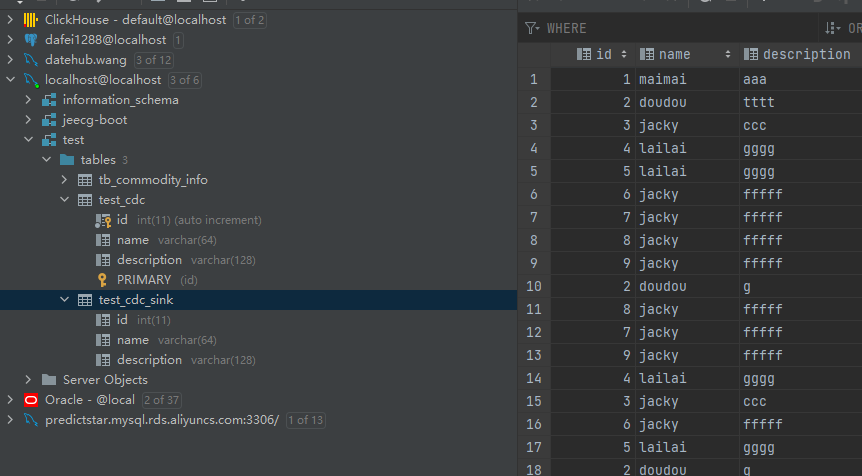
查看执行结果
添加依赖
参考链接:
https://blog.csdn.net/zhangjun5965/article/details/107605396
https://cloud.tencent.com/developer/article/1745233?from=article.detail.1747773
https://segmentfault.com/a/1190000039662261
https://www.cnblogs.com/weijiqian/p/13994870.html
《大数据成神之路》正在全面PDF化。
你只需要关注并在后台回复「PDF」就可以看到阿里云盘下载链接了!
另外我把发表过的文章按照体系全部整理好了。现在你可以在后台方便的进行查找:
电子版把他们分类做成了下面这个样子,并且放在了阿里云盘提供下载。
我们点开一个文件夹后:

如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!
Hi,我是王知无,一个大数据领域的原创作者。
放心关注我,获取更多行业的一手消息。


八千里路云和月 | 从零到大数据专家学习路径指南
互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有