from pyhdfs import HdfsClient
client=HdfsClient(hosts='ghym:50070')#hdfs地址
res=client.open('/sy.txt')#hdfs文件路径,根目录/
for r in res:
line=str(r,encoding='utf8')#open后是二进制,str()转换为字符串并转码
print(line)
写文件代码如下
from pyhdfs import HdfsClient
client=HdfsClient(hosts='ghym:50070',user_name='hadoop')#只有hadoop用户拥有写权限
str='hello world'
client.create('/py.txt',str)#创建新文件并写入字符串
上传本地文件到HDFS
from pyhdfs import HdfsClient
client = HdfsClient(hosts='ghym:50070', user_name='hadoop')
client.copy_from_local('d:/pydemo.txt', '/pydemo')#本地文件绝对路径,HDFS目录必须不存在
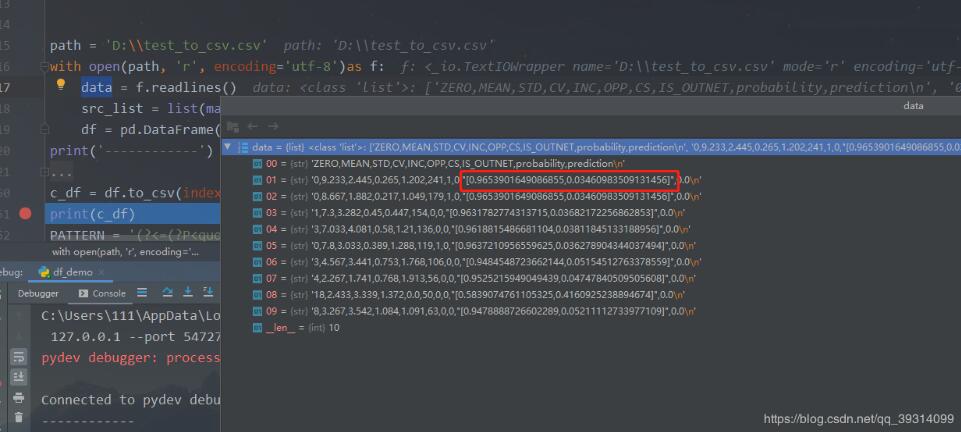

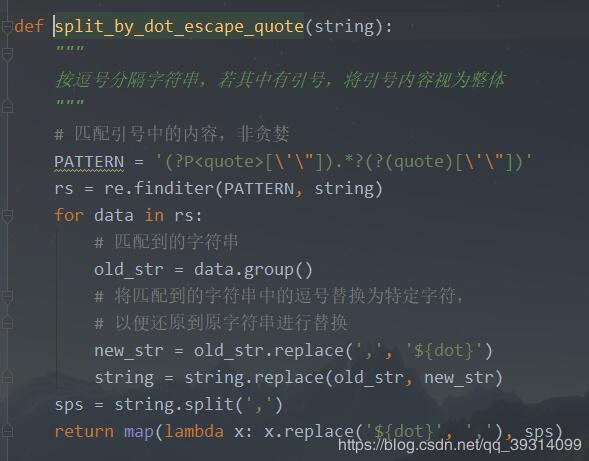
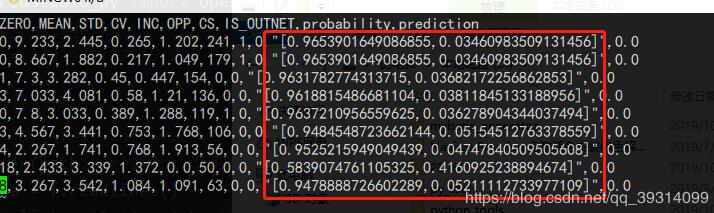
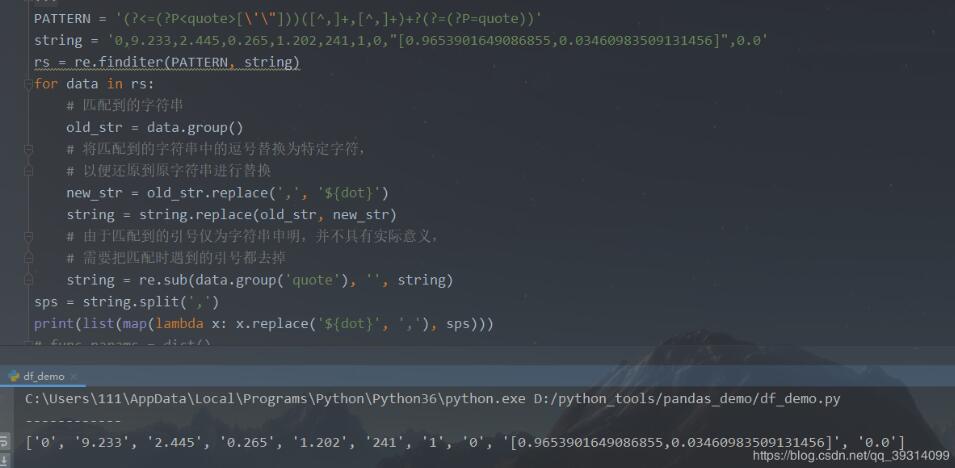







 京公网安备 11010802041100号
京公网安备 11010802041100号