【1x00】提取所有二手车详情页URL
分析页面,按照习惯,最开始在 headers 里面只加入 User-Agent 字段,向主页发送请求,然而返回的东西并不是主页真正的源码,因此我们加入 COOKIE,再次发起请求,即可得到真实数据。
获取 COOKIE:打开浏览器访问网站,打开开发工具,切换到 Network 选项卡,筛选 Doc 文件,在 Request Headers 里可以看到 COOKIE 值。
注意在爬取瓜子二手车的时候,User-Agent 与 COOKIE 要对应一致,也就是直接复制 Request Headers 里的 User-Agent 和 COOKIE,不要自己定义一个 User-Agent,不然有可能获取不到信息!

分析页面,请求地址为:https://www.guazi.com/www/buy/
第一页:https://www.guazi.com/www/buy/
第二页:https://www.guazi.com/www/buy/o2c-1/
第三页:https://www.guazi.com/www/buy/o3c-1/
一共有50页数据,利用 for 循环,每次改变 URL 中 o2c-1 参数里面的数字即可实现所有页面的爬取,由于我们是想爬取每台二手车详情页的数据,所以定义一个 parse_index() 函数,提取每一页的所有详情页的 URL,保存在列表 url_list 中
# 必须要有 COOKIE 和 User-Agent,且两者必须对应(用浏览器访问网站后控制台里面复制)
headers = {
'COOKIE': 'uuid=06ce7520-ebd1-45bc-f41f-a95f2c9b2283; ganji_uuid=7044571161649671972745; lg=1; clueSourceCode=%2A%2300; user_city_id=-1; sessiOnid=fefbd4f8-0a06-4e8a-dc49-8856e1a02a07; Hm_lvt_936a6d5df3f3d309bda39e92da3dd52f=1573469368,1573541270,1573541964,1573715863; close_finance_popup=2019-11-14; cainfo=%7B%22ca_a%22%3A%22-%22%2C%22ca_b%22%3A%22-%22%2C%22ca_s%22%3A%22seo_baidu%22%2C%22ca_n%22%3A%22default%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22-%22%2C%22ca_content%22%3A%22-%22%2C%22ca_campaign%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22scode%22%3A%22-%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%22-%22%2C%22display_finance_flag%22%3A%22-%22%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%2206ce7520-ebd1-45bc-f41f-a95f2c9b2283%22%2C%22ca_city%22%3A%22wh%22%2C%22sessionid%22%3A%22fefbd4f8-0a06-4e8a-dc49-8856e1a02a07%22%7D; _gl_tracker=%7B%22ca_source%22%3A%22-%22%2C%22ca_name%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_id%22%3A%22-%22%2C%22ca_s%22%3A%22self%22%2C%22ca_n%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22sid%22%3A56473912809%7D; cityDomain=www; preTime=%7B%22last%22%3A1573720945%2C%22this%22%3A1573469364%2C%22pre%22%3A1573469364%7D; Hm_lpvt_936a6d5df3f3d309bda39e92da3dd52f=1573720946; rfnl=https://www.guazi.com/www/chevrolet/i2c-1r18/; antipas=675i0t513a7447M2L9y418Qq869',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
# 获取所有二手车详情页URL
def parse_index():
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
url_list = tree.xpath('//li/a[@class="car-a"]/@href')
# print(len(url_list))
return url_list
if __name__ == '__main__':
for i in range(1, 51):
url = 'https://www.guazi.com/www/buy/o%sc-1/' % i
detail_urls = parse_index()
【2x00】获取二手车详细信息并保存图片
前面的第一步我们已经获取到了二手车详情页的 URL,现在定义一个 parse_detail() 函数,向其中循环传入每一条 URL,利用 Xpath 语法匹配每一条信息,所有信息包含:标题、二手车价格、新车指导价、车主、上牌时间、表显里程、上牌地、排放标准、变速箱、排量、过户次数、看车地点、年检到期、交强险、商业险到期。
其中有部分信息可能包含空格,可以用 strip() 方法将其去掉。
需要注意的是,上牌地对应的是一个 class="three" 的 li 标签,有些二手车没有上牌地信息,匹配的结果将是空,在数据储存时就有可能出现数组越界的错误信息,所以这里可以加一个判断,如果没有上牌地信息,可以将其赋值为:未知。
保存车辆图片时,为了节省时间和空间,避免频繁爬取被封,所以只保存第一张图片,同样利用 Xpath 匹配到第一张图片的地址,以标题为图片的名称,定义储存路径后,以二进制形式保存图片。
最后整个函数返回的是一个列表 data,这个列表包含每辆二手车的所有信息
# 获取二手车详细信息
def parse_detail(content):
detail_response = requests.get(url=content, headers=headers)
tree = etree.HTML(detail_response.text)
# 标题
title = tree.xpath('//h2[@class="titlebox"]/text()')
# 移除字符串头尾空格
title = [t.strip() for t in title]
# 匹配到两个元素,只取其中一个为标题
title = title[:1]
# print(title)
# 价格
price_old = tree.xpath('//span[@class="pricestype"]/text()')
# 移除字符串头尾空格
price_old = [p.strip() for p in price_old]
# 加入单位
price_old = [''.join(price_old + ['万'])]
# print(price_old)
# 新车指导价
price_new = tree.xpath('//span[@class="newcarprice"]/text()')
# 移除字符串头尾空格
price_new = [p.strip() for p in price_new]
# 对字符串进行切片,只取数字多少万
price_new = ['¥' + price_new[0].split('价')[1]]
# print(price_new)
# 车主
owner = tree.xpath('//dl/dt/span/text()')
owner = [owner[0].replace('车主:', '')]
# print(owner)
# 上牌时间
spsj = tree.xpath('//li[@class="one"]/div/text()')
# print(spsj)
# 表显里程
bxlc = tree.xpath('//li[@class="two"]/div/text()')
# print(bxlc)
# 上牌地
spd = tree.xpath('//li[@class="three"]/div/text()')
# 某些二手车没有上牌地,没有的将其赋值为:未知
if len(spd) == 0:
spd = ['未知']
# print(spd)
# 排放标准
pfbz = tree.xpath('//li[@class="four"]/div/text()')
pfbz = pfbz[:1]
# print(pfbz)
# 变速箱
bsx = tree.xpath('//li[@class="five"]/div/text()')
# print(bsx)
# 排量
pl = tree.xpath('//li[@class="six"]/div/text()')
# print(pl)
# 过户次数
ghcs = tree.xpath('//li[@class="seven"]/div/text()')
ghcs = [g.strip() for g in ghcs]
ghcs = ghcs[:1]
# print(ghcs)
# 看车地点
kcdd = tree.xpath('//li[@class="eight"]/div/text()')
# print(kcdd)
# 年检到期
njdq = tree.xpath('//li[@class="nine"]/div/text()')
# print(njdq)
# 交强险
jqx = tree.xpath('//li[@class="ten"]/div/text()')
# print(jqx)
# 商业险到期
syxdq = tree.xpath('//li[@class="last"]/div/text()')
syxdq = [s.strip() for s in syxdq]
syxdq = syxdq[:1]
# print(syxdq)
# 保存车辆图片
# 获取图片地址
pic_url = tree.xpath('//li[@class="js-bigpic"]/img/@data-src')[0]
pic_response = requests.get(pic_url)
# 定义图片名称以及保存的文件夹
pic_name = title[0] + '.jpg'
dir_name = 'guazi_pic'
# 如果没有该文件夹则创建该文件夹
if not os.path.exists(dir_name):
os.mkdir(dir_name)
# 定义储存路径
pic_path = dir_name + '/' + pic_name
with open(pic_path, "wb")as f:
f.write(pic_response.content)
# 将每辆二手车的所有信息合并为一个列表
data = title + price_old + price_new + owner + spsj + bxlc + spd + pfbz + bsx + pl + ghcs + kcdd + njdq + jqx + syxdq
return data
if __name__ == '__main__':
for i in range(1, 51):
url = 'https://www.guazi.com/www/buy/o%sc-1/' % i
detail_urls = parse_index()
for detail_url in detail_urls:
car_url = 'https://www.guazi.com' + detail_url
car_data = parse_detail(car_url)
【3x00】将数据储存到 MongoDB
定义数据储存函数 save_data()
使用 MongoClient() 方法,向其传入地址参数 host 和 端口参数 port,指定数据库为 guazi,集合为 esc
传入第二步 parse_detail() 函数返回的二手车信息的列表,依次读取其中的元素,每一个元素对应相应的信息名称
最后调用 insert_one() 方法,每次插入一辆二手车的数据
# 将数据储存到 MongoDB
def save_data(data):
client = pymongo.MongoClient(host='localhost', port=27017)
db = client.guazi
collection = db.esc
esc = {
'标题': data[0],
'二手车价格': data[1],
'新车指导价': data[2],
'车主': data[3],
'上牌时间': data[4],
'表显里程': data[5],
'上牌地': data[6],
'排放标准': data[7],
'变速箱': data[8],
'排量': data[9],
'过户次数': data[10],
'看车地点': data[11],
'年检到期': data[12],
'交强险': data[13],
'商业险到期': data[14]
}
collection.insert_one(esc)
if __name__ == '__main__':
for i in range(1, 51):
url = 'https://www.guazi.com/www/buy/o%sc-1/' % i
detail_urls = parse_index()
for detail_url in detail_urls:
car_url = 'https://www.guazi.com' + detail_url
car_data = parse_detail(car_url)
save_data(car_data)
# 在3-10秒之间随机暂停
time.sleep(random.randint(3, 10))
time.sleep(random.randint(5, 60))
print('所有数据爬取完毕!')
【4x00】完整代码
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2019-11-14
# @Author : TRHX
# @Blog : www.itrhx.com
# @CSDN : https://blog.csdn.net/qq_36759224
# @FileName: guazi.py
# @Software: PyCharm
# =============================================
from lxml import etree
import requests
import pymongo
import time
import random
import os
# 必须要有 COOKIE 和 User-Agent,且两者必须对应(用浏览器访问网站后控制台里面复制)
headers = {
'COOKIE': 'uuid=06ce7520-ebd1-45bc-f41f-a95f2c9b2283; ganji_uuid=7044571161649671972745; lg=1; clueSourceCode=%2A%2300; user_city_id=-1; sessiOnid=fefbd4f8-0a06-4e8a-dc49-8856e1a02a07; Hm_lvt_936a6d5df3f3d309bda39e92da3dd52f=1573469368,1573541270,1573541964,1573715863; close_finance_popup=2019-11-14; cainfo=%7B%22ca_a%22%3A%22-%22%2C%22ca_b%22%3A%22-%22%2C%22ca_s%22%3A%22seo_baidu%22%2C%22ca_n%22%3A%22default%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22-%22%2C%22ca_content%22%3A%22-%22%2C%22ca_campaign%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22scode%22%3A%22-%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%22-%22%2C%22display_finance_flag%22%3A%22-%22%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%2206ce7520-ebd1-45bc-f41f-a95f2c9b2283%22%2C%22ca_city%22%3A%22wh%22%2C%22sessionid%22%3A%22fefbd4f8-0a06-4e8a-dc49-8856e1a02a07%22%7D; _gl_tracker=%7B%22ca_source%22%3A%22-%22%2C%22ca_name%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_id%22%3A%22-%22%2C%22ca_s%22%3A%22self%22%2C%22ca_n%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22sid%22%3A56473912809%7D; cityDomain=www; preTime=%7B%22last%22%3A1573720945%2C%22this%22%3A1573469364%2C%22pre%22%3A1573469364%7D; Hm_lpvt_936a6d5df3f3d309bda39e92da3dd52f=1573720946; rfnl=https://www.guazi.com/www/chevrolet/i2c-1r18/; antipas=675i0t513a7447M2L9y418Qq869',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
# 获取所有二手车详情页URL
def parse_index():
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
url_list = tree.xpath('//li/a[@class="car-a"]/@href')
# print(len(url_list))
return url_list
# 获取二手车详细信息
def parse_detail(content):
detail_response = requests.get(url=content, headers=headers)
tree = etree.HTML(detail_response.text)
# 标题
title = tree.xpath('//h2[@class="titlebox"]/text()')
# 移除字符串头尾空格
title = [t.strip() for t in title]
# 匹配到两个元素,只取其中一个为标题
title = title[:1]
# print(title)
# 价格
price_old = tree.xpath('//span[@class="pricestype"]/text()')
# 移除字符串头尾空格
price_old = [p.strip() for p in price_old]
# 加入单位
price_old = [''.join(price_old + ['万'])]
# print(price_old)
# 新车指导价
price_new = tree.xpath('//span[@class="newcarprice"]/text()')
# 移除字符串头尾空格
price_new = [p.strip() for p in price_new]
# 对字符串进行切片,只取数字多少万
price_new = ['¥' + price_new[0].split('价')[1]]
# print(price_new)
# 车主
owner = tree.xpath('//dl/dt/span/text()')
owner = [owner[0].replace('车主:', '')]
# print(owner)
# 上牌时间
spsj = tree.xpath('//li[@class="one"]/div/text()')
# print(spsj)
# 表显里程
bxlc = tree.xpath('//li[@class="two"]/div/text()')
# print(bxlc)
# 上牌地
spd = tree.xpath('//li[@class="three"]/div/text()')
# 某些二手车没有上牌地,没有的将其赋值为:未知
if len(spd) == 0:
spd = ['未知']
# print(spd)
# 排放标准
pfbz = tree.xpath('//li[@class="four"]/div/text()')
pfbz = pfbz[:1]
# print(pfbz)
# 变速箱
bsx = tree.xpath('//li[@class="five"]/div/text()')
# print(bsx)
# 排量
pl = tree.xpath('//li[@class="six"]/div/text()')
# print(pl)
# 过户次数
ghcs = tree.xpath('//li[@class="seven"]/div/text()')
ghcs = [g.strip() for g in ghcs]
ghcs = ghcs[:1]
# print(ghcs)
# 看车地点
kcdd = tree.xpath('//li[@class="eight"]/div/text()')
# print(kcdd)
# 年检到期
njdq = tree.xpath('//li[@class="nine"]/div/text()')
# print(njdq)
# 交强险
jqx = tree.xpath('//li[@class="ten"]/div/text()')
# print(jqx)
# 商业险到期
syxdq = tree.xpath('//li[@class="last"]/div/text()')
syxdq = [s.strip() for s in syxdq]
syxdq = syxdq[:1]
# print(syxdq)
# 保存车辆图片
# 获取图片地址
pic_url = tree.xpath('//li[@class="js-bigpic"]/img/@data-src')[0]
pic_response = requests.get(pic_url)
# 定义图片名称以及保存的文件夹
pic_name = title[0] + '.jpg'
dir_name = 'guazi_pic'
# 如果没有该文件夹则创建该文件夹
if not os.path.exists(dir_name):
os.mkdir(dir_name)
# 定义储存路径
pic_path = dir_name + '/' + pic_name
with open(pic_path, "wb")as f:
f.write(pic_response.content)
# 将每辆二手车的所有信息合并为一个列表
data = title + price_old + price_new + owner + spsj + bxlc + spd + pfbz + bsx + pl + ghcs + kcdd + njdq + jqx + syxdq
return data
# 将数据储存到 MongoDB
def save_data(data):
client = pymongo.MongoClient(host='localhost', port=27017)
db = client.guazi
collection = db.esc
esc = {
'标题': data[0],
'二手车价格': data[1],
'新车指导价': data[2],
'车主': data[3],
'上牌时间': data[4],
'表显里程': data[5],
'上牌地': data[6],
'排放标准': data[7],
'变速箱': data[8],
'排量': data[9],
'过户次数': data[10],
'看车地点': data[11],
'年检到期': data[12],
'交强险': data[13],
'商业险到期': data[14]
}
collection.insert_one(esc)
if __name__ == '__main__':
for i in range(1, 51):
num = 0
print('正在爬取第' + str(i) + '页数据...')
url = 'https://www.guazi.com/www/buy/o%sc-1/' % i
detail_urls = parse_index()
for detail_url in detail_urls:
car_url = 'https://www.guazi.com' + detail_url
car_data = parse_detail(car_url)
save_data(car_data)
num += 1
print('第' + str(num) + '条数据爬取完毕!')
# 在3-10秒之间随机暂停
time.sleep(random.randint(3, 10))
print('第' + str(i) + '页数据爬取完毕!')
print('=====================')
time.sleep(random.randint(5, 60))
print('所有数据爬取完毕!')
【5x00】数据截图
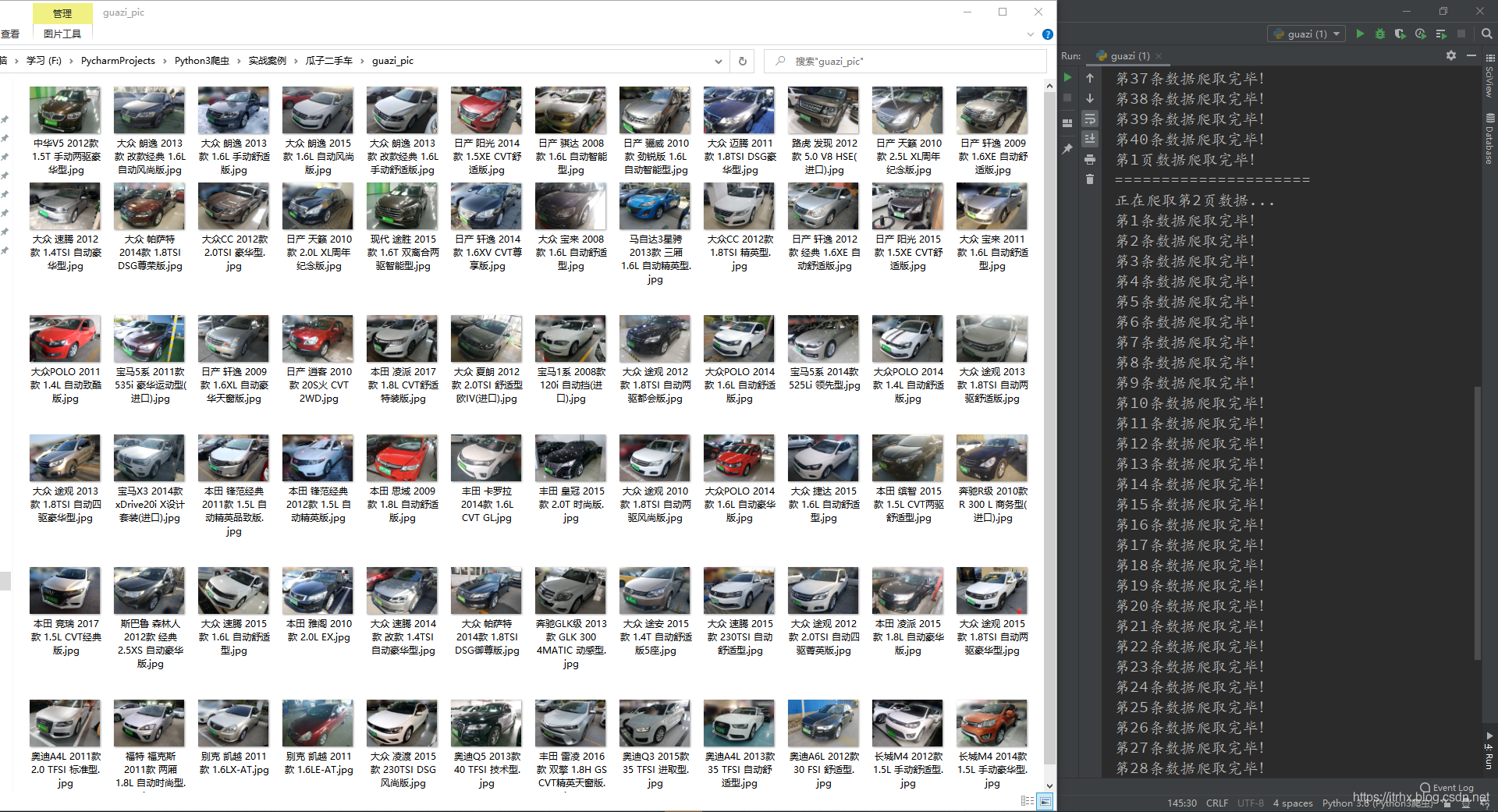
爬取的汽车图片:
储存到 MongoDB 的数据: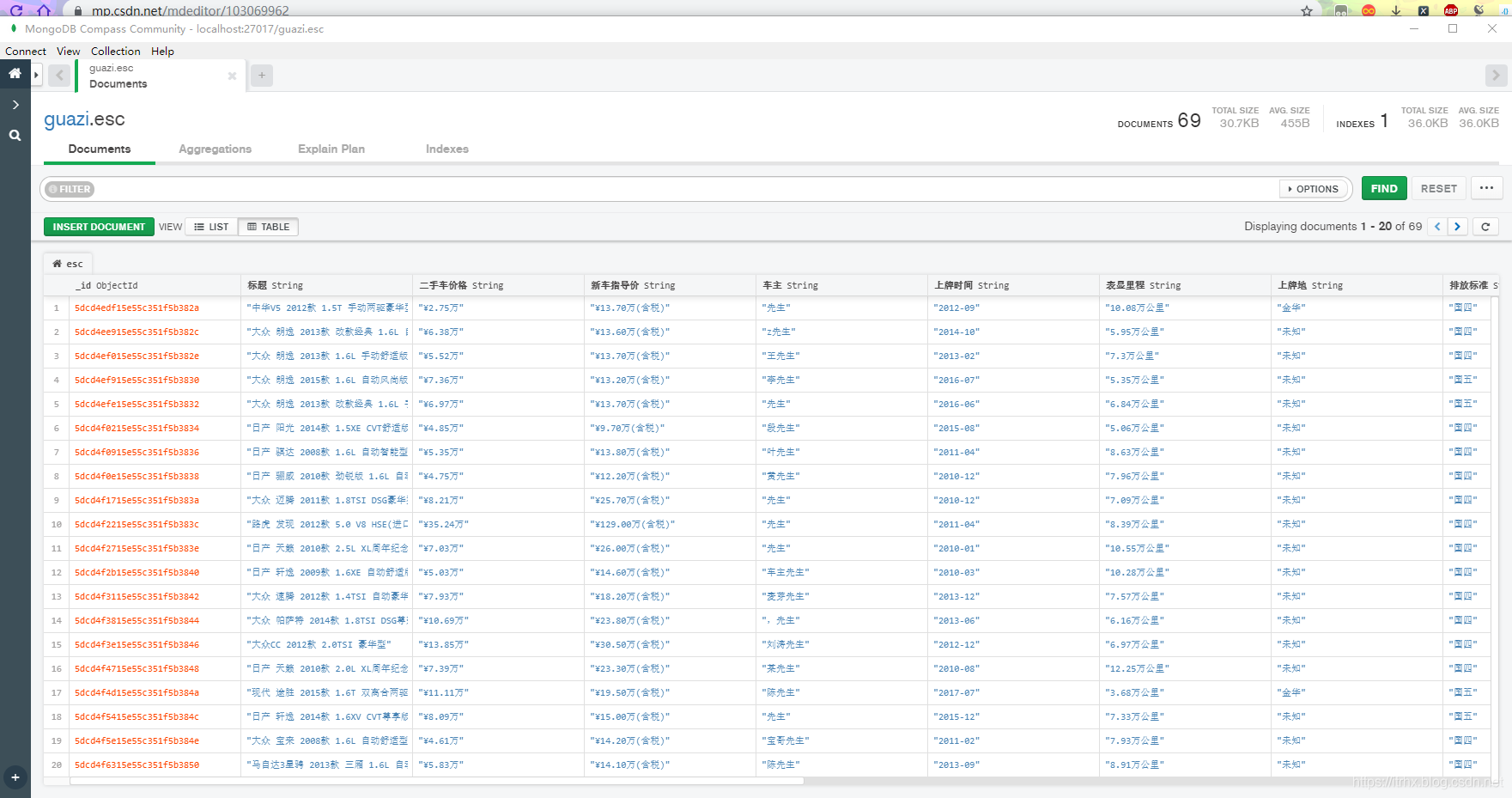
数据导出为 CSV 文件: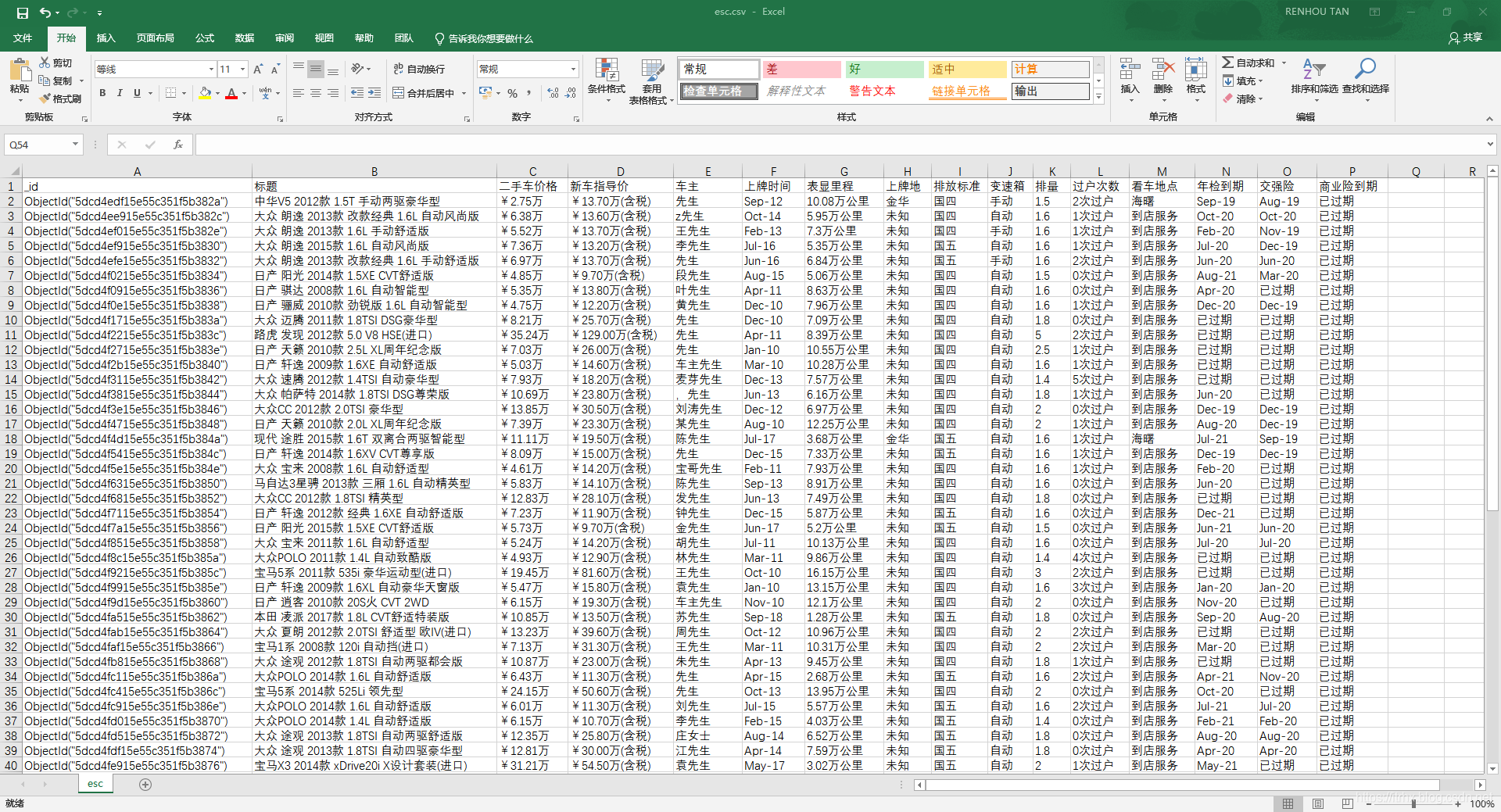
【6x00】程序不足的地方
COOKIE 过一段时间就会失效,数据还没爬取完就失效了,导致无法继续爬取;爬取效率不高,可以考虑多线程爬取







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有