作者:shamrock-wrh_186 | 来源:互联网 | 2022-11-30 12:26
这是我的csv外观,
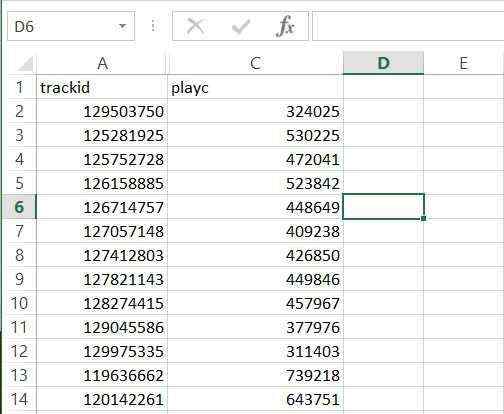
name, cuisine, review
A, Chinese, this
A, Indian, is
B, Indian, an
B, Indian, example
B, French, thank
C, French, you
我试着计算这种差异菜肴的名称出现次数.这就是我应该得到的
Cuisine, Count
Chinese, 1
Indian, 2
French, 2
但正如你可以看到名称中有重复项,例如B,所以我尝试drop_duplicates但我不能.我用
df.groupby('name')['cuisine'].drop_duplicates()
它说系列groupby对象不能.
不知何故,我需要应用value_counts()来获取烹饪单词的出现次数,但重复的东西是阻碍的.知道如何在熊猫中得到这个吗?谢谢.







 京公网安备 11010802041100号
京公网安备 11010802041100号