作者:100斤的重口味_866 | 来源:互联网 | 2023-10-17 16:00
网站类应用,一定离不开MySQL,所以本案例将带着大家学习一下,通过Flask调用MySQL数据,并实现分页呈现。类被称作蓝图,它是一个存储操作方法的容器,Flask可以通过Blu
文章目录
Python Flask 调用 MySQL 数据建立新的控制器目录爬虫训练场引入 MySQL 之间的逻辑关系搭建案例前端页面 本篇博客为大家继续补充一款简易爬虫,主要涉及如下知识点。
- Python Flask 调用 MySQL 数据
- 分页数据呈现
Python Flask 调用 MySQL 数据
网站类应用,一定离不开 MySQL ,所以本案例将带着大家学习一下,通过 Flask 调用 MySQL 数据,并实现分页呈现。
正式开始前,我们需要提前在 MySQL 中准备一张表,命名为 school_list,其数据通过采集获取,具体可参考博客《【Python 实战】高校数据采集,爬虫训练场项目数据储备》。
安装 MySQL 操作相关模块。
pip install flask-sqlalchemy
使用 Pycharm 安装,可直接在包管理中进行检索。
新建 config.py 文件,并输入如下代码
class BaseConfig(object):
DIALECT = 'mysql'
DRIVER = 'pymysql'
USERNAME = 'root'
PASSWORD = 'root' # 注意不要泄露服务器密码,这里仅供测试使用
HOST = '127.0.0.1'
PORT = '3306'
DATABASE = 'playground'
SQLALCHEMY_DATABASE_URI = "{}+{}://{}:{}@{}:{}/{}?charset=utf8".format(DIALECT, DRIVER, USERNAME, PASSWORD, HOST,
PORT, DATABASE)
SQLALCHEMY_TRACK_MODIFICATIONS = False
SQLALCHEMY_ECHO = True
可以看到用户名和密码都在该文件中进行配置,接下来在 app/__init__.py 文件中导入对应模块。
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
接下来我们先补充一些小知识点,罗列如下所示。
app.config.from_object() 方法,它用来加载配置文件,稍后将用该方法导入数据库相关配置。
下面继续看一段代码。
db = SQLAlchemy()
db.init_app(app) # 初始化数据库
db = SQLAlchemy() 用于创建 SQLAlchemy 对象,db.init_app() 初始化链接对象。
建立新的控制器目录
在 app 目录下建立 school 文件夹,然后内部新增两个文件,分别是 __init__.py 和 index.py,然后在 index.py 文件中,输入如下代码。
import sys
from flask import Blueprint, jsonify
from ..model import School # 导入上级模块
ss = Blueprint('school', __name__)
@school.route('/list')
def list_school():
schools = School.query.all()
print(schools)
先不要运行项目,我们先说明一下其中涉及的知识点,第一个是 Blueprint 类。
Blueprint 类被称作蓝图,它是一个存储操作方法的容器,Flask 可以通过 Blueprint 来组织 URL 及处理请求。
蓝图对象和 Flask 对象使用类似,但需要将其注册到应用对象上才可以生效。
使用蓝图的三个步骤。
创建一个蓝图对象
s = Blueprint('school', __name__,url_prifix='/ss')
在蓝图对象上进行操作,例如注册路由,指定静态文件,指定过滤器
@ss.route('/list')
def list_school():
schools = School.query.all()
print(schools)
return "学校数据"
在应用对象注册蓝图对象
返回到 app/__init__.py 文件中,注册蓝图对象。
from .school.index import *
app.register_blueprint(s)
在应用对象上注册一个蓝图时,可以指定 url_prefix 关键字参数(该参数默认是 /),此时启动项目,就可以通过 /ss/ 配合路由,访问指定方法。
在前文代码中,我们还导入了一个 model 模型模块,在 app 目录中建立 model.py 文件,然后输入如下代码。
from app import db
class EntityBase(object):
def to_json(self):
fields = self.__dict__
if "_sa_instance_state" in fields:
del fields["_sa_instance_state"]
return fields
class School(db.Model, EntityBase):
"""
表名,字段名
"""
__tablename__ = "school_list"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(255))
province = db.Column(db.String(255))
city = db.Column(db.String(255))
feature = db.Column(db.String(255))
hotValue = db.Column(db.String(255))
pic = db.Column(db.String(255))
category = db.Column(db.String(255))
batchTimes = db.Column(db.String(255))
其中 School 类继承自 db.Model 和 EntityBase,其中的字段与数据库表字段一致。
接下来再总结一下目前的项目结构,然后橡皮擦会带着大家再次梳理一下各文件之间的引用关系。
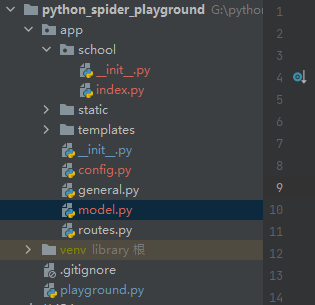
爬虫训练场引入 MySQL 之间的逻辑关系
playground.py 文件为程序主入口,其内部导入 app 模块,由于 Python 模块导入关系,app 目录中的 __init__.py 文件默认执行。
__init__.py 文件中包含如下内容:
flask 主类初始化;app 配置文件初始化;SQLAlchemy 类初始化;各路由导入+蓝图注册。由于需要导入 app 配置,所以这里需要导入 config.py 文件,由于需要导入路由控制器和注册蓝图,所以需要编写下述代码。
from app import routes
from app import general
from .school.index import *
app.register_blueprint(s)
为了便于项目管理,在 app 目录中新建立了一个 school 文件夹,并且创建了一个 index.py 文件,用于实现路由函数逻辑,由于该文件需要使用模型 model 相关配置,所以在 app 目录新增一个 model.py 文件,并且实现了第一个模型类 School。
搭建案例前端页面
本篇博客的最后一个步骤,用来实现前端页面渲染,在 templates 目录建立一个 school 文件夹,并新建 index.html 文件,其中先输入一个 Bootstrap 基本内容即可。
打开 app/school/index.py 文件,修改 list_school() 函数。
@s.route('/list')
def list_school():
schools = School.query.all()
school_output = []
for s_item in schools:
school_output.append(s_item.to_json())
return render_template('school/index.html')
运行代码,页面成功渲染。
下面选择数据库中的一条数据,传递到前台。
@s.route('/list')
def list_school():
schools = School.query.all()
school_output = []
for s_item in schools:
school_output.append(s_item.to_json())
one_school = school_output[0]
return render_template('school/index.html',item = one_school)
前台 HTML 页面增加数据输出代码。
本案例完成。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 805 篇原创博客
从订购之日起,案例 5 年内保证更新
⭐️ Python 爬虫 120,点击订购 ⭐️ ⭐️ 爬虫 100 例教程,点击订购 ⭐️








 京公网安备 11010802041100号
京公网安备 11010802041100号