model = ...
dataset = ...
loss_fun = ...
# training
lr=0.001
model.train()
for x,y in dataset:
model.zero_grad()
p = model(x)
l = loss_fun(p, y)
l.backward()
for p in model.parameters():
p.data -= lr*p.grad
# evaluating
sum_loss = 0.0
model.eval()
with torch.no_grad():
for x,y in dataset:
p = model(x)
l = loss_fun(p, y)
sum_loss += l
print('total loss:', sum_loss)
另外no_grad还可以作为函数是修饰符来用,从而简化代码。
def train(model, dataset, loss_fun, lr=0.001):
model.train()
for x,y in dataset:
model.zero_grad()
p = model(x)
l = loss_fun(p, y)
l.backward()
for p in model.parameters():
p.data -= lr*p.grad
@torch.no_grad()
def test(model, dataset, loss_fun):
sum_loss = 0.0
model.eval()
for x,y in dataset:
p = model(x)
l = loss_fun(p, y)
sum_loss += l
return sum_loss
# main block:
model = ...
dataset = ...
loss_fun = ...
# training
train()
# test
sum_loss = test()
print('total loss:', sum_loss)


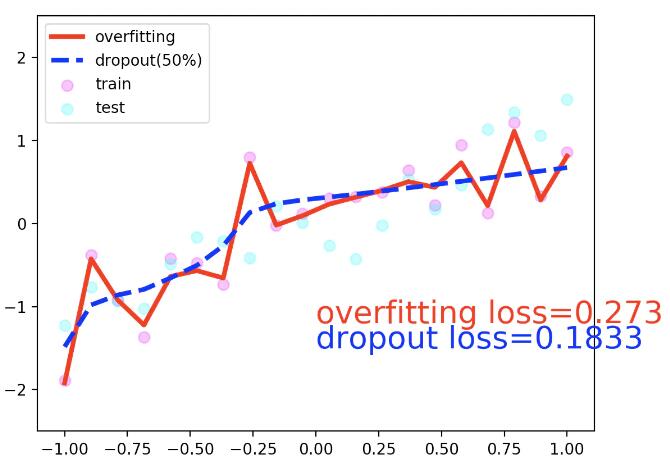









 京公网安备 11010802041100号
京公网安备 11010802041100号