雷锋网(公众号:雷锋网)按:本文作者齐国君,伊利诺伊大学电子与计算机工程专业。雷锋网获授权转载,更多AI开发技术文章,关注AI研习社(微信号:okweiwu)。最近很多关心深度学习
雷锋网(公众号:雷锋网)按:本文作者齐国君,伊利诺伊大学电子与计算机工程专业。雷锋网获授权转载,更多AI开发技术文章,关注AI研习社(微信号:okweiwu)。
最近很多关心深度学习最新进展,特别是生成对抗网络的朋友可能注意到了一种新的GAN-- Wasserstein GAN。其实在WGAN推出的同时,一种新的LS-GAN (Loss Sensitive GAN,损失敏感GAN)也发表在预印本 [1701.06264] Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities 上。
那这两种GAN有没有什么联系呢?作为LS-GAN的作者,笔者就带大家一览WGAN和LS-GAN本质和联系。
GAN前传和“无限的建模能力”
熟悉经典GAN的读者都知道,GAN是一种通过对输入的随机噪声z (比如高斯分布或者均匀分布),运用一个深度网络函数G(z),从而希望得到一个新样本,该样本的分布,我们希望能够尽可能和真实数据的分布一致(比如图像、视频等)。
在证明GAN能够做得拟合真实分布时,Goodfellow做了一个很大胆的假设:用来评估样本真实度的Discriminator网络(下文称D-网络)具有无限的建模能力,也就是说不管真实样本和生成的样本有多复杂,D-网络都能把他们区分开。这个假设呢,也叫做非参数假设。
当然,对于深度网络来说,咱只要不断的加高加深,这还不是小菜一碟吗?深度网络擅长的就是干这个的么。
但是,正如WGAN的作者所指出的,一旦真实样本和生成样本之间重叠可以忽略不计(这非常可能发生,特别当这两个分布是低维流型的时候),而又由于D-网络具有非常强大的无限区分能力,可以完美地分割这两个无重叠的分布,这时候,经典GAN用来优化其生成网络(下文称G-网络)的目标函数--JS散度-- 就会变成一个常数!
我们知道,深度学习算法,基本都是用梯度下降法来优化网络的。一旦优化目标为常数,其梯度就会消失,也就会使得无法对G-网络进行持续的更新,从而这个训练过程就停止了。这个难题一直一来都困扰这GAN的训练,称为梯度消失问题。
WGAN来袭
为解决这个问题,WGAN提出了取代JS散度的Earth-Mover(EM)来度量真实和生成样本密度之间的距离。该距离的特点就是,即便用具有无限能力的D-网络完美分割真实样本和生成样本,这个距离也不会退化成常数,仍然可以提供梯度来优化G-网络。不过WGAN的作者给出的是定性的解释,缺少定量分析,这个我们在后面解释LS-GAN时会有更多的分析。
现在,我们把这个WGAN的优化目标记下来,下文我们会把它跟本文的主角LS-GAN 做一番比较。
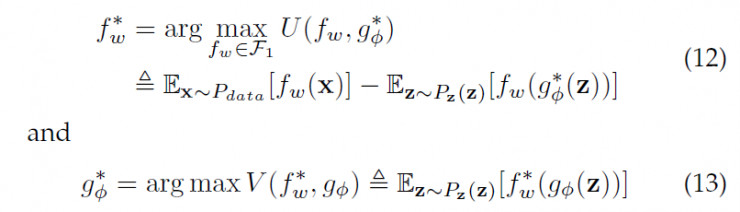
这里 f-函数和 g-函数 分别是WGAN的批评函数(critics)和对应的G-网络。批评函数是WGAN里的一个概念,对应GAN里的Discriminator。该数值越高,代表对应的样本真实度越大。
好了,对WGAN就暂时说到这里。总结下,由于假设中的无限建模能力,使得D-网络可以完美分开真实样本和生成样本,进而JS散度为常数;而WGAN换JS散度为EM距离,解决了优化目标的梯度为零的问题。
不过细心的读者注意到了,WGAN在上面的优化目标(12)里,有个对f-函数的限定:它被限定到所谓的Lipschitz连续的函数上的。那这个会不会影响到上面对模型无限建模能力的假设呢?
其实,这个对f-函数的Lipschitz连续假设,就是沟通LS-GAN和WGAN的关键,因为LS-GAN就是为了限制GAN的无限建模能力而提出的。
熟悉机器学习原理的朋友会知道,一提到无限建模能力,第一反应就应该是条件反应式的反感。为什么呢?无限建模能力往往是和过拟合,无泛化性联系在一起的。
仔细研究Goodfellow对经典GAN的证明后,大家就会发现,之所以有这种无限建模能力假设,一个根本原因就是GAN没有对其建模的对象--真实样本的分布--做任何限定。
换言之,GAN设定了一个及其有野心的目标:就是希望能够对各种可能的真实分布都适用。结果呢,就是它的优化目标JS散度,在真实和生成样本可分时,变得不连续,才使得WGAN有了上场的机会,用EM距离取而代之。
所以,某种意义上,无限建模能力正是一切麻烦的来源。LS-GAN就是希望去掉这个麻烦,取而代之以“按需分配”建模能力。
LS-GAN和“按需分配”的建模能力
好,让我们换个思路,直接通过限定的GAN的建模能力,得到一种新的GAN模型。这个就是LS-GAN了。我们先看看LS-GAN的真容:

这个是用来学习损失函数的目标函数。我们将通过最小化这个目标来得到一个“损失函数" (,下文称之为L-函数)。L-函数在真实样本上越小越好,在生成的样本上越大越好。
另外,对应的G-网络,通过最小化下面这个目标实现:
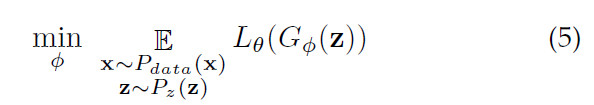
这里注意到,在公式(6)中,对L-函数的学习目标 S中的第二项,它是以真实样本x和生成样本的一个度量为各自L-函数的目标间隔,把x和分开。
这有一个很大的好处:如果生成的样本和真实样本已经很接近,我们就不必要求他们的L-函数非得有个固定间隔,因为,这个时候生成的样本已经非常好了,接近或者达到了真实样本水平。
这样呢,LS-GAN就可以集中力量提高那些距离真实样本还很远,真实度不那么高的样本上了。这样就可以更合理使用LS-GAN的建模能力。在后面我们一旦限定了建模能力后,也不用担心模型的生成能力有损失了。这个我们称为“按需分配”。
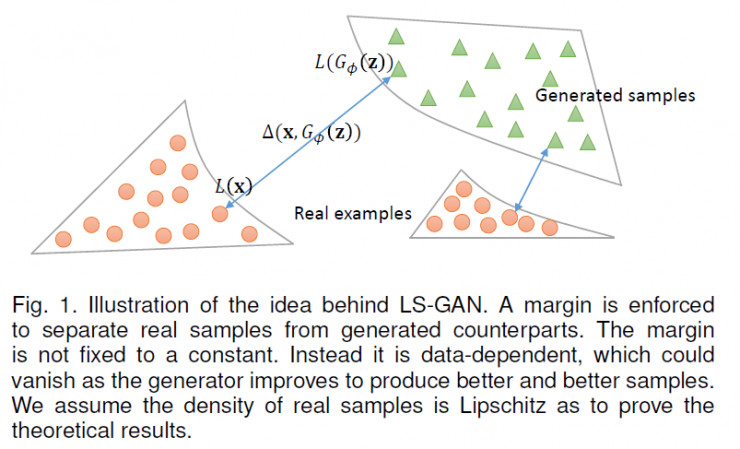
上图就是对LS-GAN这种对建模能力”按需“分配的图示。
有了上面的准备,我们先把LS-GAN要建模的样本分布限定在Lipschitz 密度上,即如下的一个假设:

那么什么是Lipschitz密度了?简而言之,Lipschitz密度就是要求真实的密度分布不能变化的太快。密度的变化随着样本的变化不能无限地大,要有个度。不过这个度可以非常非常地大,只要不是无限大就好。
好了,这个条件还是很弱地,大部分分布都是满足地。比如,你把一个图像调得稍微亮一些,它看上去仍然应该是真实的图像,在真实图像中的密度在Lipschitz假设下不应该会有突然地、剧烈地变化。不是吗?
然后,有了这个假设,我就能证明LS-GAN,当把L-函数限定在Lipschitz连续的函数类上,它得到地生成样本地分布和真实样本是完全一致!
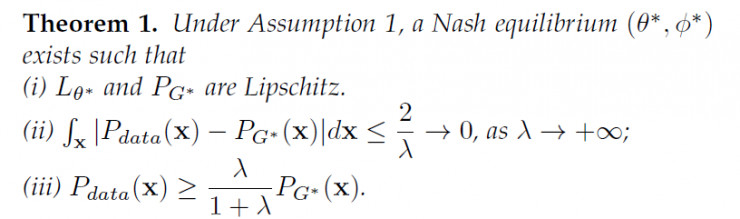
前面我们说了,经典GAN事实上对它生成的样本密度没有做任何假设,结果就是必须给D-网络引入无限建模能力,正是这种能力,在完美分割真实和生成样本,导致了梯度消失,结果是引出了WGAN。
现在,我们把LS-GAN限定在Lipschitz密度上,同时限制住L-函数的建模能力到Lipschitz连续的函数类上,从而证明了LS-GAN得到的生成样本密度与真实密度的一致性。
那LS-GAN和WGAN又有什么关系呢?
细心的朋友可能早注意到了,WGAN在学习f-函数是,也限定了其f-函数必须是Lipschitz连续的。不过WGAN导出这个的原因呢,是因为EM距离不容易直接优化,而用它的共轭函数作为目标代替之。
也就是说,这个对f-函数的Lipschitz连续性的约束,完全是“技术”上的考虑,没有太多物理意义上的考量。
而且,WGAN的作者也没有在他们的论文中证明:WGAN得到的生成样本分布,是和真实数据的分布是一致的。不过,这点在我们更新的预印本中给出了明确的证明,如下:

换言之:我们证明了,WGAN在对f-函数做出Lipschitz连续的约束后,其实也是将生成样本的密度假设为了Lipschiz 密度。这点上,和LS-GAN是一致的!两者都是建立在Lipschitz密度基础上的生成对抗网络。
好了,让我们把LS-GAN和WGAN对L-函数和f-函数的学习目标放在一起仔细再看一看:
LS-GAN:
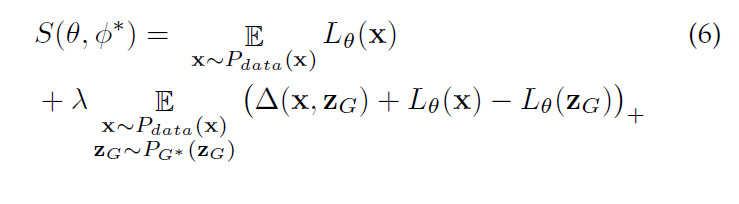
WGAN:

形式上来看,LS-GAN和WGAN也有很大区别。WGAN是通过最大化f-函数在真实样本和生成样本上的期望之差实现学习的,这种意义上,它可以看做是一种使用“一阶统计量"的方法。
LS-GAN则不同。观察LS-GAN优化目标的第二项,由于非线性的函数的存在,使得我们无法把L-函数分别与期望结合,像WGAN那样得到一阶统计量。因为如此,才使得LS-GAN与WGAN非常不同。
LS-GAN可以看成是使用成对的(Pairwise)“真实/生成样本对”上的统计量来学习f-函数。这点迫使真实样本和生成样本必须相互配合,从而更高效的学习LS-GAN。
如上文所述,这种配合,使得LS-GAN能够按需分配其建模能力:当一个生成样本非常接近某个真实样本时,LS-GAN就不会在过度地最大化他们之间L-函数地差值,从而LS-GAN可以更有效地集中优化那些距离真实样本还非常远地生成样本,提高LS-GAN模型优化和使用地效率。
梯度消失问题
那LS-GAN是否也能解决经典GAN中的梯度消失问题呢?即当它的L-函数被充分训练后,是否对应的G-网络训练目标仍然可以提供足够的梯度信息呢?
我们回顾下,在WGAN里,其作者给出G-网络的训练梯度,并证明了这种梯度在对应的f-函数被充分优化后,仍然存在。
不过,仅仅梯度存在这点并不能保证WGAN可以提供足够的梯度信息训练 G-网络。为了说明WGAN可以解决梯度消失问题,WGAN的作者宣称:“G-网络的训练目标函数”在对其网络链接权重做限定后, 是接近或者最多线性的。这样就可以避免训练目标函数饱和,从而保证其能够提供充足的梯度训练G-网络。
好了,问题的关键时为什么G-网络的训练目标函数是接近或者最多线性的,这点WGAN里并没有给出定量的分析,而只有大致的定性描述,这里我们引用如下:


现在,让我们回到LS-GAN,看看如何给出一直定量的形式化的分析。在LS-GAN里,我们给出了最优的L-函数的一种非参数化的解:
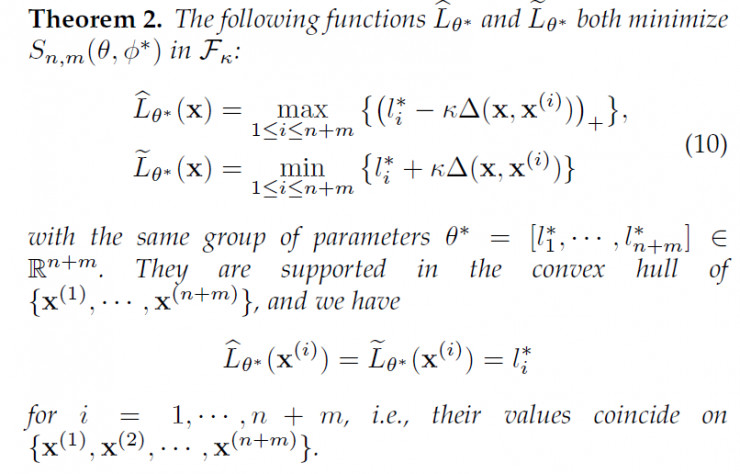
这个定理比较长,简单的来说,就是所有的最优 L-GAN的解,都是在两个分段线性的上界和下界L-函数之间。如下图所示:
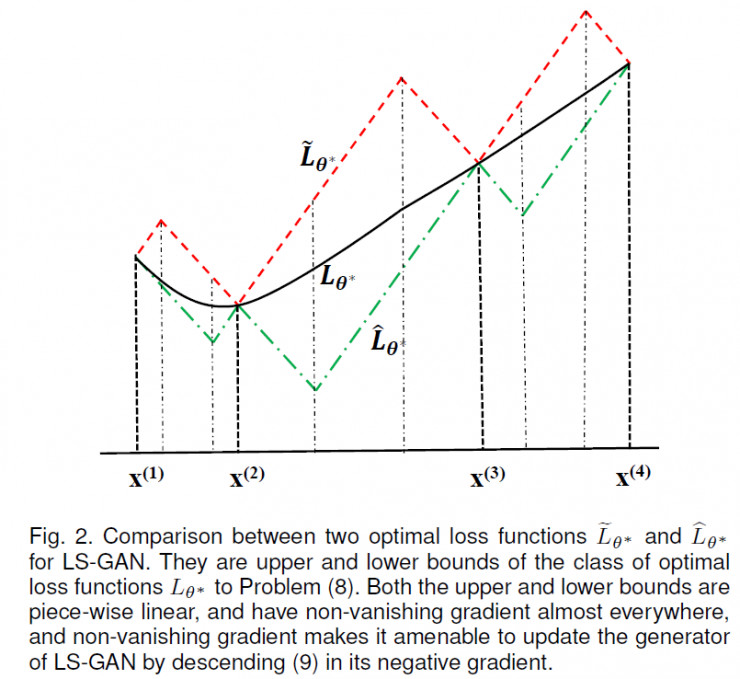
红线是上界,绿线是下界。任何解出来最优L-函数,一定在这两个分段线性的上下界之间,包括用一个深度网络解出来L-函数。
也就是说,LS-GAN解出的结果,只要上下界不饱和,它的得到的L-函数就不会饱和。而这里看到这个L-函数的上下界是分段线性的。这种分段线性的函数几乎处处存在非消失的梯度,这样适当地控制L-函数地学习过程,在这两个上下界之间地最优L-函数也不会出现饱和现象。
好了,这样我们就给出了WGAN分析梯度消失时候,缺失的哪个定量分析了。
最后,我们看看LS-GAN合成图像的例子,以及和DCGAN的对比。
看看在CelebA上的结果:

如果我们把DCGAN和LS-GAN中Batch Normalization 层都去掉,我们可以看到DCGAN模型取崩溃,而LS-GAN仍然可以得到非常好的合成效果:

不仅如此,LS-GAN在去掉batch normalization后,如上图(b)所示,也没有看到任何mode collapse现象。
我们进一步通过实验看看、在LS-GAN中L-函数网络过训练后,模型还能不能提供足够的梯度来训练G-网络。
下图是L-网络每次都训练,而G-网络每个1次、3次、5次才训练时,对应的用来更新G-网络的梯度大小(在log scale上):
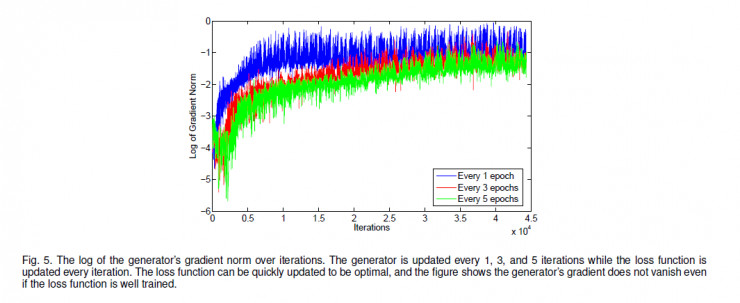
我们可以看到:即便当L-网络相对G-网络多训练若干次后,更新G-网络的梯度仍然充分大,而没有出现梯度消失的问题。
不仅如此,随着训练的进行,我们可以看到,G-网络的梯度逐渐增大,一直到一个相对比较稳定的水平。相对固定强度的梯度说明了,G-网络的训练目标函数,最终非常可能是达到一个接近线性的函数(这是因为线性函数的梯度是固定的)。
这个也进一步说明了,LS-GAN定义的G-网络的训练目标函数没有发生饱和,其定义是合理的,也是足以避免梯度消失问题的。
对LS-GAN进行有监督和半监督的推广
LS-GAN和GAN一样,本身是一种无监督的学习算法。LS-GAN的另一个突出优点是,通过定义适当的损失函数,它可以非常容易的推广到有监督和半监督的学习问题。
比如,我们可以定义一个有条件的损失函数,这个条件可以是输入样本的类别。当类别和样本一致的时候,这个损失函数会比类别不一致的时候小。
于是,我们可以得到如下的Conditional LS-GAN (CLS-GAN)
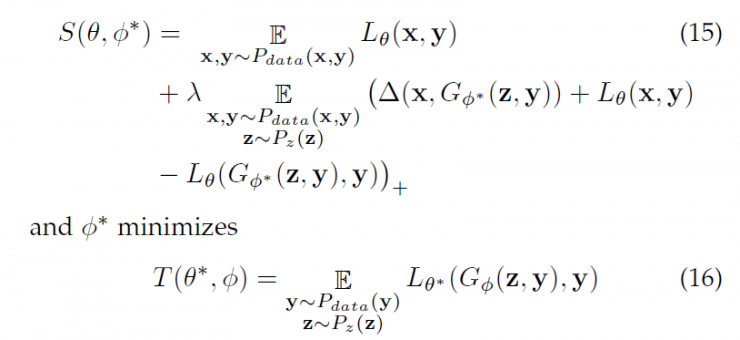
我们可以看看在MNIST, CIFAR-10和SVHN上,针对不同类别给出的合成图像的效果:

半监督的训练是需要使用完全标注的训练数据集。当已标注的数据样本比较有限时,会使得训练相应模型比较困难。
进一步,我们可以把CLS-GAN推广到半监督的情形,即把已标记数据和未标记数据联合起来使用,利用未标记数据提供的相关分布信息来指导数据的分类。
为此,我们定义一个特别的半监督的损失函数:

对给定样本x,我们不知道它的具体类别,所以我们在所有可能的类别上对损失函数取最小,作为对该样本真实类别的一个最佳的猜测。这与上面的公式(7)是一致的。
这样,我们可以相应的推广CLS-GAN,得到如下的训练目标 最优化损失函数
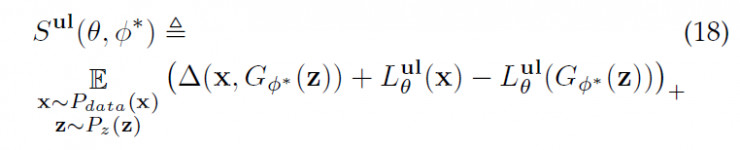
该训练目标可以通过挖掘各个类别中可能的变化,帮助CLS-GAN模型合成某类中的更多的“新”的样本,来丰富训练数据集。这样,即便标注的数据集比较有限,通过那些合成出来已标记数据,也可以有效的训练模型。
比如,在下面图中,CLS-GAN模型通过对未标记MNIST数据进行分析,可以按类别合成出更多不同书写风格的数字。

这些数字可以增加已标注的训练数据量,进一步提供模型准确度;而更准确的模型可以进一步提供CLS-GAN的合成图像的准确性。通过这种彼此不断的提高,半监督的CLS-GAN在只有很少已标注训练数据下,仍然可以做到准确的分类。
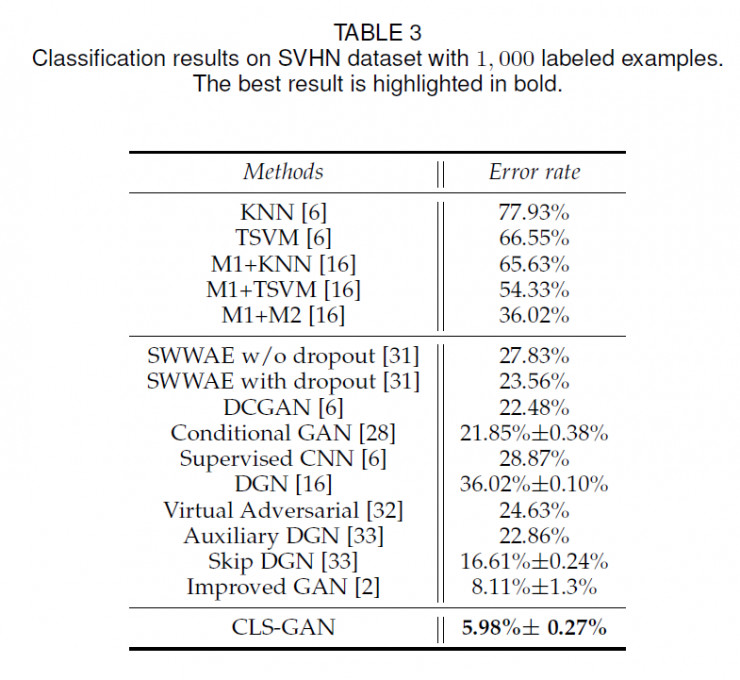
我们可以看下在SVHN上,当只有1000张已标注训练数据时分类的准确度:
下面是在CIFAR-10上,4000张已标记数据下的分类准确度。

结论
那么究竟GAN,WGAN和LS-GAN谁更好呢?持平而论,笔者认为是各有千秋。究竟谁更好,还是要在不同问题上具体分析。
这三种方法只是提供了一个大体的框架,对于不同的具体研究对象(图像、视频、文本等)、数据类型(连续、离散)、结构(序列、矩阵、张量),应用这些框架,对具体问题可以做出很多不同的新模型。
当然,在具体实现时,也有非常多的要考虑的细节,这些对不同方法的效果都会起到很大的影响。毕竟,细节是魔鬼!笔者在实现LS-GAN时也有很多的具体细致的问题要克服。一直到现在,我们还在不断持续的完善相关代码。
对LS-GAN有兴趣的读者,可以参看我们分享的代码,并提出改进的建议。 对研究GAN感兴趣的读者,也欢迎联系笔者:个人主页,一起探讨相关算法、理论。
雷锋网版权文章,未经授权禁止转载。详情见。










 京公网安备 11010802041100号
京公网安备 11010802041100号