作者:葬宝御用小奶瓶2004 | 来源:互联网 | 2023-08-29 10:34
本文由编程笔记#小编为大家整理,主要介绍了CDH Hadoop + HBase HA 部署详解相关的知识,希望对你有一定的参考价值。
CDH 的部署和 Apache Hadoop 的部署是没有任何区别的。这里着重的是 HA的部署,需要特殊说明的是NameNode HA 需要依赖 Zookeeper
准备
Hosts文件配置:

各个节点服务情况

对几个新服务说明下:
NTP 服务
设置时区

配置NTP Server

启动并设置开机自启动

配置 NTP Client

启动并设置开机自启动

检查 NTP 同步

JDK
创建目录

创建运行账户
useradd -u 600 run
安装包
http://archive.cloudera.com/cdh5/cdh/5/

安装 Zookeeper

设置环境变量

删除无用文件

创建数据目录

配置

修改Zookeeper的日志打印方式,与日志路径设置
编辑
$ZOOKEEPER_HOME/bin/zkEnv.sh
在27行后加入两个变量

创建 myid文件

设置目录权限
chown -R run.run /data/{app,appData,logs}
启动、停止

安装 Hadoop

设置环境变量
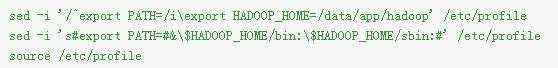
删除无用文件

新建数据目录
mkdir -p /data/appData/hdfs/{name,edits,data,jn,tmp}
配置
切换到配置文件目录
cd $HADOOP_HOME/etc/hadoop
编辑 core-site.xml

编辑 hdfs-site.xml



小于5个DataNode建议添加如下配置

在 hadoop-env.sh 中添加如下变量
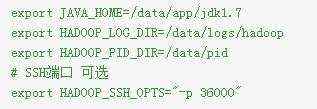
Heap 设置,单位 MB
export HADOOP_HEAPSIZE=1024
权限设置
chown -R run.run /data/{app,appData,logs}
chmod 777 /data/pid
格式化
格式化只需要执行一次,格式化之前启动Zookeeper
切换用户
su - run
启动所有 JournalNode
hadoop-daemon.sh start journalnode
格式化 Zookeeper(为 ZKFC 创建znode)
hdfs zkfc -formatZK
NameNode 主节点格式化并启动
hdfs namenode -format
hadoop-daemon.sh start namenode
NameNode 备节点同步数据并启动
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
启动 ZKFC
hadoop-daemon.sh start zkfc
启动 DataNode
hadoop-daemon.sh start datanode
启动与停止
切换用户
su - run
集群批量启动
需要配置运行用户ssh-key免密码登录,与$HADOOP_HOME/etc/hadoop/slaves
# 启动
start-dfs.sh
# 停止
stop-dfs.sh
单服务启动停止
启动HDFS
hadoop-daemon.sh start journalnode
hadoop-daemon.sh start namenode
hadoop-daemon.sh start zkfc
hadoop-daemon.sh start datanode
停止HDFS
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop journalnode
hadoop-daemon.sh stop zkfc
测试
HDFS HA 测试
打开 NameNode 状态页:
http://cdh-m1:50010
http://cdh-m2:50010
在 Overview 后面能看见 active 或 standby,active 为当前 Master,停止 active 上的 NameNode,检查 standby是否为 active。
HDFS 测试
hadoop fs -mkdir /test
hadoop fs -put /etc/hosts /test
hadoop fs -ls /test
结果:

HDFS 管理命令
# 动态加载 hdfs-site.xml
hadoop dfsadmin -refreshNodes
HBase安装配置
cd /data/install
tar xf hbase-1.0.0-cdh5.4.5.tar.gz -C /data/app
cd /data/app
ln -s hbase-1.0.0-cdh5.4.5 hbase
设置环境变量

删除无用文件

配置
进入配置文件目录
cd $HBASE_HOME/conf
编辑 hbase-site.xml

在 hbase-env.sh 中添加如下变量
Heap 设置,单位 MB
export HBASE_HEAPSIZE=1024
可选设置 regionservers 中添加所有RegionServer主机名,用于集群批量启动、停止
启动与停止
切换用户
su - run
集群批量启动
需要配置运行用户ssh-key免密码登录,与$HBASE_HOME/conf/regionservers
# 启动
start-hbase.sh
# 停止
stop-hbase.sh
单服务启动停止
HMaster
# 启动
hbase-daemon.sh start master
# 停止
hbase-daemon.sh stop master
HRegionServer
# 启动
hbase-daemon.sh start regionserver
# 停止
hbase-daemon.sh stop regionserver
测试
HBase HA 测试
浏览器打开两个HMaster状态页:
http://cdh-m1:60010
http://cdh-m2:60010
可以在Master后面看见其中一个主机名,Backup Masters中看见另一个。
停止当前Master,刷新另一个HMaster状态页会发现Master后面已经切换,HA成功。
HBase 测试
进入hbase shell 执行:
create 'users','user_id','address','info'
list
put 'users','anton','info:age','24'
get 'users','anton'
# 最终结果
COLUMN CELL
info:age timestamp=1465972035945, value=24
1 row(s) in 0.0170 seconds
清除测试数据:
disable 'users'
drop 'users'
微信扫一扫







 京公网安备 11010802041100号
京公网安备 11010802041100号