作者:手机用户2502903031 | 来源:互联网 | 2023-02-06 02:41
基于Lucene实现万亿级多维检索与实时分析-5月29日,录信数软技术总监郑其华在QCon全球软件开发者大会分享了“基于Lucene实现万亿级多维检索与实时分析”的主题演讲,现场座
5月29日,录信数软技术总监郑其华在QCon全球软件开发者大会分享了“基于Lucene实现万亿级多维检索与实时分析”的主题演讲,现场座无虚席,活动在浓烈的技术讨论氛围中圆满结束。下面,我们将分享演讲全文。
1.万亿挑战之一:数据存储
第一个关于数据存储。平常我们保存数据很简单,往硬盘里面写就行了。海量数据就没那么简单,会面临很多问题。比如成本问题。是使用SSD固态硬盘还是机械磁盘,是使用100块大磁盘,还是使用1万块小磁盘,在成本上都会造成巨大的差异。
其次,数据的安全性也是一个问题。万一磁盘损坏了,或者误删除了,数据就会丢失。数据迁移、扩容也会比较麻烦。另外,还有一个读写均衡的问题。数据写入不均衡的话,可能就会导致有的磁盘特别忙,有的磁盘很空闲。或者,如果有个别磁盘出问题了,读写速度变慢了,就会导致所有的查询都会卡在这个磁盘的IO上面,降低了整体性能。
针对存储的这些问题,我们采用了基于HDFS的索引技术来解决。
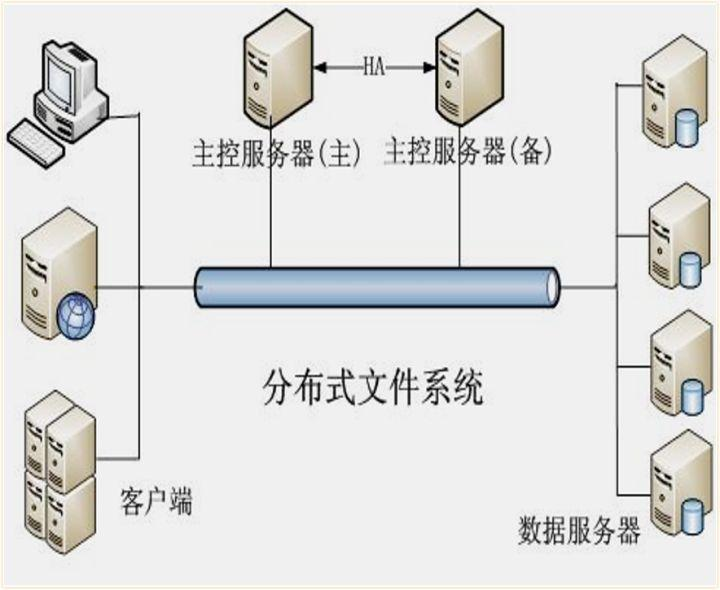
采用HDFS可以解决哪些问题呢?对于读写不均衡的问题,HDFS是一个高度容错的系统,如果有磁盘坏掉了,或者速度变慢了,会自动切换到速度较快的副本上进行读取。并且,会对磁盘数据读写进行自动均衡,避免出现数据倾斜的问题。对于数据安全性的问题,HDFS有数据快照、冗余副本等功能,可以降低因磁盘损坏,或者误删除操作带来的数据丢失问题。对于存储成本问题,HDFS支持异构存储,可以混合使用各种存储介质,降低硬件成本。而且,HDFS可以支持大规模的集群,使用和管理成本都比较低。
除此之外,为了进一步降低存储成本,我们研发了列簇的功能。原生Lucene是不支持列簇的,列簇的好处是什么呢?
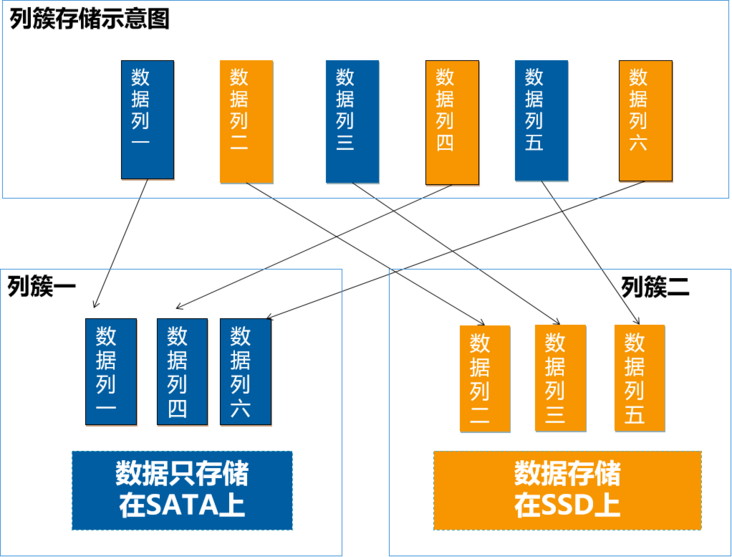
我们可以将数据列,指定为不同的列簇,按列簇来混合使用不同磁盘,并且可以对不同列簇设置不同的生命周期。比如,一个文档里面可能包含一些结构化的数据,像标题、作者、摘要等等,这些数据一般比较小,而且是经常要进行检索的。那么我们就可以将这些数据列定义为一个列簇,放在SSD上。还有一些类似附件、图片、视频等非结构化的数据,这些数据比较大,而且一般不会进行查询的,可以定义为另一个列簇,放在的SATA盘上面。从而降低了SSD固态硬盘的使用量。另外,列簇结合HDFS的异构策略,我们还可以实现冷热数据的分离。比如,有的业务经常查询最近1个月以内数据。那么,我们就可以将最近1个月保留在SSD上,1个月以后,将数据,移到SATA盘上,从而进一步降低SSD使用量。

接下来,再看另外一个问题。大数据有一个基本的应用,就是查询检索。比如这个页面上显示的一个“全文检索”功能,是从海量数据里面查找包含用户输入关键字的数据。这样的搜索功能很常见,也不难实现。难的地方在于性能。对于万亿规模的数据,是几秒就响应了,还是几个小时再响应呢?
2.万亿挑战之二,检索性能
为了实现万亿秒查的性能。我们对Lucene的倒排表进行了优化。
在全文检索领域里面,通常的做法,就是进行切词,然后记录这个关键词在哪个文档里面出现过。同时,也会保存其他一些相关的信息。比如,这个关键词出现的频率、在这个文档出现的位置等等,大概有十几个元素,这些元素就是保存在倒排表里面。Lucene对这些元素,采用的是行存储。这就意味着,每次查询都需要把所有的十几个元素都读取出来。而我们在检索时,实际用到的可能只有其中的两三个元素。使用行存的话,会造成很多不必要的IO。因此,我们在这里,将倒排表里面的元数据,改成了列存储。
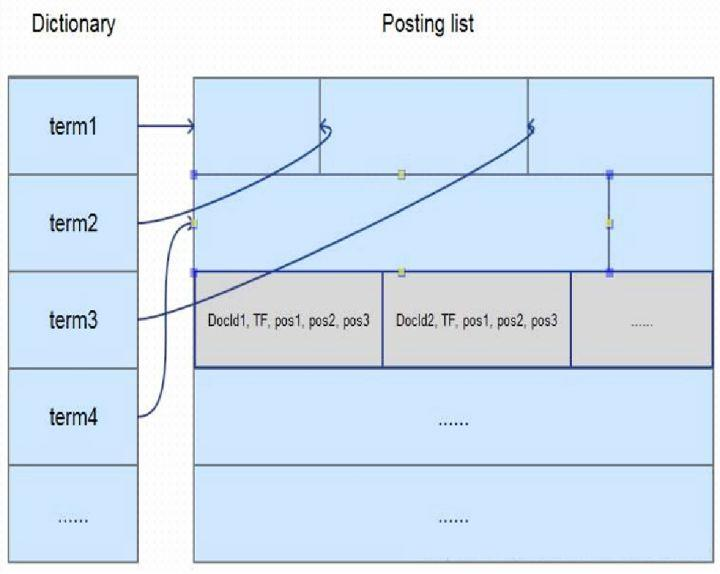

列存的好处是,查询用到哪个元素,我只读取这个元素的内容,其他的内容就可以直接跳过。这个改动看上去很小,但是在海量数据的场景,对性能的影响却是极大的。比如,我们查询的关键字,可能命中了几亿条数据。就需要读取几亿个倒排表的元数据信息,如果使用行存,读取的数据量就是几亿个元数据乘以十几个元素。而列存储的话,只需要读取两三个元素,磁盘IO上就差了好几倍。所以,通过倒排表元数据的列存化,减少无效IO,这样一个优化,带来了好几倍的性能提升。
然后,第二个优化的地方呢,我们将倒排表按时序进行了存储。
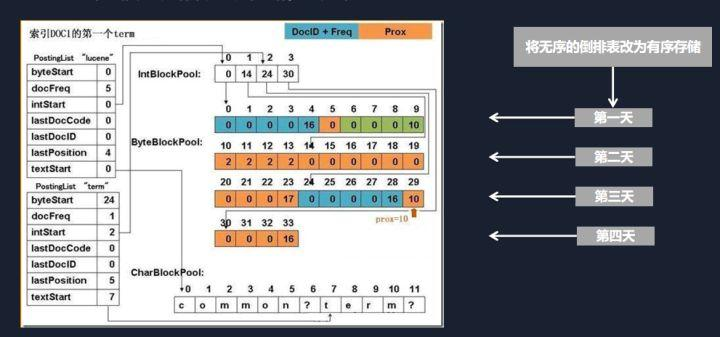
因为我们在实际场景中发现,很多数据会有一个时序性的特点。也就是数据都是随着时间推移而产生的。对这些数据查询时,一般也会结合时间范围进行。比如查询最近一天或者最近几小时的汽车尾气排放量等等。而原生Lucene的索引数据在存放时,是杂乱无序的。同一天的数据,可能存在磁盘的不同位置。这样在读取的时候,就是一个随机读取。所以,我们在这里也做了一点改进。把数据按照入库的顺序进行存放。那么,我们在查询某时间段的数据时,只需要将磁盘上这一整块的数据读取出来。我们知道机械硬磁盘的随机读取性能比连续读取性能要差很多。而且,磁盘在读取连续数据时还有预读功能。同样大小的数据量,连续读取的性能可能会比随机读取的性能高一个数量级。
经过对索引的优化,基本上万亿数据的检索性能可以做到秒级响应。
3.万亿挑战之三,多维统计
接下来看,另一个常见的应用。就是统计分析。
这是一个典型的数据立方体。会涉及到多个维度,有时间维度、地区维度等等。每个维度可能还会有层级关系,比如说我们先查询每年的汽车保有量数据,然后需要在时间维度下钻到每个季度的数据,或者到每个月的数据。而原生Lucene在索引上,只有单层的关系,对于一个列,只能建单列的索引,所以在做多维或者多层次的检索统计上,性能会比较差。
对于多维统计,业界通常的做法,是使用DocValues进行统计分析。而DocValues会带来随机IO的问题。所以,我们将Lucene的倒排索引表,又进行了修改。这次修改的倒排表里面的term。
原来term里面只能存一个列,改进后,就可以存多个列的值。比如,第一列保存年份、第二列保存季度,第三列保存月份。通过干预数据的排序分布,在同一个年份,比如2018年下,每个季度的数据都是连续的。这样,在统计分析2018年的每个月的数据时,只需要找到2018年的开始位置,直接读取接下来的一块数据就可以了。

另外,在这个多列联合索引的基础上,我们还增加了两级跳跃表。每个跳跃表里面会保存多列联合索引的最大最小值。目的是在检索时,可以快速定位到指定的关键字上面。从而提高单列或者多列的统计分析性能。
4.万亿挑战之四,区域检索
然后,我们再看一个比较特殊的应用场景——区域检索。区域检索是基于地理位置信息,一般是经纬度进行查询匹配。常见于公安安防行业。
区域检索会有什么样的问题呢?原生Lucene在处理区域检索时,一般是采用GeoHash来选择一个正方形,然后使用DocValues进行二次验证。比如,要检索圆形区域的话,就需要裁剪掉多余的几个角。而使用DocValues,跟前面的统计分析一样,就会导致随机读取问题,性能比较差。
我们所做的改动呢,就是把原来随机散落在磁盘各个位置的DocValues,改为按位置临近存储起来。也就是相同的地理位置的数据,存储的时候,在磁盘上也是挨在一起的。搜索的时候,因为数据挨在一起,读取就变为一个顺序读取。相比原来的随机读取,性能有了一个大幅的提升。
5.万亿挑战之五,计算框架
除了关于存储层和索引层的优化,对于上层的计算框架,我们也进行了相应的修改。虽然spark作为通用计算引擎,功能上基本满足我们的需求。但是在万亿数据规模下,仍然存在一些问题。例如,spark底层对数据的获取是一条条暴力读取。当数据规模超过万亿时,性能比较差。想提升性能,则需要增加硬件投入,成本比较高。而且在实际生产应用中出现过各种问题。
所以,我们对spark进行了修改。将底层的数据存储改为基于我们自研的分布式索引。Spark在查询的时候,就不需要对数据进行暴力扫描,而是先通过索引,快速定位到命中的部分数据。从而提升了数据的查询、统计时间。同时,我们修正了大量开源spark的问题,确保在生产系统中可以稳定运行。
6.产品架构
通过上述各个组件的整合和优化,最终我们形成了如下的产品架构。
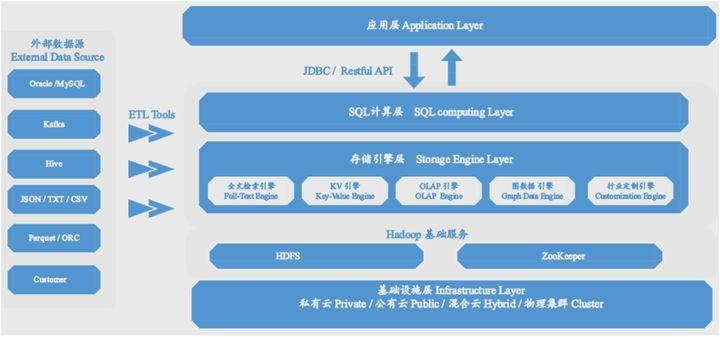
底部是Hadoop的基础服务,上面是SQL计算层,通过SQL语句与应用层进行交互。最核心的是中间的存储引擎层,包含了lucene的全文检索功能,HBase的KV模型,还有多列联合索引实现的OLAP分析引擎等。后续还可以在这一层里面进行扩展,实现图数据库以及一些行业定制的功能。
另外,可以通过ETL工具,与常见的外部数据源进行数据导入导出。
7.应用场景
这样一套系统,可以应用在哪些场景呢?可以支持万亿数据的检索分析吗?
答案是肯定的。这个系统我们在公安军队行业已经有很多实际项目。公安行业,汇集了全网各种维度的数据,超过万亿规模的项目非常常见。可以利用这个系统,通过实时检索、关联碰撞等功能,提供智能研判关系网络,助力公安侦破各种案件。
另外一个场景,就是汽车行业。随着车联网的快速发展,汽车产生的数据规模也越来越大。比如,每台车载终端T-Box,每天都会产生数万条数据,几十万台车辆每年产生的数据量就会超过万亿规模。针对国六标准的推行,对车辆的尾气数据、油耗数据都需要进行监管。我们与中汽研合作,提供的数据存储和检索分析解决方案,目前已经应用于各大主机厂。
还有一个我们最近正在开发和研究的场景,就是针对于航空和船舶的时空轨迹分析。通过对于大量的航空和船舶数据进行多维检索和可视化分析,借助于我们产品对于时间、空间数据的优化,从而实现对于相似轨迹的碰撞分析、伴随分析等。
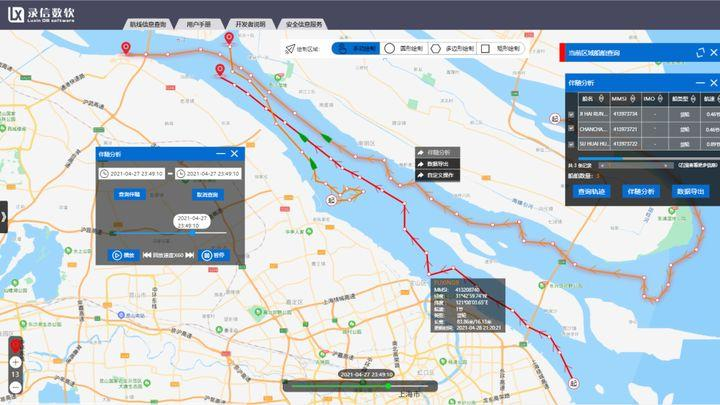
上面这几个场景的数据量都达到了万亿规模,从实际使用效果来看,我们这种架构架是可以满足支撑万亿数据的检索分析需求。
在结束了北京的活动之后,我们将会在7月23日-24日在深圳大中华喜来登酒店的ArchSummit全球架构师峰会带来全新的分享,目前议题还 没编出来 在构思中,敬请期待!
下一站,我们深圳见!

![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)









 京公网安备 11010802041100号
京公网安备 11010802041100号