“ 咦?训练集上的表现很不错,测试集和开发集怎么就下降了?有请正...正...正则化,这里是机器学习系列第三篇,带你走进正则化,了解一下它是如何改善网络性能的吧。(文末有彩蛋哦 )”
)”
图片挂了,大家移步以下链接
https://mp.weixin.qq.com/s?__biz=MzU4NTY1NDM3MA==&mid=2247483763&idx=1&sn=17b63b559ed0b6d22c3f59876467510a&chksm=fd86087ecaf181687998627eb5b175003e0b37c44e3f50827bc565ffdc24c2281d0e267929ff&token=255604471&lang=zh_CN#rd
01 导言
深度学习可能会存在过拟合问题,也即有比较高的方差(variance),导致深度网络不能很好的泛化,针对这个问题,我们可以有不同的解决方式,比如采用正则化、增加数据集、减小网络规模、改变网络架构等,这个主题我们将讨论正则化。
申明
本文原理解释和公式推导均由LSayhi完成,供学习参考,可传播;代码实现的框架由Coursera提供,由LSayhi完成,详细数据和代码可在github中查询.
https://github.com/LSayhi/DeepLearning
微信公众号:AI有点可ai

02 常见正则化
2.1、 L2范数正则化

更改为

更改后的代价函数的第二部分中 是范数,称为Frobenius norm,所以在书写时,矩阵
是范数,称为Frobenius norm,所以在书写时,矩阵 写为
写为 或
或 ,再代价函数增加的第二部分代价称为
,再代价函数增加的第二部分代价称为 正则化cost。那么在反相传播过程中,
正则化cost。那么在反相传播过程中, ,此处的
,此处的 相较于没有正则化的方式更大了,更新后的将更小,因此我们也称范数正则化为权重减轻。
相较于没有正则化的方式更大了,更新后的将更小,因此我们也称范数正则化为权重减轻。
2.2、L1范数正则化:
-
L1正则化与L2正则化不同的是,将改为 ,记为
,记为 ,称L1范数,L1正则化是将平方换成了绝对值。
,称L1范数,L1正则化是将平方换成了绝对值。
-
L1和L2一样,都是引入对参数W的惩罚,“惩罚”意为降低W对网络的影响,极端情况就是使W中的某些值为0,降低网络的表达能力。
-
L1与L2不同的是,L1能够产生稀疏性,L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0(详细演绎待补充)
2.3、L0范数正则化
2.4、dropout正则化
2.5、Early stopping
2.6、数据扩增
03 效果展示
任务:假设现在我们有一些足球比赛数据,这些数据记录着当法国队守门员发球后,在足球场上不同地点是哪方头球接球成功。利用这些数据,用神经网络预测在不同位置,是哪个队的球员头球成功获得控球权。

训练集数据如下图

采用同样的网络结构,利用不同正则化方式,我们对比下效果:
未使用正则化:

L2正则化:

dropout正则化

result table

可以看出正则化方式减小了过拟合,提高了测试集预测正确率。
04 python实现
4.1 本文相应的代码及资料已经以.ipynb文件和.pdf形式在github中给出。
-
.ipynb文件在链接/Coursera-deeplearning深度学习/课程2/week1/
-
.pdf文件在链接/Coursera-deeplearning深度学习
-
github地址:https://github.com/LSayhi/DeepLearning
点击【蓝字链接】,github传送门了解一下。
觉得有帮助的话别忘了star哦
有时候,不追求完美,反倒是一种美,我知道你并非完美,但却瑕疵的那么可爱
-by LSayhi的神经网络

 有关,这就是一个可以调试的参数。
有关,这就是一个可以调试的参数。 在一定条件下,依概率1等价于
在一定条件下,依概率1等价于 ,但L0范数优化是个NP-hard问题,人们于是倾向于用L1,L2范数。
,但L0范数优化是个NP-hard问题,人们于是倾向于用L1,L2范数。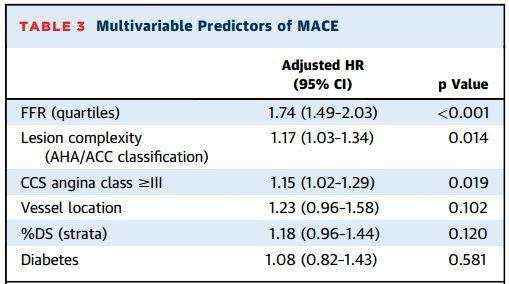








 京公网安备 11010802041100号
京公网安备 11010802041100号