作者:XbZSZl_682 | 来源:互联网 | 2023-01-31 18:51
一、sklearn中的Pipeline1-1、多项式回归相对于线性回归模型只能解决线性问题,多项式回归能够解决非线性回归问题。拿最简单的线性模型来说,其数学表达式可以表示为:yax

拿最简单的线性模型来说,其数学表达式可以表示为:y=ax+b,它表示的是一条直线,而多项式回归则可以表示成: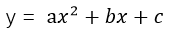 ,它表示的是二次曲线,实际上,多项式回归可以看成特殊的线性模型,即把
,它表示的是二次曲线,实际上,多项式回归可以看成特殊的线性模型,即把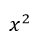 看成一个特征,把x看成另一个特征,这样就可以表示成y=az+bx+c,其中z=
看成一个特征,把x看成另一个特征,这样就可以表示成y=az+bx+c,其中z=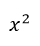 ,这样多项式回归实际上就变成线性回归了。
,这样多项式回归实际上就变成线性回归了。
下面介绍如何在sklearn中使用多项式回归
首先导入相应的库以及创造数据
import numpy as np
import matplotlib.pyplot as plt
x = np.random.uniform(-3,3,size=100)
X = x.reshape(-1,1)
y = 0.5 * x**2 + x + 2 + np.random.normal(0,1,100)
plt.scatter(x, y)
plt.show()
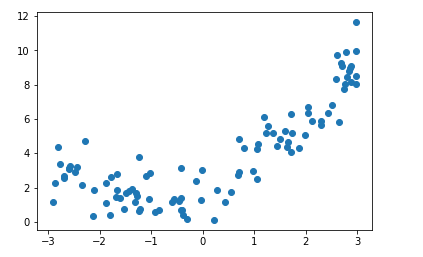
如果直接使用线性回归去拟合数据,则可以得到:
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X, y)
y_predict = lin_reg.predict(X)
plt.scatter(x, y)
plt.plot(x, y_predict, color="r")
plt.show()
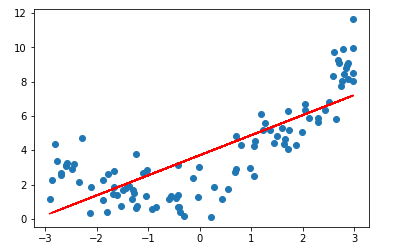
显然,拟合效果并不好。那么解决呢?
多项式回归的思路是:添加一个特征,即对于X中的每个数据进行平方。
# 创建一个新的特征
(X**2).shape
# 凭借一个新的数据数据集
X2 = np.hstack([X, X**2])
# 用新的数据集进行线性回归训练
lin_reg2 = LinearRegression()
lin_reg2.fit(X2, y)
y_predict2 = lin_reg2.predict(X2)
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict2[np.argsort(x)], color="r")
plt.show()
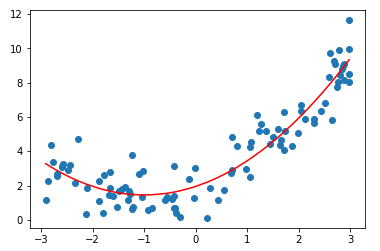
其第一个系数是x前的系数,第二个系数是前面的。输出其截距。
lin_reg2.coef_
# 输出:array([0.90802935, 1.04112467])
lin_reg2.intercept_
# 输出:2.3783560083768602
1-2、sklearn中的多项式回归
接下来我们使用sklearn里面的PolynomialFeatures和Pipeline两个类对此进行拟合。
from sklearn.preprocessing import PolynomialFeatures
# 这个degree表示我们使用多少次幂的多项式
poly = PolynomialFeatures(degree=2)
poly.fit(X)
X2 = poly.transform(X)
X2.shape
# 输出:(100, 3)
# 查看数据
X2[:5,:]

X2的结果第一列常数项,可以看作是加入了一列x的0次方;第二列一次项系数(原来的样本X特征),第三列二次项系数(X平方前的特征)。
在具体编程实践时,可以使用sklearn中的pipeline对操作进行整合。
首先我们回顾多项式回归的过程:
Pipeline就是将这些步骤都放在一起。参数传入一个列表,列表中的每个元素是管道中的一个步骤。每个元素是一个元组,元组的第一个元素是名字(字符串),第二个元素是实例化。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
poly_reg = Pipeline([
("poly", PolynomialFeatures(degree=2)),
("std_scale", StandardScaler()),
("lin_reg", LinearRegression())
])
poly_reg.fit(X, y)
y_predict = poly_reg.predict(X)
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict[np.argsort(x)], color="r")
plt.show()
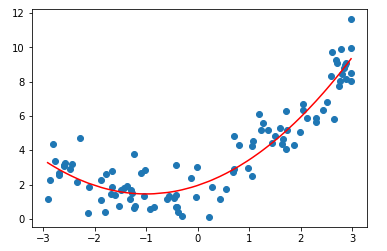
二、偏差与方差
当我们的模型表现不佳时,通常是出现两种问题,一种是 高偏差 问题,另一种是 高方差 问题。识别它们有助于选择正确的优化方式,所以我们先来看下 偏差 与 方差 的意义。
像打靶一样,偏差描述了我们的射击总体是否偏离了我们的目标,而方差描述了射击准不准。接下来让我们通过各种情况下 训练集 和 交叉验证集 的 误差 曲线来直观地理解 高偏差 与 高方差 的意义。

对于 多项式回归,当次数选取较低时,我们的 训练集误差 和 交叉验证集误差 都会很大;当次数选择刚好时,训练集误差 和 交叉验证集误差 都很小;当次数过大时会产生过拟合,虽然 训练集误差 很小,但 交叉验证集误差 会很大( 关系图如下 )。
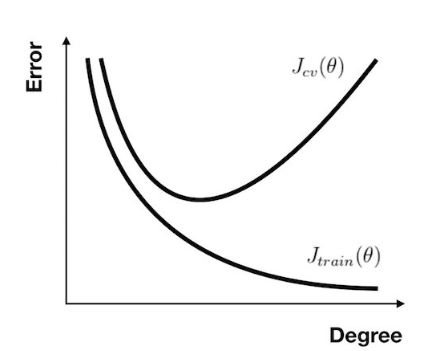

对于 正则化 参数,使用同样的分析方法,当参数比较小时容易产生过拟合现象,也就是高方差问题。而参数比较大时容易产生欠拟合现象,也就是高偏差问题。
三、L1、L2正则化
https://mp.weixin.qq.com/s/fbwx0mlG88YjFTNwYErnxQ
https://www.jianshu.com/p/ffb6808d54cd


![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)




 京公网安备 11010802041100号
京公网安备 11010802041100号