本文主要分享【机器学习里哪种方法好】,技术文章【机器学习概述】为【米卡粒】投稿,如果你遇到相关问题,本文相关知识或能到你。
1.1人工智能概述
达特茅斯会议-人工智能的起点
机器学习是人工智能的一个实现途径
深度学习是机器学习的一个方法发展而来
1.1.2机器学习、深度学习能做些什么
传统预测
图像识别
自然语言处理
1.2什么是机器学习
数据、模型、预测
从历史数据中获得规律?这些历史数据是怎么的格式?
1.2.3数据集构成
特征值+目标值
1.3机器学习算法分类
监督学习
目标值:类别——分类问题
k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归
目标值:连续型的数据-回归问题
线性回归、岭回归
目标值:无-无监督学习
聚类 k-means
1、预测明天的气温是多少? 回归
2、预测明天是阴、晴、雨? 分类
3、人脸年龄预测? 回归/分类
4、人脸识别 ? 分类
2.1数据集
2.1.1可用数据集
公司内部 百度
数据接口 花钱
数据集
学习阶段可以用的数据集:
1、sklearn
2、kaggle
3、UCI
1 Scikit-learn工具介绍
2.1.2sklearn数据集
sklearn.datasets
load_* 获取小规模数据集
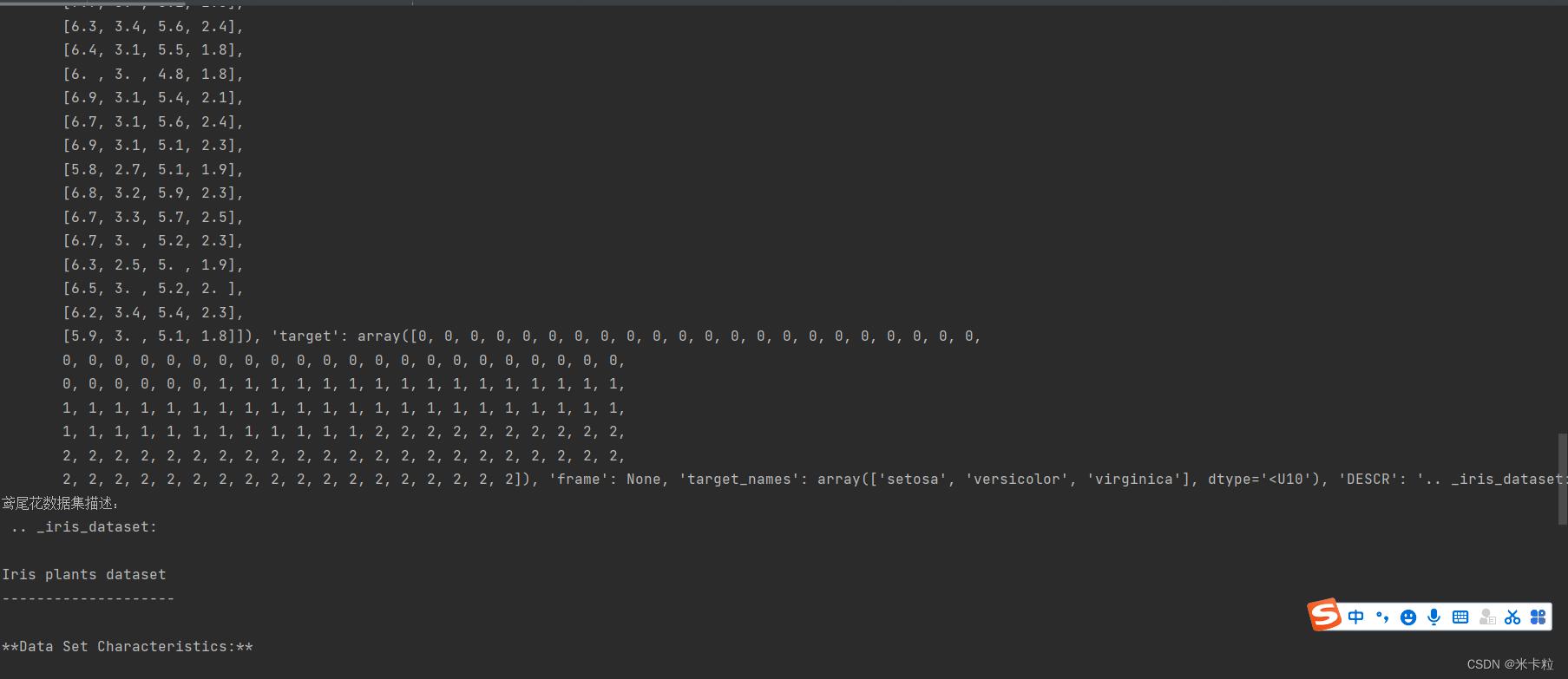
from sklearn.datasets import load_iris def datasets_demo(): """ sklearn数据集使用 :return: """ # 获取数据集 iris = load_iris() print("鸢尾花数据集:\n",iris) print("鸢尾花数据集描述:\n", iris["DESCR"]) print("鸢尾花特征值的名字:\n", iris.feature_names) print("鸢尾花特征值:\n", iris.data.shape) return None if __name__ == "__main__": # 代码1:sklearn数据集使用 datasets_demo()
运行如下(数据过多,展示部分)
fetch_* 获取大规模数据集
2 sklearn小数据集
sklearn.datasets.load_iris()
3 sklearn大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None)
4 数据集的返回值
datasets.base.Bunch(继承自字典)
dict["key"] = values
bunch.key = values
思考:拿到的数据是否都用来训练一个模型?
2.1.3数据集的划分
训练数据集:用于训练、构建模型
测试数据:在模型检验是使用,用于评估模型是否有效
测试集 20%~30%
sklearn.model_selection.train_test_split(arrays,*options)
训练集特征值,测试集特征值,训练集目标值,测试集目标值
x_train, x_test, y_train, y_test
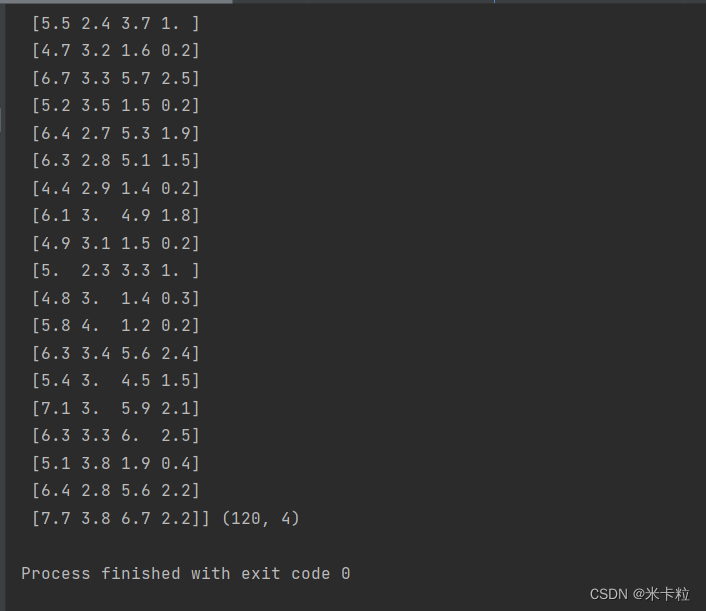
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split def datasets_demo(): """ sklearn数据集使用 :return: """ # 获取数据集 iris = load_iris() print("鸢尾花数据集:\n",iris) print("鸢尾花数据集描述:\n", iris["DESCR"]) print("鸢尾花特征值的名字:\n", iris.feature_names) print("鸢尾花特征值:\n", iris.data.shape) # 数据集的划分 x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22) print("训练数据集的特征:\n", x_train, x_train.shape) return None if __name__ == "__main__": # 代码1:sklearn数据集使用 datasets_demo()
部分运行结果如下
本文《机器学习概述》版权归米卡粒所有,引用机器学习概述需遵循CC 4.0 BY-SA版权协议。












 京公网安备 11010802041100号
京公网安备 11010802041100号