作者:天蝎快乐公主_594 | 来源:互联网 | 2022-04-27 04:33
Java爬虫Jsoup+httpclient获取动态生成的数据
前面我们详细讲了一下Jsoup发现这玩意其实也就那样,只要是可以访问到的静态资源页面都可以直接用他来获取你所需要的数据,详情情跳转-Jsoup爬虫详解,但是很多时候网站为了防止数据被恶意爬取做了很多遮掩,比如说加密啊动态加载啊,这无形中给我们写的爬虫程序造成了很大的困扰,那么我们如何来突破这个梗获取我们急需的数据呢,
下面我们来详细讲解一下如何获取
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
这时其实已经获取到了整个页面的数据,但是商品价格是通过回调函数获取后再填充上去的,所以这就要求我们写爬虫的开发者要很有耐心的去寻找价格数据的回调接口,我们直接访问这个接口就可以直接获取这个价格,下面是演示:
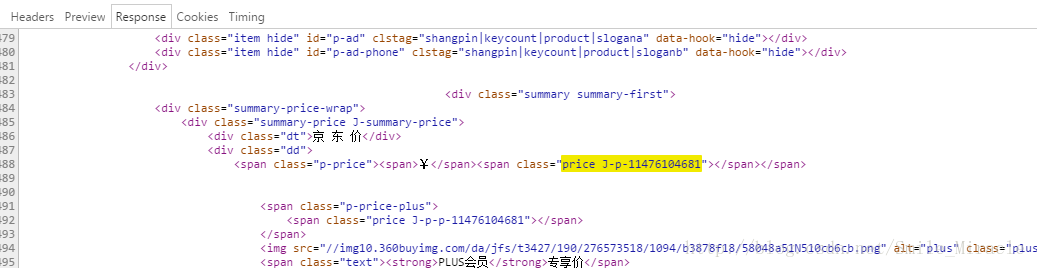
通过这张截图可以看到他传过来的只是一个静态资源页面根本没有价格参数,那么价格怎么来的呢,继续找发现这个接口:


你会发现在这个接口是很多参数拼接上去的,那么我们要做的就是分析是不是所有的参数都有用
https://p.3.cn/prices/mgets?callback=jQuery9734926&type=1&area=1&pdtk=
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
可以试着删除一些参数发现最终这个接口需要的参数其实很简单:
https://p.3.cn/prices/mgets?callback=jQuery9734926&type=1&area=1&skuIds=J_11476104681&source=item-pc
看到这里是不是很激动了,你其实可以换一些其他的JD商品ID一样能获取到当前价格和最高价格已经那什么价格我也不清楚,我们需要做的只是写一个Httpclient模拟请求这个接口
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets?callback=jQuery9734926&type=1&area=1&skuIds=J_"+"11476104681"+"&source=item-pc", null);
System.out.println(doGet);
结果是这样:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
至于后面的你直接解析下JSON字符串那么你要的数据就GET到了。
注意一下
这是对回调请求到的数据进行的再请求获取,这只是对前面动态获取商品价格的一个补充,这种情况是价格本身通过主链接没有带到页面上而是加载过程中异步请求填充的,还有的时候是数据带过来了但是有相关的JS进行了相关处理我们还是获取不到,这个时候我们就得通过其他手段来获取这个数据,后面会讲解
将这些Jsoup和httpclient整合成一个爬虫模板完全可以完成你一些基本的爬取数据的操作,至于怎么整合就看个人喜好了。
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!







 京公网安备 11010802041100号
京公网安备 11010802041100号