作者:络风落泪_411 | 来源:互联网 | 2023-05-17 12:31
前几天小菌分享的博客《用python爬虫制作图片下载器(超有趣!)》收到了粉丝们较多的关注,小菌决定再分享一些简单的爬虫项目给爬虫刚入门的小伙伴们,希望大家能在钻研的过程中,感受爬虫的魅力~
"""
@File : 酷狗Top500.py
@Time : 2019/10/21 22:31
@Author : 封茗囧菌
@Software: PyCharm
转载请注明原作者
创作不易,仅供分享
"""
import requests
from bs4 import BeautifulSoup
import time
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
def get_info(url):
web_data=requests.get(url,headers=headers)
soup=BeautifulSoup(web_data.text,'html.parser')
ranks=soup.select("span.pc_temp_num")
titles=soup.select("#rankWrap > div.pc_temp_songlist > ul > li > a")
times=soup.select("#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span")
for rank,title,time in zip(ranks,titles,times):
data={
'rank':rank.get_text().strip(),
'singer':title.get_text().split('-')[0],
'song':title.get_text().split('-')[1],
'time':time.get_text().strip()
}
print(data)
if __name__ == '__main__':
urls=['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(i)
for i in range(1,24)]
for url in urls:
print("开始爬取的URL:"+url)
get_info(url)
time.sleep(1)
效果图:

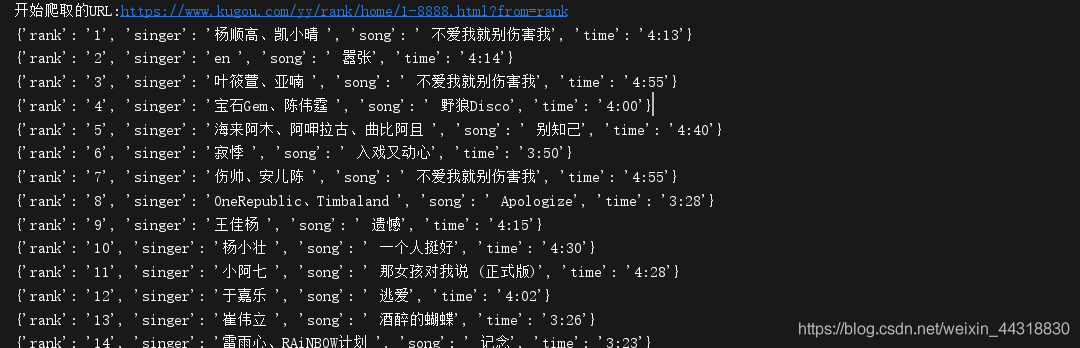
这次分享的爬虫项目非常适合爬虫初学者训练,希望大家能多多练习,本次的分享就到这里,喜欢的小伙伴们记得点赞加关注哦╰( ̄▽ ̄)╭








 京公网安备 11010802041100号
京公网安备 11010802041100号