作者:永无止境 | 来源:互联网 | 2023-01-22 19:49
这是我的HTML代码.
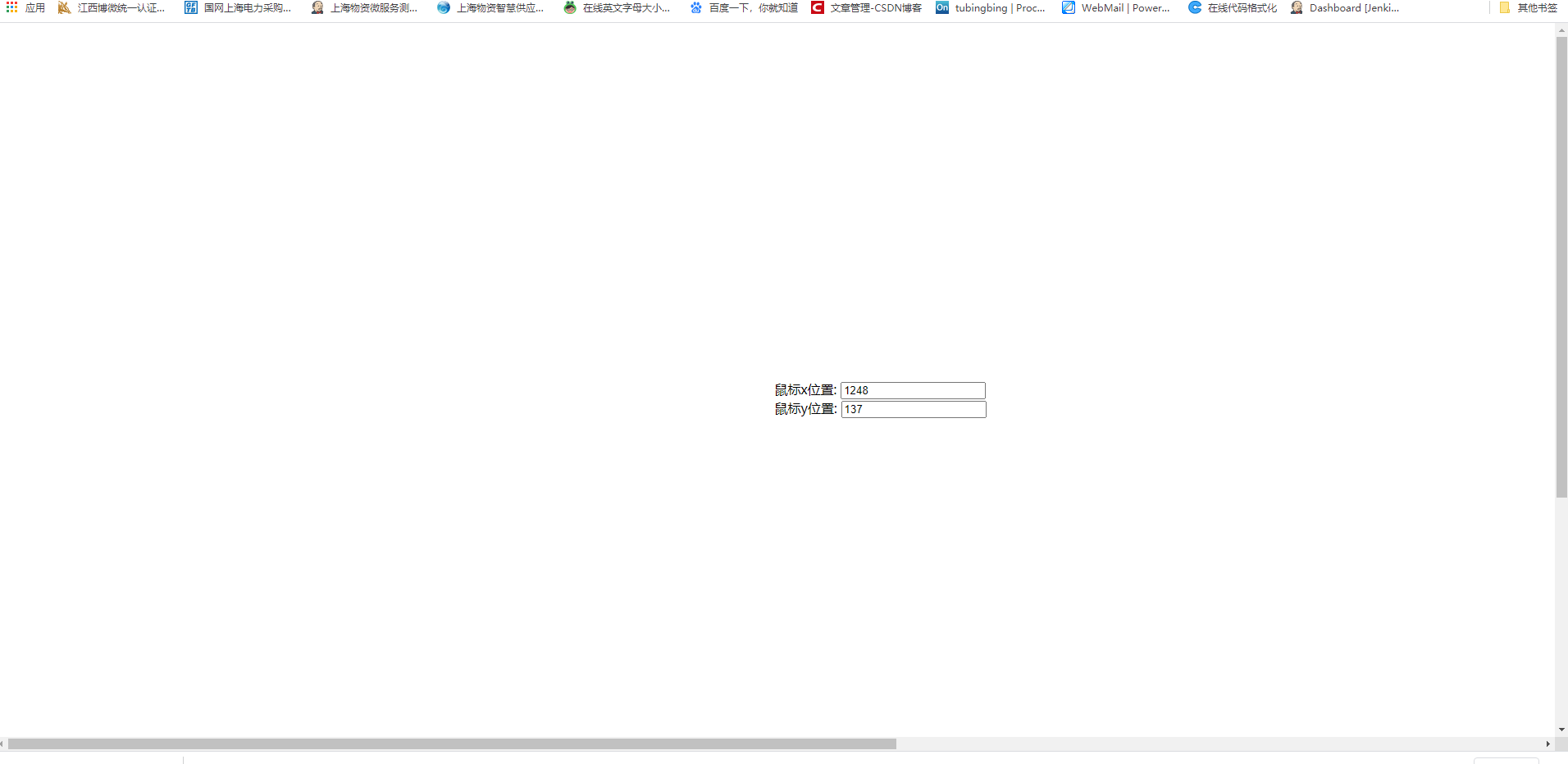
我将此代码保存在一个名为的文件中bar.html,然后使用Firefox或Chrome打开该页面.这是我在控制台中看到的输出.
现在我明白我的代码是不正确的,因为它有一个包含在<和中的URL >.
我想了解浏览器究竟是如何将其解析为一个http:标记,其中部分URL被解释为HTML属性.
HTML规范的某些部分是否会导致这种行为?如果是这样,你能引用HTML规范的这些部分吗?
1> BoltClock..:
您需要知道的一切都在8.2.4节中.特别是:
最多,解析器处于标记名称状态.元素的标记名称http:包括冒号,如
第一个/将解析器切换到自闭合开始标记状态.
所述第二 /导致解析错误,如步骤2中的链接所描述的,分析器切换到前属性名称状态.
解析器进入属性名称状态并继续使用URL.这是导致路径路径被视为属性名称的原因.
当解析器到达下一个时/,它会切换回自闭合开始标记状态并重复步骤2和3,除了它不是第二个/而是一个不同的字符(不是>)导致解析错误并切换解析器返回步骤3中的before属性名称状态.
解析器最终看到a后>,它会关闭开始标记,发出标记并继续正常进行.










 京公网安备 11010802041100号
京公网安备 11010802041100号