简介:Apache Flink Table Store 我的项目正在开发中,欢送大家试用和探讨。
作者:Jingsong Lee jingsonglee0@gmail.com
点击进入 Flink 中文学习网
一、数仓中的计算
在计算机领域,数据仓库(DW 或 DWH),是一个用于报告和数据分析的零碎,被认为是商业智能的一个外围组成部分。它将以后和历史数据存储在一个中央,为整个企业的工作人员创立剖析报告。[1]
典型的基于提取、转换、加载(ETL)的数据仓库应用 ODS 层、DWD 层和 DWS 层来包容其要害性能。数据分析师能够灵便的查问 (Query) 数仓中的每一层,获取有价值的商业信息。
数仓中有三个要害指标 [2]:
- 数据的新鲜度:数据从产生开始,到在仓库中通过一系列解决后可供用户查问所通过的工夫长度。通常 ETL 就是用来筹备数据的一系列过程,ETL 更多是通过调度运行一系列流计算或者批计算的作业来实现。
- 数据的查问延时:数据筹备好后,用户通过 Query 查问表中的数据,从用户收回查问到收到查问后果的工夫长度为查问延时。查问延时间接决定了终端用户的体感。
- 老本:实现一定量的数据分析(包含 ETL 和查问等各类计算)须要的资源量。老本也是数仓中的一个要害指标。
这三个指标的关系是什么呢?
- 企业须要在管制老本的状况下,能达到更好的查问延时和新鲜度。不同的数据可能有不同的老本要求。
- 新鲜度和查问延时在某些状况也是此消彼长的关系,比方应用更长时间来筹备数据、荡涤和预处理数据,查问会更快。
所以这三者形成了数仓中的一个三角 Tradeoff [2]:
(注:三角中,离顶点更近代表更好,离顶点更远代表更差)
对于这个三角 Tradeoff,业界目前的支流架构有着怎么样的取舍呢?
二、业界支流架构
典型的离线数仓:
离线数仓应用 Batch ETL 基于分区粒度来覆写 (INSERT OVERWRITE),在解决超大数据的场景的同时,有着很好的老本管制。
然而它有两个比较严重的问题:
- 新鲜度差:数据延时个别是 T + 1,即业务上当天产生的数据须要第二天能力查问到。
- 不善于解决更新流 (Changelog),离线数仓外面存储的都是 Append 数据,如果须要接管相似数据库变更日志的更新流,须要重复的合并全量数据和增量数据,老本激增。
为了解决上述问题,实时数仓逐步衰亡,一个典型的实时数仓实现是应用 Flink + Kafka 的计划构建中间层,最终写到在线数据库或剖析零碎中,达到秒级的全链路延时,有着十分好的数据新鲜度。
然而,它也逐步暴露出一些问题。
问题一,中间层不可查
存在 Kafka 中的数据查问受限,无奈灵便的进行 OLAP 查问,通常也没有保留长期历史数据。这与宽泛应用的数仓有很大不同,在一个成熟的 Warehouse 体系中,数仓中的每一个数据集都应该是可供查问的 Table 形象,而 Kafka 无奈满足用户对于 Table 形象的所有需要,比如说:
- 查问能力受限。实时数仓架构要求所有可供查问的数据集被事后计算,并且最终写入可供查问的剖析零碎,但理论业务中不是所有计算都能够事后定义的,数据分析师的大量需要是长期的 Ad hoc 查问,如果两头数据 Queue 不可查,这会重大限度业务的数据分析能力。
- 问题排查艰难。实时数仓中,如果数据有问题,用户须要排查数据 Pipeline,但因为存储两头后果的 Queue 不可查,导致排查难度十分高。
综上,咱们心愿能有对立的架构失去一个处处可查问的实时数仓,而不是两头后果被管道化的数仓。
问题二,实时链路老本高
天下没有收费的午餐,搭建一条实时链路是比拟低廉的。
- 存储老本:不论是 Kafka 还是前面的 ADS 层,它们都是在线服务,尽管有很低的延时,然而有很高的存储老本。
- 迁徙和保护老本:实时链路是与独立于离线的新的一套零碎,并不兼容离线的一套工具链,迁徙和保护老本都很大。
由此,咱们心愿能有一个低成本的实时数仓,它提供低运行老本并兼容离线工具链,同时减速原有的离线数仓。
总结:
| 离线数仓 |
实时数仓 |
| 老本 |
低 |
高 |
| 新鲜度 |
差 |
好 |
| 数仓两头表查问延时 |
高 |
无奈查问 |
| 数仓后果表查问延时 |
低 |
低 |
因为以后的两套架构面向不同的取舍和场景,所以业务通常只能保护两套架构,甚至须要不同的技术团队,这不仅在带来了很大的资源老本,也带来了低廉的开发成本和运维老本。
那么咱们是不是有可能提供一个在新鲜度、查问延时、查问能力和老本等各方面比拟平衡的数仓呢?为了答复这个问题,咱们须要剖析新鲜度和查问延时背地的技术原理,不同的 Tradeoff 导致的不同架构,以及它们背地的技术差别。
三、ETL 新鲜度
首先须要思考的是数据的新鲜度:数据的新鲜度掂量的是数据从产生开始,到在仓库中通过一系列解决后可供用户查问所通过的工夫长度。数据被摄入到数仓里,并且通过一系列 ETL 的解决后,数据才进入可用的状态。
传统的批计算是依照口径来进行 ETL 计算的,所以它的新鲜度是:口径 + ETL延时。个别的口径是天,所以传统离线数仓的新鲜度起码也是一天。依照口径来计算,计算的输出和输入是全量的。如果新鲜度要小于口径,计算的输出和输入是局部的,也就是增量的。典型的增量计算就是流计算,比方 Flink Streaming。
增量计算也不齐全等同于流计算,比方也能够有小批次的增量计算。全量计算不齐全等同于批计算,比方流计算也能够做 Window 来全量的输入 (也就是说流计算的提早也能够很大,这样能够降低成本);
四、Query Latency
查问延时会间接影响数据分析效率和体验,查问是返回给人看的,这个人不是机器人,他看到的数据是通过过滤或者聚合后的数据。在传统离线数仓中,查问大表往往可能须要 10+ 分钟的工夫。
减速查问的返回最直观的形式是预计算,实质上数仓的 ETL 就是在做预计算的事件,数据分析人员查问的计算须要的工夫太久时,他会告诉数仓人员,建设对应的 ETL Pipeline,数据筹备好后,剖析人员间接查问最终后果表即可。从一个角度上看,这其实是在用新鲜度换取更快的查问延时。
然而在传统离线数仓中,有大量的即席查问(Ad Hoc),用户依据本人的需要,灵便的抉择查问条件。有大表参加的查问往往可能须要 10+ 分钟的工夫,为了尽快的返回后果,各大存储系统应用了各种各样的优化伎俩。
比方存储更凑近计算,越凑近计算,读取越快:
- 一些 Message Queue 和 OLAP 零碎,它们只提供本地磁盘的存储,这保障了读取性能,然而也就义了灵活性,扩容和迁徙代价比拟大,老本也更高。
- 另一个方向是计算存储拆散的架构,数据全在近程,然而通过本地的 Cache,来减小近程拜访 DFS /Object Store 的昂扬代价。
比方 Data Skipping,联合查问的条件和字段,跳过不相干的数据来减速数据的查找:
- Hive:通过分区裁剪查问特定分区,通过列存跳过不相干的字段。
- 湖存储:在应用列存的根底上,引入文件的统计信息,依据文件的统计信息来尽量减少一些文件的不必要读取。
- OLAP 零碎:在应用列存的根底上,比方应用 LSM 构造来让数据尽可能依照主键有序,有序是最利于查问的构造之一,比方 Clickhouse。
- KV 零碎:通过数据的组织构造,应用 LSM 的构造来减速查问。
- Message Queue:Queue 其实是通过一种非凡的读取接口来达到疾速定位数据的能力,它只提供基于 Offset / Timestamp 的定位形式来接着增量读取数据。
还有很多优化伎俩,这里不一一枚举了,存储通过各种伎俩来配合计算减速查问,让查问找得快、读得快。
通过上述的剖析,咱们能够看到,不同零碎底层的技术根本都是相通的:
- 流计算和批计算是计算的不同模式,它们都能够实现全量计算或者增量计算。
- 存储减速查问性能的伎俩都是围绕着找得快和读得快,底层的原理是相通的。
实践上来说,咱们应该有可能通过底层技术的某种抉择和组合搭建某种架构,来达到咱们想要的 Tradeoff。这个对立的架构可能须要依据不同的 Tradeoff 解决以下场景:
- 实时数仓:新鲜度很好。
- 近实时数仓:作为离线数仓的减速,在不带来太昂扬的老本状况下,进步新鲜度。
- 离线数仓:有着比拟好的老本管制。
- 离线 OLAP:减速数仓的某一部分的查问性能,比方 ADS 表。
Streaming Warehouse 的指标是成为一个对立的架构:
(注:三角中,离顶点更近代表更好,离顶点更远代表更差)
一个现实的数仓应该是用户能够随便调整老本、新鲜度、查问延时之间的 Tradeoff,这要求数仓能齐全笼罩离线数仓、实时数仓、OLAP 的全副能力。Streaming Data Warehouse 在实时数仓的根底上往前走了一步,大幅升高了实时数仓的老本。
Streaming DW 在提供实时计算能力的同时,能够让用户在同套架构下笼罩离线数仓的能力。用户能够依据业务的需要作出相应的 Tradeoff,解决不同场景的问题。
五、Streaming Data Warehouse
在具体看 Streaming Data Warehouse 的存储架构是如何设计之前,咱们先来回顾一下之前提到的支流实时数仓的两个问题。解决了这两个问题,Streaming Data Warehouse 的架构设计也就跃然纸上了。
5.1 两头数据不可查
既然两头的 Kafka 存储不可查,一个实时离线一体化的想法是:实时离线一比一双跑,业务层去做尽可能多的封装,尽量让用户看到一套表的形象。
许多用户都会应用 Flink 加 Kafka 做实时数据流解决,将剖析后果写入在线服务层对用户进行展现或进一步剖析,与此同时将实时数仓中 Kafka 的数据导入到后盾的异步离线数仓,对实时数据进行补充,每天定期大规模的批量运行/全量运行或对历史数据定期修改。[3]
但这个架构存在着几个问题:
- Table 的形象不同:采纳不同的技术栈,实时链路跟离线链路有两套 Table 形象,岂但减少了开发成本,而且升高了开发效率;业务层尽可能的去封装,然而总会遇到各种磕磕碰碰的问题,有不少不对齐的坑。
- 实时数仓和离线数仓的数据口径难以放弃人造的一致性;
在 Streaming Data Warehouse 中,咱们心愿数仓有面向查问对立的 Table 形象,所有流动中的数据皆可剖析,没有数据盲点。这就要求这个对立的 Table 形象可能同时反对两种能力:
也就是说在同一个 Table 上,用户能够以音讯队列的形式订阅这个 Table 上的 Change Log,也能够对这个 Table 间接进行 OLAP 查问。
上面咱们再来看经典实时数仓的第二个问题。
5.2 实时链路老本高
尽管 Streaming Data Warehouse 提供的对立 Table 形象可能很好的解决新鲜度和查问提早的问题,但相较于离线数仓其老本是更高的。在很多时候并非所有的业务场景都对新鲜度和查问延时有很高的要求,因而提供低成本 Table 存储能力仍然是必要的。
这里湖存储是一个不错的抉择:
- 湖存储的存储老本更低:湖存储基于 DFS / Object Store,无 Service,资源和运维老本都更低。
- 湖存储的部分更新灵便:历史分区有问题怎么办?须要勘误怎么办?湖存储的计算成本更低,湖存储 + 离线 ETL,INSERT OVERWRITE 勘误历史分区,比实时更新成本低很多。
- 湖存储的开放性:湖存储能够凋谢给各种批计算引擎。
因而,Streaming Data Warehouse在放弃全链路数据实时流动的同时,还须要同时提供低成本的离线存储,并且做到架构不影响实时链路。因为通常来说实时链路的 SLA 要求比离线链路要高,因而 Streaming Data Warehouse 的存储在设计和实现上要把 Queue 的写入和生产作为高优先级,对历史数据的存储不应该影响其作为 Queue 的能力。
六、Flink Table Store
Flink Table Store [4] 正是专门为 Streaming Warehouse 打造的流批一体存储。
在过来的几年里,在咱们泛滥贡献者和用户的帮忙下,Apache Flink 曾经成为了最好的分布式计算引擎之一,特地是在大规模的有状态流解决方面。尽管如此,当大家试图从数据中实时取得洞察力时,依然面临着一些挑战。在这些挑战中,一个突出的问题是不足能满足所有计算模式的存储。
到当初为止,人们为不同的目标部署一些与 Flink 一起协同的存储系统是很常见的。一个典型的做法是部署一个用于流解决的音讯队列,一个用于批处理和 Ad-Hoc 查问的可扫描文件系统/对象存储,以及一个用于点查的 KV 存储。因为其复杂性和异构性,这样的架构在数据品质和系统维护方面都存在挑战。这曾经成为了一个侵害 Apache Flink 带来的流和批处理对立的端到端用户体验的次要问题。
Flink Table Store 的指标就是要解决上述问题。这对 Flink 来说是重要的一步,它将 Flink 的能力从计算畛域扩大到了存储畛域。也正因为这样,咱们能够为用户提供更好的端到端体验。
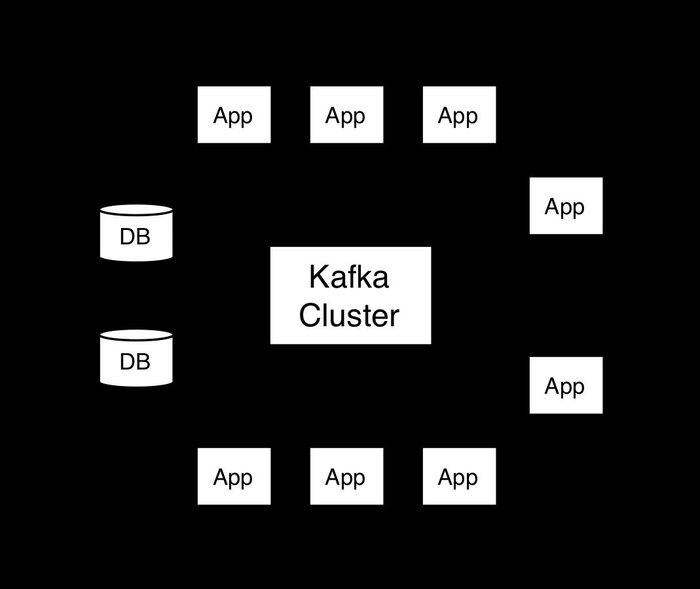
6.1 架构
6.1.1 Service
Coordinator 是集群的管控节点,它次要负责管理各 Executors,次要能力有:
- Coordinator 治理 Executors 的生命周期,客户端通过 Coordinator 寻找 Executors 的地址。
-
Data Manager:
- 治理 Table 的版本,负责与 Metastore 打交道,定期将版本 checkpoint 到 metastore 里。
- 依据写入的数据和查问的 Pattern,治理缓存、治理索引。
-
Resource Manager:
- 治理 Table 的 Buckets 在 Executors 的散布。
- 依据须要动静的调配 Buckets 到 Executors 上。
Metastore 是个形象的节点,它能够对接 Hive Metastore,也能够最小化依赖基于 Filesytem,也能够对接你本人的 Metastore,它保留了最根本的表信息。你不必放心性能问题,更具体的简单的表信息放在了湖存储里。
Executor 是一个独自的计算节点,作为存储的一个 Cache 和本地计算的减速单元:
- 它负责接收数据的更新,写入本地 Cache、写入本地磁盘、再 Flush 到底层的 DFS 中。
- 它也面向实时的 OLAP 查问和 Queue 的生产,执行一些减速的本地计算。
每个 Executor 负责一个或多个 Buckets,每个 Bucket 有对应的 Changelog,这些 Changelog 会保留在 Message Queue 里,次要用作:
- Write ahead log,Executor Failover 后读取 log 来复原数据。
- 提供 Queue 的形象,提供 Table 的 Changelog 流生产给上游的流计算。
6.1.2 湖存储
Executor 的数据通过了 Checkpoint 后就落入了湖存储中,湖存储建设在列存的文件格式和共享 DFS 存储上。湖存储提供残缺的 Table Format 形象,它的次要目标是以较低的老本撑持更新和读取:
- LSM 构造:用于大量的数据更新和高性能的查问。
- Columnar File Format:应用 Apache ORC 来反对高效查问。
- Lake Storage:元数据和数据在 DFS 和 Object Store 上。
6.1.3 冷热拆散
存储的读写门路被分为了两条:
- Streaming Pipeline & Online OLAP Query:通过 Coordinator 获取元数据,从 Executor 里写入和获取数据。
- Batch Pipeline & Offline Query:通过 Metastore 获取元数据,从湖存储中写入和获取数据。
Service 的数据是最新的,通过了分钟级的 Checkpoint 后同步到了湖存储中。所以用户读取湖存储只会读取到没那么及时的数据,实质上,两边的数据是统一的。
Service 和湖存储的应用有这些区别:
- Service 适宜最新的热数据,提供疾速的逐条 Update 写入,高性能的查问延时。
- Service 不适宜 Offline Query,一个是影响 Online 稳定性,另一个是老本会更高。
- Service 不反对 Batch Pipeline 的 INSERT OVERWRITE。
所以存储须要裸露湖存储来承当这些能力,那业务上如何判断哪些数据是在 Service 里操作,哪些数据在湖存储里操作呢?
只有 ARCHIVE 后的分区能力在湖存储中进行 Batch 的 INSERT OVERWRITE。
- 用户在创立表时能够指定分区主动 ARCHIVE 工夫。
- 也能够通过 DDL 语句显式的归档某个分区。
6.2 短期指标
6.2.1 短期架构
Streaming Data Warehouse 的整体改革是微小的,OLAP、Queue、湖存储、流计算、批计算,每一个畛域都有佼佼者在其中发力,明天还不可能短期内产出一个残缺的解决方案。
然而,咱们在后退,在 Apache Flink Table Store 中,咱们首先开发了基于 LSM 的湖存储,并原生集成了 Kafka 作为 Log System。
相比于上述章节的残缺架构,短期的架构没有 Coordinator 和 Excutors,这意味着它:
- 不能提供实时 OLAP 的能力,基于文件的 OLAP 只能是准实时的延时。
- 没有服务化数据管控的能力。
咱们心愿从底层做起,夯实根底,首先提出一个残缺的对立形象,再在存储上做减速能力,再提供实在时的 OLAP。
目前的架构它提供两个外围价值:
6.2.2 价值一:实时中间层可查
Table Store 给原有实时数仓的 Kafka 分层存储带来查问的能力,两头数据可查;
Table Store 依然具备流式实时 Pipeline 的能力,它原生 Log 集成,反对集成 Kafka,屏蔽掉流批的概念,用户只看到 Table 的形象。
然而值得注意的是,数据写入存储不应该影响原有写入 Kafka 的稳定性,这点是须要增强和保障的。
6.2.3 价值二:离线数仓减速
Table Store 减速离线数仓,兼容 Hive 离线数仓的同时,提供增量更新的能力。
Table Store 提供欠缺的湖存储 Table Format,提供准实时 OLAP 查问,LSM 的构造岂但有利于更新性能,也能够有更好的 Data Skipping,减速 OLAP 查问。
6.3 后续打算
社区目前正在致力增强外围性能,稳固存储格局,并补全残余的局部,使 Flink Table Store 为生产做好筹备。
在行将公布的 0.2.0 版本中,咱们心愿能够提供流批一体的 Table Format,逐步欠缺的流批一体湖存储,你能够期待(至多)以下的额定性能:
- 反对 Apache Hive 引擎的 Flink Table Store Reader。
- 反对调整 Bucket 的数量。
- 反对 Append Only 数据,Table Store 不只是限于更新场景。
- 残缺的 Schema Evolution,更好的元数据管理。
- 依据 0.1.0 预览版的反馈进行改良。
在中期,你也能够期待:
- 反对 Presto、Trino 和 Apache Spark 的 Flink Table Store Reader。
- Flink Table Store Service,以减速更新和进步查问性能,领有毫秒级的 Streaming Pipeline 能力,和较强的 OLAP 能力。
请试一试 0.1.0 预览版,在 Flink 邮件列表中分享您的反馈,并为我的项目作出贡献。
6.4 我的项目信息
Apache Flink Table Store 我的项目 [4] 正在开发中,目前曾经公布了第一个版本,欢送大家试用和反馈。
[1] Data warehouse Wiki: https://en.wikipedia.org/wiki/Data\_warehouse
[2] Napa: Powering Scalable Data Warehousing with Robust Query Performance at Google: http://vldb.org/pvldb/vol14/p2986-sankaranarayanan.pdf
[3] Flink Next:Beyond Stream Processing: https://mp.weixin.qq.com/s/CxHzYGf2dg8amivPJzLTPQ
[4] https://github.com/apache/flink-table-store
版权申明:本文内容由阿里云实名注册用户自发奉献,版权归原作者所有,阿里云开发者社区不领有其著作权,亦不承当相应法律责任。具体规定请查看《阿里云开发者社区用户服务协定》和《阿里云开发者社区知识产权爱护指引》。如果您发现本社区中有涉嫌剽窃的内容,填写侵权投诉表单进行举报,一经查实,本社区将立即删除涉嫌侵权内容。







 京公网安备 11010802041100号
京公网安备 11010802041100号