大家都知道namenode是hadoop中的一个很重要的节点,因为他存在着跟datanode的交互跟客户端的交互,存储着dotanode中的元数据,所以就很想学习他们是如何沟通并能保证数据在任何情况下都不会丢失那?
namenode的作用:
1.维护元数据信息。
2.维护hdfs的目录树。
3.相应客户端的请求。
我们先来看一下namenode大致的工作流程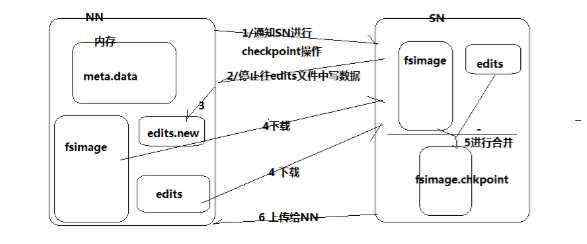
可以看到namenode这边里面有三个存储单位,edits文件,edits.new 文件 ,fsimage文件,还有内存。
edits文件默认为64M
1.首先当edits文件64M存满时,namenode就会通知secondNode进行checkpoint操作,告诉他我的edits文件满了。
2.secondNode就会回复你,文件满了就不要往edits文件写数据了呗,你在新建一个editsNew文件先往那里面写,你把fsimage跟edits文件给我吧。
3.namenode听到了secondNode的话后,哦了一声,那给你吧。second Node就去下载过来。
4.然后在secondNode里面来对两个文件进行合并成一个新的文件fsimage.chkpoint.
5.secondNode就告诉namenode这两个合并好了给你吧,namenode紧忙点头把合并好的文件拿了过来,当宝贝是的锁了起来。
6.namenode一看这个edits文件没用了啊,于是就给删除了,开始用edits.new文件并重命名为edits文件。
这就是一个namenode的工作机制,在这样的情况下,还是出现什么问题都能正常的跑,并且在不耽误使用的情况下。
但是如果是namenode当机了,那怎么办,相当与整个hadoop也就崩了。这个也就用到了hadoop的新机制HA,在这里不详细讲解,这个问题会留到HA那篇文章上写。
datanode那就没什么好说的了,就是一个存储 blk 块的服务器
然后我们在看一下hdfs的整个工作机制就能看明白了。

1.首先client会访问namenode看一下有没有这个文件,然后在告诉client有还是没有。
2.我接收到信息他说没有,那没有的话我可就要给你扔东西了,于是我把文件就往dataNode上面扔。
3.这个时候dataNode默认大写是128M,也就是说,你有一个300M的文件他会给你分成两份,按照128M去分,分别放到不同的dataNode中。
这样就可以了,可是想一个问题,万一我有一台dataNode当机了,也就相当于里面的数据我取不出来了,而dataNode是把文件分成了块,如果当机 了也就相当于我一大部分数据就毁了,所以怎么办那,嘿嘿,我们继续
4.dataNode会对这个文件进行备份,然后在分别放到不同的dataNode上面,而不是客户端数据传过来时就进行备份,这样多消耗性能啊。
好了,这就结束了,我也是个小学徒,如果有错误还请大家指教。








 京公网安备 11010802041100号
京公网安备 11010802041100号