跳表全称叫做跳跃表,简称跳表。跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
Skip List(跳跃列表)这种随机的数据结构,可以看做是一个二叉树的变种,它在性能上与红黑树、AVL树很相近;但是Skip List(跳跃列表)的实现相比前两者要简单很多,目前Redis的zset实现采用了Skip List(跳跃列表)(其它还有LevelDB等也使用了跳跃列表)。
RBT红黑树与Skip List(跳跃列表)简单对比:
RBT红黑树
Skip List跳跃列表
这里贴出Skip List的论文,需要详细研究的请看论文,下文部分公式、代码、图片出自该论文。
Skip Lists: A Probabilistic Alternative to Balanced Trees
https://www.cl.cam.ac.uk/teaching/2005/Algorithms/skiplists.pdf
先通过一张动图来了解Skip List的插入节点元素的流程,此图来自维基百科。
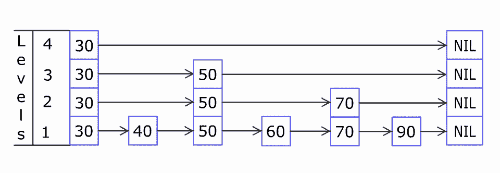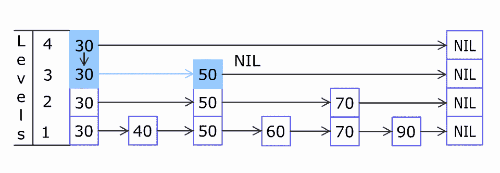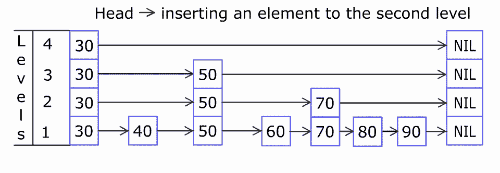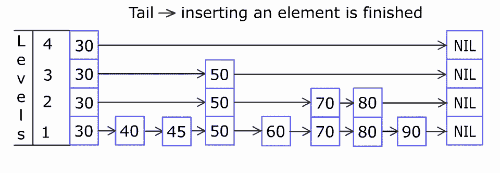
a50f862e502f718e490117c7a6541784.gif
2.3.1 计算随机层数算法
首先分析的是执行插入操作时计算随机数的过程,这个过程会涉及层数的计算,所以十分重要。对于节点他有如下特性:
计算随机层数的伪代码:
论文中的示例
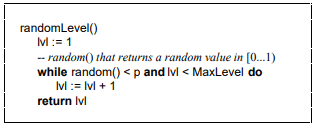
Java版本
1public int randomLevel(){
2 int level = 1;
3 // random()返回一个[0...1)的随机数
4 while (random() < p && level < MaxLevel){
5 level &#43;&#61; 1;
6 }
7 return level;
8}
代码中包含两个变量P和MaxLevel&#xff0c;在Redis中这两个参数的值分别是&#xff1a;
1p &#61; 1/4
2MaxLevel &#61; 64
2.3.2 节点包含的平均指针数目
Skip List属于空间换时间的数据结构&#xff0c;这里的空间指的就是每个节点包含的指针数目&#xff0c;这一部分是额外的内内存开销&#xff0c;可以用来度量空间复杂度。random()是个随机数&#xff0c;因此产生越高的节点层数&#xff0c;概率越低&#xff08;Redis标准源码中的晋升率数据1/4&#xff0c;相对来说Skip List的结构是比较扁平的&#xff0c;层高相对较低&#xff09;。其定量分析如下&#xff1a;
得出节点的平均层数&#xff08;节点包含的平均指针数目&#xff09;&#xff1a;

设C(k) &#61; 在无限列表中向上攀升k个level的搜索路径的预期成本&#xff08;即长度&#xff09;那么推演如下&#xff1a;
1C(0)&#61;0
2C(k)&#61;(1-p)×(情况b的查找长度) &#43; p×(情况c的查找长度)
3C(k)&#61;(1-p)(C(k)&#43;1) &#43; p(C(k-1)&#43;1)
4C(k)&#61;1/p&#43;C(k-1)
5C(k)&#61;k/p
上面推演的结果可知&#xff0c;爬升k个level的预期长度为k/p&#xff0c;爬升一个level的长度为1/p。
由于MaxLevel &#61; L(n)&#xff0c; C(k) &#61; k / p&#xff0c;因此期望值为&#xff1a;(L(n) – 1) / p&#xff1b;将L(n) &#61; log(1/p)^n 代入可得&#xff1a;(log(1/p)^n - 1) / p&#xff1b;将p &#61; 1 / 2 代入可得&#xff1a;2 * log2^n - 2&#xff0c;即O(logn)的时间复杂度。
Skip List跳跃列表通常具有如下这些特性
假设初始Skip List跳跃列表中已经存在这些元素&#xff0c;他们分布的结构如下所示&#xff1a;

此时查询节点88&#xff0c;它的查询路线如下所示&#xff1a;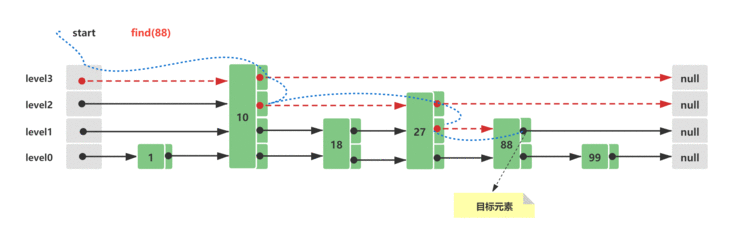
Skip List的初始结构与2.3中的初始结构一致&#xff0c;此时假设插入的新节点元素值为90&#xff0c;插入路线如下所示&#xff1a;
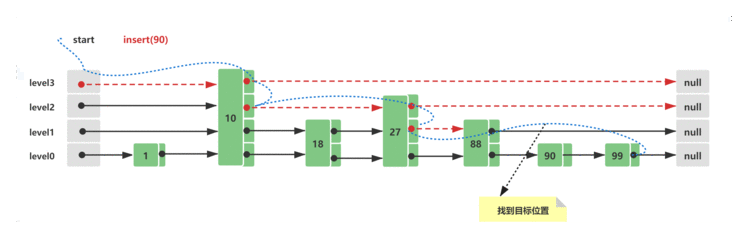
删除的流程就是查询到节点&#xff0c;然后删除&#xff0c;重新将删除节点左右两边的节点以链表的形式组合起来即可&#xff0c;这里不再画图
实现一个Skip List比较简单&#xff0c;主要分为两个步骤&#xff1a;
Node节点类主要包括如下重要属性&#xff1a;
5 * 跳表节点元素6 * 1package com.liziba.skiplist;23/**4 *
10 */
11public class Node {
12
13 /** 节点的分数值&#xff0c;根据分数值来排序 */
14 public Double score;
15 /** 节点存储的真实数据 */
16 public String value;
17 /** 当前节点的 前、后、下、上节点的引用 */
18 public Node prev, next, down, up;
19
20 public Node(Double score) {
21 this.score &#61; score;
22 prev &#61; next &#61; down &#61; up &#61; null;
23 }
24
25 public Node(Double score, String value) {
26 this.score &#61; score;
27 this.value &#61; value;
28 }
29}
SkipList主要包括如下重要属性&#xff1a;
7 * 跳表实现8 * 1package com.liziba.skiplist;23import java.util.Random;45/**6 *
100 copy.prev &#61; preNode;
101 copy.next &#61; preNode.next;
102 preNode.next.prev &#61; copy;
103 preNode.next &#61; copy;
104 copy.down &#61; curNode;
105 curNode.up &#61; copy;
106 curNode &#61; copy;
107
108 &#43;&#43;curLevel;
109 }
110 &#43;&#43;size;
111 }
112
113 /**
114 * 查询指定score的节点元素
115 * &#64;param score
116 * &#64;return
117 */
118 public Node search(double score) {
119 Node p &#61; head;
120 for (;;) {
121 while (p.next.score !&#61; null && p.next.score <&#61; score)
122 p &#61; p.next;
123 if (p.down !&#61; null)
124 p &#61; p.down;
125 else // 遍历到最底层
126 if (p.score.equals(score))
127 return p;
128 return null;
129 }
130 }
131
132 /**
133 * 升序输出Skip List中的元素 &#xff08;默认升序存储&#xff0c;因此从列表head往tail遍历&#xff09;
134 */
135 public void dumpAllAsc() {
136 Node p &#61; head;
137 while (p.down !&#61; null) {
138 p &#61; p.down;
139 }
140 while (p.next.score !&#61; null) {
141 System.out.println(p.next.score &#43; "-->" &#43; p.next.value);
142 p &#61; p.next;
143 }
144 }
145
146 /**
147 * 降序输出Skip List中的元素
148 */
149 public void dumpAllDesc() {
150 Node p &#61; tail;
151 while (p.down !&#61; null) {
152 p &#61; p.down;
153 }
154 while (p.prev.score !&#61; null) {
155 System.out.println(p.prev.score &#43; "-->" &#43; p.prev.value);
156 p &#61; p.prev;
157 }
158 }
159
160
161 /**
162 * 删除Skip List中的节点元素
163 * &#64;param score
164 */
165 public void delete(Double score) {
166 Node p &#61; search(score);
167 while (p !&#61; null) {
168 p.prev.next &#61; p.next;
169 p.next.prev &#61; p.prev;
170 p &#61; p.up;
171 }
172 }
173
174
175}



![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有