本文主要介绍关于运维的知识点,对【使用Prometheus+Grafana实时监控服务器性能】和【prometheus监控服务器索引】有兴趣的朋友可以看下由【wespten】投稿的技术文章,希望该技术和经验能帮到你解决你所遇的Linux Windows SRE 运维部署与监控相关技术问题。
Prometheus 是一套开源的系统监控报警框架。Prometheus 所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB):属于同一指标名称,同一标签集合的、有时间戳标记的数据流。除了存储的时间序列,Prometheus 还可以根据查询请求产生临时的、衍生的时间序列作为返回结果。
现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控。
Prometheus基本原理是通过HTTP协议周期性抓取被监控组件的状态,这样做的好处是任意组件只要提供HTTP接口就可以接入监控系统,不需要任何SDK或者其他的集成过程。这样做非常适合虚拟化环境比如VM或者Docker 。
Prometheus应该是为数不多的适合Docker、Mesos、Kubernetes环境的监控系统之一。
输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux 系统信息 (包括磁盘、内存、CPU、网络等等),具体支持的源看:Prometheus · GitHub。
与其他监控系统相比,Prometheus的主要特点是:
一个多维数据模型(时间序列由指标名称定义和设置键/值尺寸)。非常高效的存储,平均一个采样数据占~3.5bytes左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G。一种灵活的查询语言。不依赖分布式存储,单个服务器节点。时间集合通过HTTP上的PULL模型进行。通过中间网关支持推送时间。通过服务发现或静态配置发现目标。多种模式的图形和仪表板支持。Exporter
Exporter是Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取。
Grafana
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。
Prometheus生态系统整体架构
它的服务过程是这样的Prometheus daemon负责定时去目标上抓取metrics(指标) 数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。
Prometheus:支持通过配置文件、文本文件、zookeeper、Consul、DNS SRV lookup等方式指定抓取目标。支持很多方式的图表可视化,例如十分精美的Grafana,自带的Promdash,以及自身提供的模版引擎等等,还提供HTTP API的查询方式,自定义所需要的输出。
Alertmanager:是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
PushGateway:这个组件是支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
如果有使用过statsd的用户,则会觉得这十分相似,只是statsd是直接发送给服务器端,而Prometheus主要还是靠进程主动去抓取。
大多数Prometheus组件都是用Go编写的,它们可以轻松地构建和部署为静态二进制文件。访问prometheus.io以获取完整的文档,示例和指南。
Prometheus的数据模型
Prometheus从根本上所有的存储都是按时间序列去实现的,相同的metrics(指标名称) 和label(一个或多个标签) 组成一条时间序列,不同的label表示不同的时间序列。为了支持一些查询,有时还会临时产生一些时间序列存储。
metrics name&label指标名称和标签。
每条时间序列是由唯一的”指标名称”和一组”标签(key=value)”的形式组成。
指标名称:一般是给监测对像起一名字,例如http_requests_total这样,它有一些命名规则,可以包字母数字_之类的的。通常是以应用名称开头_监测对像_数值类型_单位这样。例如:
push_total、userlogin_mysql_duration_seconds、app_memory_usage_bytes标签:就是对一条时间序列不同维度的识别了,例如一个http请求用的是POST还是GET,它的endpoint是什么,这时候就要用标签去标记了。最终形成的标识便是这样了:
http_requests_total{method=”POST”,endpoint=”/api/tracks”}记住,针对http_requests_total这个metrics name无论是增加标签还是删除标签都会形成一条新的时间序列。
查询语句就可以跟据上面标签的组合来查询聚合结果了。
如果以传统数据库的理解来看这条语句,则可以考虑http_requests_total是表名,标签是字段,而timestamp是主键,还有一个float64字段是值了。(Prometheus里面所有值都是按float64存储)。
Prometheus四种数据类型
Counter
Counter用于累计值,例如记录请求次数、任务完成数、错误发生次数。一直增加,不会减少。重启进程后,会被重置。
例如:http_response_total{method=”GET”,endpoint=”/api/tracks”} 100,10秒后抓取http_response_total{method=”GET”,endpoint=”/api/tracks”} 100。
Gauge
Gauge常规数值,例如 温度变化、内存使用变化。可变大,可变小。重启进程后,会被重置。
例如: memory_usage_bytes{host=”master-01″} 100 <抓取值、memory_usage_bytes{host=”master-01″} 30、memory_usage_bytes{host=”master-01″} 50、memory_usage_bytes{host=”master-01″} 80 <抓取值。
Histogram
Histogram(直方图)可以理解为柱状图的意思,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。它特别之处是可以对记录的内容进行分组,提供count和sum全部值的功能。
例如:{小于10=5次,小于20=1次,小于30=2次},count=7次,sum=7次的求和值。
Summary
Summary和Histogram十分相似,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。同样提供 count 和 sum 全部值的功能。
例如:count=7次,sum=7次的值求值。
它提供一个quantiles的功能,可以按%比划分跟踪的结果。例如:quantile取值0.95,表示取采样值里面的95%数据。
二、Prometheus+Granfana安装配置node_exporter – 用于机器系统数据收集
Grafana是一个开源的功能丰富的数据可视化平台,通常用于时序数据的可视化。它内置了以下数据源的支持:
prometheus下载安装
1、下载
版本地址:Releases · prometheus/prometheus · GitHub
可以选择自己需要的版本,官网下载地址:Download | Prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.23.0/prometheus-2.23.0.linux-amd64.tar.gz如果通过wget方式下载太慢,建议用迅雷下载到本地,然后上传到服务器上。
2、安装
解压:
tar -xzvf prometheus-2.23.0.linux-amd64.tar.gz解压目录如下:
3、配置prometheus
修改配置文件:
vi prometheus.yml配置文件prometheus.yml注解:
global:
# 默认情况下,每15s拉取一次目标采样点数据。
scrape_interval: 15s
# 我们可以附加一些指定标签到采样点度量标签列表中, 用于和第三方系统进行通信, 包括:federation, remote storage, Alertmanager
external_labels:
# 下面就是拉取自身服务采样点数据配置
monitor: 'codelab-monitor'
scrape_configs:
# job名称会增加到拉取到的所有采样点上,同时还有一个instance目标服务的host:port标签也会增加到采样点上
- job_name: 'prometheus'
# 覆盖global的采样点,拉取时间间隔5s
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']4、启动服务
启动方式1:命令行启动
在安装完成以后,可以直接在命令行启动。启动方式通常是:
./prometheus --config.file=prometheus.yml & #最后的&不能少或者:
nohup /opt/prometheus/prometheus &如果要使用不同于9090的端口号,可以在命令行参数 --web.listen-address中指定,如:
./prometheus --config.file=prometheus.yml --web.listen-address=:8091 &启动以后,访问 http://xxx.xxx.xxx.xxx:8091,可以看到,端口确实更改了。
顺便说一下,要看prometheus的所有命令行参数,可以执行如下命令:
./prometheus -h启动方式2:服务方式启动
安装完成以后,也可以把prometheus配置成自启动的服务,在其中的配置文件中也可以自定义prometheus的启动端口。步骤如下:
1. 在 /usr/lib/systemd/system目录下创建新文件 prometheus.service,其中ExecStart字段指定启动参数时,设置自定义端口,内容如下:
--web.listen-address=:8091
[Unit]
Description=Prometheus Monitoring System
Documentation=Prometheus Monitoring System
[Service]
ExecStart=/opt/proe/prometheus-2.3.1.linux-amd64/prometheus \
--config.file=/opt/proe/prometheus-2.3.1.linux-amd64/prometheus.yml --web.enable-admin-api \
--web.listen-address=:8091
[Install]
WantedBy=multi-user.target2.执行命令:
systemctl start prometheus.service如果prometheus在运行,有时候要执行如下命令:
systemctl daemon-reload3.验证prometheus是否在新端口正常启动:
输入如下命令:
[root@k8s-node-3 system]# netstat -lntp |grep prometheus
tcp6 0 0 :::8091 :::* LISTEN 11758/prometheus可见端口已经是自定义的端口了。
访问:http://localhost:8099
安装Node_Exporter
#新建node_exporter文件夹
mkdir node_exporter
#定位到要下载的文件夹下
cd node_exporter
#下载node_exporter,如果下载速度慢,可以用迅雷先下载然后上传到服务器
wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-arm64.tar.gz
#解压
tar -xzvf node_exporter-1.0.1.linux-arm64.tar.gz
#定位到启动文件目录
cd node_exporter-1.0.1.linux-arm64
#启动node_exporter
./node_exporter修改prometheus配置文件:
配置node_exporter以服务方式启动:
#新建service文件
vi /usr/lib/systemd/system/node_exporter.service
#以下为node_exporter.service文件内容:
[Unit]
Description=node_exporter
Documentation=Node_exporter of Prometheus
[Service]
ExecStart=/usr/local/node_exporter/node_exporter-1.1.2.linux-amd64/node_exporter
[Install]
WantedBy=multi-user.target
#执行启动
systemctl daemon-reload
systemctl start node_exporter.service
#确认启动成功
netstat -antp | grep node_exporter修改好后重启prometheus。
然后刷新Prometheus界面展示,显示结果如下则表示启动成功。
Grafana下载安装
官网下载地址:Download Grafana | Grafana Labs
wget https://dl.grafana.com/oss/release/grafana-6.2.5-1.x86_64.rpm
sudo yum localinstall grafana-6.2.5-1.x86_64.rpm 默认安装路径:
# Home=/usr/share/grafana
# Data=/var/lib/grafana
# Logs=/var/log/grafana
# Plugins=/var/lib/grafana/plugins
# ProvisiOning=/etc/grafana/provisioning
# PidFile=/var/run/grafana/grafana-server.pid
# COnfig=/etc/grafana/grafana.ini
# DefualtCOnfig=/usr/share/grafana/conf/defaults.ini
添加到服务并自启动:
/sbin/chkconfig --add grafana-server
systemctl enable grafana-server.service启动服务:
service grafana-server start安装 zabbix 插件:
grafana-cli plugins install alexanderzobnin-zabbix-app查看安装:
find / -name grafana清除(卸载):
rpm -e grafana-5.3.2-1.x86_64
find / -name grafana -exec rm -rf {} \;修改密码:
grafana-cli admin reset-admin-password yourpassword则admin账号密码被重置为yourpassword。
启动成功后访问地址:服务器IP:3000会展示grafana登录界面,默认用户名密码都是admin,然后会让你重新设置密码,设置即可。
登录进去后展示界面如下:
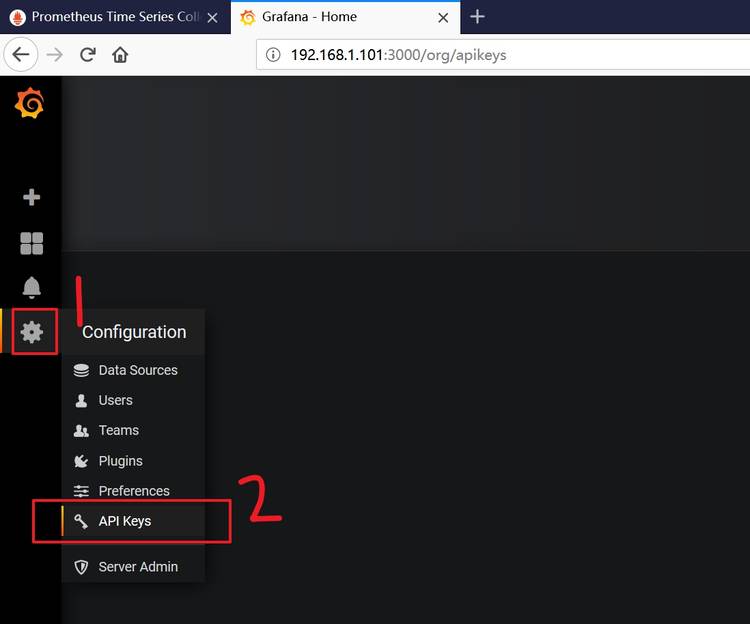
新建Prometheus数据库,点击设置图标,选择Data Sources:
点击Add data source,数据库选择Prometheus:
输入Prometheus的安装地址:http://IP:9090/,点击save and test按钮,显示如下图即表示配置成功。
下载展示模板
点击左上角Grafana的Home的下拉框,选择Import dashboard:
输入模板id:9276,然后点击空白处(这里输入后,点击空白处,会自动下载这个模板)。
选择已创建的prometheus数据库,点击Import。
最终展示结果如下:
监控本机,只需要一个exporter。下面是我们安装时用到的架构图:
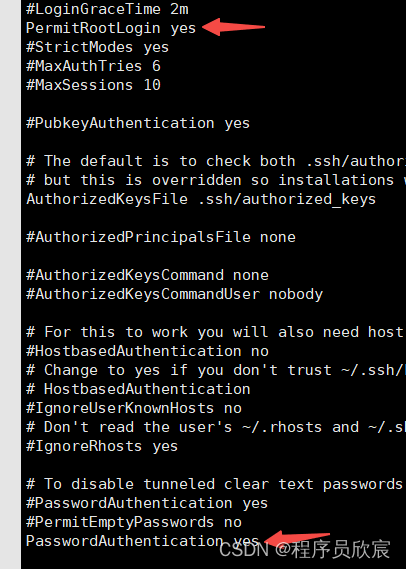
注意:本文使用的是ubuntu-16.04.5-server-amd64,只需要一台服务器即可!
安装docker
apt-get install -y docker.io注意:网上的文章说要安装docker-engine和docker-ce,那都是扯淡的。包压根都找不到!
只需要安装docker.io就可以了!
如果是Centos系统,使用 yum install -y docker-io 安装
下载镜像包
docker pull prom/node-exporter
docker pull prom/prometheus
docker pull grafana/grafana启动node-exporter
docker run -d -p 9100:9100 \
-v "/proc:/host/proc:ro" \
-v "/sys:/host/sys:ro" \
-v "/:/rootfs:ro" \
--net="host" \
prom/node-exporter等待几秒钟,查看端口是否起来了。
root@ubuntu:~# netstat -anpt
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1147/sshd
tcp 0 36 192.168.91.132:22 192.168.91.1:63648 ESTABLISHED 2969/0
tcp 0 0 192.168.91.132:22 192.168.91.1:63340 ESTABLISHED 1321/1
tcp6 0 0 :::9100 :::* LISTEN 3070/node_exporter访问url:
http://192.168.91.132:9100/metrics效果如下:
这些都是收集到数据,有了它就可以做数据展示了。
启动prometheus
新建目录prometheus,编辑配置文件prometheus.yml:
mkdir /opt/prometheus
cd /opt/prometheus/
vim prometheus.yml内容如下:
global:
scrape_interval: 60s
evaluation_interval: 60s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: linux
static_configs:
- targets: ['192.168.91.132:9100']
labels:
instance: localhost注意:修改IP地址,这里的192.168.91.132就是本机地址
启动 prometheus:
docker run -d \
-p 9090:9090 \
-v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus等待几秒钟,查看端口状态。
root@ubuntu:/opt/prometheus# netstat -anpt
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1147/sshd
tcp 0 36 192.168.91.132:22 192.168.91.1:63648 ESTABLISHED 2969/0
tcp 0 0 192.168.91.132:22 192.168.91.1:63340 ESTABLISHED 1321/1
tcp6 0 0 :::9100 :::* LISTEN 3070/node_exporter
tcp6 0 0 :::22 :::* LISTEN 1147/sshd
tcp6 0 0 :::9090 :::* LISTEN 3336/docker-proxy访问url:
http://192.168.91.132:9090/graph效果如下:
访问targets,url如下:
http://192.168.91.132:9090/targets效果如下:
如果状态没有UP起来,等待一会,就会UP了。
启动grafana
新建空文件夹grafana-storage,用来存储数据。
mkdir /opt/grafana-storage设置权限:
chmod 777 -R /opt/grafana-storage因为grafana用户会在这个目录写入文件,直接设置777,比较简单粗暴!
启动grafana:
docker run -d \
-p 3000:3000 \
--name=grafana \
-v /opt/grafana-storage:/var/lib/grafana \
grafana/grafana等待几秒钟,查看端口状态。
root@ubuntu:/opt/prometheus# netstat -anpt
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1147/sshd
tcp 0 36 192.168.91.132:22 192.168.91.1:63648 ESTABLISHED 2969/0
tcp 0 0 192.168.91.132:22 192.168.91.1:63340 ESTABLISHED 1321/1
tcp6 0 0 :::9100 :::* LISTEN 3070/node_exporter
tcp6 0 0 :::22 :::* LISTEN 1147/sshd
tcp6 0 0 :::3000 :::* LISTEN 3494/docker-proxy
tcp6 0 0 :::9090 :::* LISTEN 3336/docker-proxy
tcp6 0 0 192.168.91.132:9100 172.17.0.2:55108 ESTABLISHED 3070/node_exporter访问url:
http://192.168.91.132:3000/默认会先跳转到登录页面,默认的用户名和密码都是admin。
登录之后,它会要求你重置密码。你还可以再输次admin密码!
密码设置完成之后,就会跳转到首页。
点击Add data source,由于使用的是镜像方式,所以版本比较新。
name名字写Prometheus,type 选择Prometheus,因为数据都从它那里获取。url 输入Prometheus的ip+端口。
点击下面的Save & Test,如果出现绿色的,说明ok了。
回到首页,点击New dashboard。
点击 Graph。
效果如下:
点击标题下方的编辑:
效果如下:
输入cpu,底部会有提示:
这里监控 node_load15,表示系统15分钟的负载。点击下面的Add Query。
效果如下:
添加总内存:
这里会多出一条线。
点击右边的,可以删除掉总内存 。
点击General,修改标题为中文。
图表效果如下:
点击上面的保存按钮。
输入名字。
效果如下:
点击首页,就会有展示。
遇到的问题:
启动grafana容器时,提示容器已存在。
解决办法:
首先查看docker是否存在以及状态:执行docker ps -a (Exited状态表示已退出,up为运行中)。
如果状态为Exited,则执行:
docker run -d -p 3000:3000 grafana/grafana必须要加-d,否则前端界面关闭之后就不能再访问了。
三、 Prometheus和Grafana对本机服务器性能进行监控 1. CPUtype: Graph
Unit: short
max: "100"
min: "0"
Label: PercentageSystem - cpu 在内核模式下执行的进程占比
metrics:
sum by (mode)(irate(node_cpu_seconds_total{mode="system",instance=~"$node:$port",job=~"$job"}[5m])) * 100
User - cpu 在用户模式下执行的正常进程占比
metrics:
sum by (mode)(irate(node_cpu_seconds_total{mode='user',instance=~"$node:$port",job=~"$job"}[5m])) * 100Nice - cpu 在用户模式下执行的 nice 进程占比
metrics:
sum by (mode)(irate(node_cpu_seconds_total{mode='nice',instance=~"$node:$port",job=~"$job"}[5m])) * 100Idle - cpu 在空闲模式下的占比
metrics:
sum by (mode)(irate(node_cpu_seconds_total{mode='idle',instance=~"$node:$port",job=~"$job"}[5m])) * 100Iowait - cpu 在 io 等待的占比
metrics:
sum by (mode)(irate(node_cpu_seconds_total{mode='iowait',instance=~"$node:$port",job=~"$job"}[5m])) * 100
Irq - cpu 在服务中断的占比
metrics:
sum by (mode)(irate(node_cpu_seconds_total{mode='irq',instance=~"$node:$port",job=~"$job"}[5m])) * 100Softirq - cpu 在服务软中断的占比
metrics:
sum by (mode)(irate(node_cpu_seconds_total{mode='softirq',instance=~"$node:$port",job=~"$job"}[5m])) * 100
Steal - 在 VM 中运行时其他 VM 占用的本 VM 的 cpu 的占比
metrics:
sum by (mode)(irate(node_cpu_seconds_total{mode='steal',instance=~"$node:$port",job=~"$job"}[5m])) * 100
Guest - 运行各种 VM 使用的 CPU 占比
metrics:
sum by (mode)(irate(node_cpu_seconds_total{mode='guest',instance=~"$node:$port",job=~"$job"}[5m])) * 100type: Graph
Unit: bytes
min: "0"
Label: BytesApps - 用户空间应用程序使用的内存
metrics:
node_memory_MemTotal_bytes{instance=~"$node:$port",job=~"$job"} - node_memory_MemFree_bytes{instance=~"$node:$port",job=~"$job"}
- node_memory_Buffers_bytes{instance=~"$node:$port",job=~"$job"} - node_memory_Cached_bytes{instance=~"$node:$port",job=~"$job"}
- node_memory_Slab_bytes{instance=~"$node:$port",job=~"$job"} - node_memory_PageTables_bytes{instance=~"$node:$port",job=~"$job"}
- node_memory_SwapCached_bytes{instance=~"$node:$port",job=~"$job"}PageTables - 用于在虚拟和物理内存地址之间映射的内存
metrics:
node_memory_PageTables_bytes{instance=~"$node:$port",job=~"$job"}SwapCache - 用于跟踪已从交换区中提取出来但尚未修改的页面的内存
metrics:
node_memory_SwapCached_bytes{instance=~"$node:$port",job=~"$job"}Slab - 内核用于缓存数据结构以供自己使用的内存(如 inode,dentry 等缓存)
metrics:
node_memory_Slab_bytes{instance=~"$node:$port",job=~"$job"}
Cache - 频繁访问的文件数据或内容的缓存
metrics:
node_memory_Cached_bytes{instance=~"$node:$port",job=~"$job"}Buffers - 块设备(例如硬盘)缓存
metrics:
node_memory_Buffers_bytes{instance=~"$node:$port",job=~"$job"}
Unused - 未使用的内存大小
metrics:
node_memory_MemFree_bytes{instance=~"$node:$port",job=~"$job"}Swap - 交换分区使用的空间
metrics:
(node_memory_SwapTotal_bytes{instance=~"$node:$port",job=~"$job"} - node_memory_SwapFree_bytes{instance=~"$node:$port",job=~"$job"})
Harware Corrupted - 内核识别为已损坏或不工作的内存量
metrics:
node_memory_HardwareCorrupted_bytes{instance=~"$node:$port",job=~"$job"}type: Graph
Unit: bytes/sec
Label: Bytes out(-)/in(+){ {device}} - Receive 各个网络接口下载速率
metrics:
irate(node_network_receive_bytes_total{instance=~"$node:$port",job=~"$job"}[5m]){
{device}} - Transmit 各个网络接口上传速率
metrics:
irate(node_network_transmit_bytes_total{instance=~"$node:$port",job=~"$job"}[5m])type: Graph
Unit: bytes
min: "0"
Label: Bytes
metrics:node_filesystem_size_bytes{instance=~"$node:$port",job=~"$job",device!~'rootfs'} - node_filesystem_avail_bytes{instance=~"$node:$port",job=~"$job",device!~'rootfs'}type: Graph
Unit: I/O ops/sec (iops)
Label: IO read(-)/write(+){ {device}} - Reads completed 磁盘的读取速率(五分钟内)
metrics:
irate(node_disk_reads_completed_total{instance=~"$node:$port",job=~"$job",device=~"[a-z]*[a-z]"}[5m]){ {device}} - Writes completed 磁盘的写入速率(五分钟内)
metrics:
irate(node_disk_writes_completed_total{instance=~"$node:$port",job=~"$job",device=~"[a-z]*[a-z]"}[5m])type: Graph
Unit: bytes
Label: Bytes read(-)/write(+)成功读取的字节数(五分钟内)
metrics:
irate(node_disk_read_bytes_total{instance=~"$node:$port",job=~"$job",device=~"[a-z]*[a-z]"}[5m])成功写入的字节数(五分钟内)
metrics:
irate(node_disk_written_bytes_total{instance=~"$node:$port",job=~"$job",device=~"[a-z]*[a-z]"}[5m])type: Graph
Unit: ms
Label: Milliseconds
metrics:irate(node_disk_io_time_seconds_total{instance=~"$node:$port",job=~"$job",device=~"[a-z]*[a-z]"} [5m])本文《使用Prometheus+Grafana实时监控服务器性能》版权归wespten所有,引用使用Prometheus+Grafana实时监控服务器性能需遵循CC 4.0 BY-SA版权协议。
![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 