作者:駱宏艷_230 | 来源:互联网 | 2022-12-09 10:14
我想知道使用gunicorn和芹菜部署容器化Django应用程序的正确方法是什么.
具体来说,这些过程中的每一个都具有垂直缩放的内置方式,workers用于炮弹和concurrency芹菜.然后是Kubernetes使用缩放方法replicas
还有这种将工人设置为与CPU的某些功能相等的概念.Gunicorn建议
每个核心2-4名工人
但是,我很困惑这对于K8而言是什么,其中CPU是可分割的共享资源 - 除非我使用resoureceQuotas.
我想了解最佳实践是什么.我能想到三个选项:
有单独的工人为gunicorn和1并用于芹菜,并使用复制品进行扩展吗?(水平缩放)
使用内部缩放(垂直缩放)在单个副本部署中运行gunicorn和芹菜.这意味着分别设置相当高的工人和并发值.
1到2之间的混合方法,我们运行gunicorn和芹菜,工作者和并发的值很小(比如说2),然后使用K8s Deployment副本进行水平扩展.
关于此问题,有一些问题,但没有一个提供深入/深思熟虑的答案.如果有人可以分享他们的经验,我将不胜
注意:我们使用默认worker_class sync为Gunicorn
1> stacksonstac..:
这些技术并不像最初看起来那么相似.它们涉及应用程序堆栈的不同部分,实际上是互补的.
Gunicorn用于扩展Web请求并发,而芹菜应该被视为工作队列.我们很快就会到达kubernetes.
Gunicorn
Web请求并发主要受网络I/O或"I/O绑定"的限制.可以使用线程提供的协作调度来缩放这些类型的任务.如果您发现请求并发性限制了您的应用程序,那么增加gunicorn工作线程可能就是开始的地方.
芹菜
繁重的任务,例如压缩图像,运行一些ML算法,是"CPU绑定"任务.它们不能像更多的CPU一样受益于线程化.这些任务应该由芹菜工人卸载和并行化.
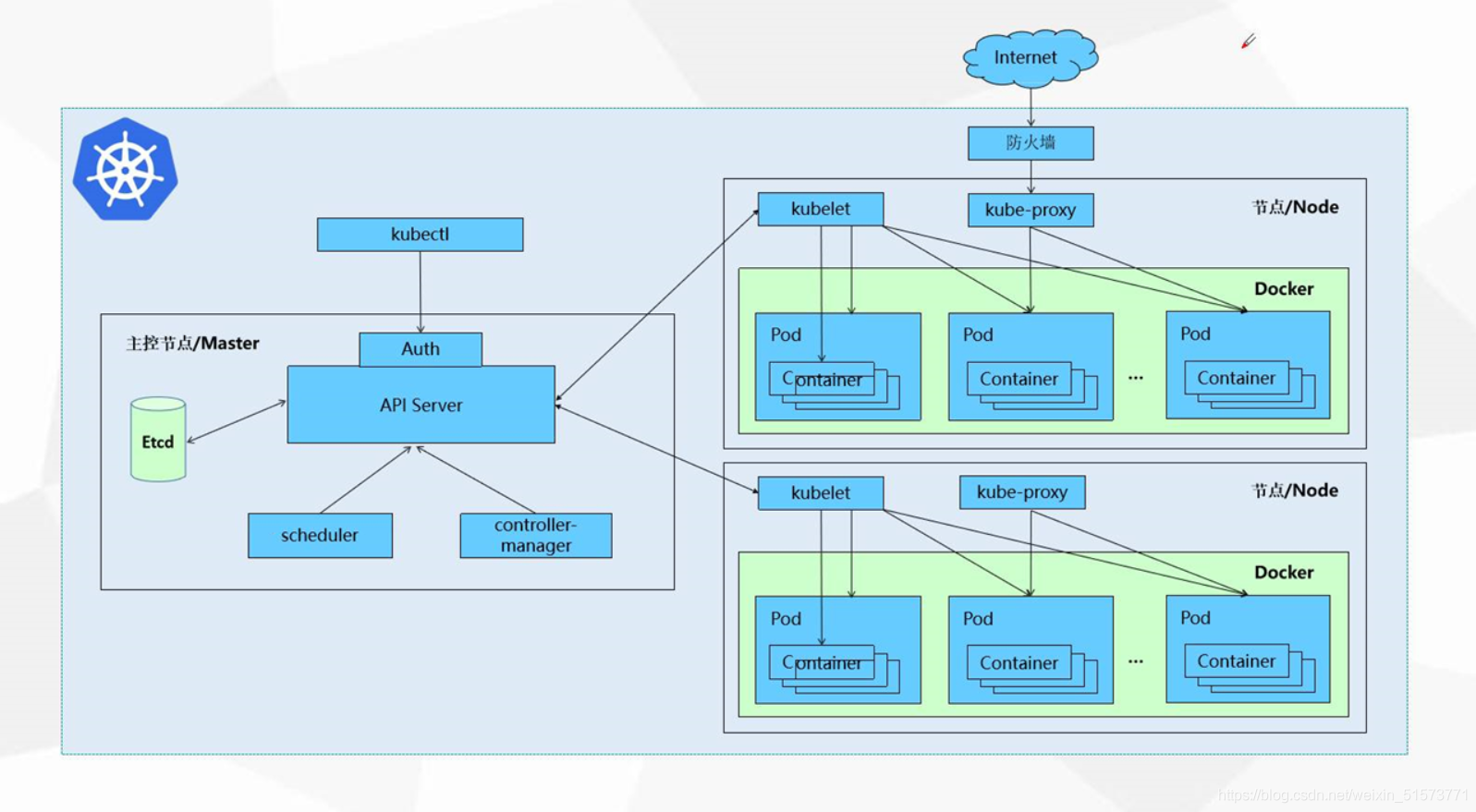
Kubernetes
Kubernetes派上用场的方法是提供开箱即用的水平可扩展性和容错能力.
在架构上,我将使用两个单独的k8s部署来表示应用程序的不同scalablity问题.Django应用程序的一个部署和芹菜工作者的另一个部署.这允许您独立地扩展请求吞吐量与处理能力.
我运行芹菜工人固定到每个容器的单个核心(-c 1)这极大地简化了调试并坚持Docker的"每个容器一个进程"的口头禅.它还为您提供了可预测性的额外好处,因为您可以通过增加副本计数来扩展每个核心的处理能力.
缩放Django应用程序部署是您需要DYOR来查找特定应用程序的最佳设置的地方.再坚持使用,--workers 1因此每个容器只有一个进程,但您应该尝试--threads找到最佳解决方案.再次通过简单地更改副本计数,将水平缩放保留给Kubernetes.
HTH这绝对是我在处理类似项目时必须要解决的问题.
2> 小智..:
我们用Django和Celery运行Kubernetes kluster,并实现了第一种方法.因此,我对这种权衡的一些想法以及为什么我们选择这种方法.
在我看来,Kubernetes就是关于水平扩展你的副本(称为部署).在这方面,最有意义的是将您的部署尽可能地单独使用,并在需求增加时增加部署(如果用完则增加容量).因此,LoadBalancer管理Gunicorn部署的流量,Redis队列管理Celery工作人员的任务.这可以确保底层的docker容器简单而小巧,我们可以根据需要单独(并自动)扩展它们.
至于您对每次部署需要多少workers/ 多少concurrency需求的想法,这实际上取决于您运行Kubernetes的底层硬件,并且需要实验才能正确运行.
例如,我们在Amazon EC2上运行我们的集群,并尝试使用不同的EC2实例类型并workers平衡性能和成本.每个实例拥有的CPU越多,所需的实例越少,workers每个实例的部署就越多.但我们发现在我们的案例中部署更小的实例更便宜.我们现在部署多个m4.large实例,每个部署有3个worker.
有趣的旁注:我们gunicorn与亚马逊负载平衡器相结合的性能非常糟糕,因此我们改用uwsgi了性能提升.但原则是一样的.







 京公网安备 11010802041100号
京公网安备 11010802041100号