第1章 awk
1 awk简介
awk不仅仅时linux系统中的一个命令,而且是一种编程语言,可以用来处理数据和生成报告(excel)。处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入,awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。
awk指令是由模式,动作,或者模式和动作的组合组成。
- 正则表达式作为模式
- 比较表达式作为模式
- 范围模式
- 特殊模式BEGIN和END
- awk默认就支持的元字符
| 功能 | 示例 | 解释 | |
| ^ | 字符串开头 | /^k/或$3~/^k/ | 匹配所有以k开头的字符串;匹配出所有第三列中以k开头的 |
| $ | 字符串结尾 | /a$或$3~/a$/ | 匹配所有以a结尾的字符串;匹配第三列中以a结尾的 |
| .(点) | 匹配任意但个字符(包括回车符) | /c..l/ | 匹配字母c,然后两个任意字符,再以l结尾的行 |
| * | 重复0个或多个前一个字符 | /a*cool/ | 匹配0个或多个a之后紧跟着cool的行 |
| + | 重复前一个字符一次或多次 | /a+b/ | 匹配一个或多个a加上字符串b的行 |
| ? | 匹配0个或一个前边的字符 | /a?b/ | 匹配以字母a或b或c开头的行 |
| [] | 匹配指定字符组内的任一个字符 | /^[abc]/ | 匹配以字母a或b或c开头的行 |
| [^] | 匹配不在指定字符组内的任一字符 | /^[^abc]/ | 匹配不以字母a或b或c开头的行 |
| () | 子表达式组合 | /(nimei)+/ | 表示一个或多个cool组合,当有一些字符需要组合时,使用括号括起来 |
| | | 或者的意思 | /(A)|B/ | 匹配A或字母B的行 |
awk默认不支持的元字符:(参数--posix)
| 元字符 | 功能 | 示例 | 解释 |
| x{m} | x字符重复m次 | /cool{5}/ | 匹配cool字符5次 |
| x{m,} | x字符重复至少m次 | /(cool){2,}/ | 匹配cool整体,至少2次 |
| x{m,n} | x字符重复至少m次,但不超过n次 | /(cool){5,6}/ | 匹配cool整体,至少5次,最多6次 |
awk -F ":" &#39;NR>&#61;2 && NR<&#61;6{print NR,$1}&#39; 文件
-F&#xff1a;参数-F指定awk按照什么标志进行文件分割&#xff0c;切割成一列一列的&#xff0c;如果不见-F参数&#xff0c;awk默认按照空格进行文件分割。
":"&#xff1a;指定“ &#xff1a;”作为分割标志
NR>&#61;2 && NR<&#61;6&#xff1a;这部分表示模式&#xff0c;是一个条件&#xff0c;表示取第2行到第6行
{print NR,$1}&#xff1a;这部分表示动作&#xff0c;表示要输出NR行号和$1第一列。
$0&#xff1a;表示默认全输出。$NF:表示去每行最后一组元素
awk -F ":" &#39;BEGIN{}模式{动作}END{}&#39;
BEGIN{}&#xff1a;开始模式&#xff08;告诉awk要如何读&#xff09; END{}&#xff1a;结束模式&#xff08;告诉awk要如何结束&#xff09;
BEGIN有读如换行符和输出换行符&#xff1a;BEGIN{RS&#61;"/";ORS&#61;"任意符号"}
问题&#xff01;1 看文件/etc/passed&#xff0c;把所有的英文单字取出来排序&#xff0c;看那个单词的重复最多&#xff0c;看前十行&#xff1f;
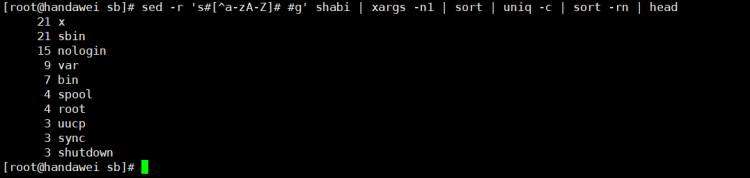
sed -r &#39;s#[^a-zA-Z]# #g&#39; shabi | xargs -n1 | sort | uniq -c | sort -rn | head
s#[]# #g:表示把中括号里的内容替换成空行
[^a-zA-Z]:表示取反
xargs -n1:表示每一行只有一个元素
sort:默认按照26个字母排序。
参数&#xff1a;-n默认按照数字排序
-r 逆转排序
Uniq:相同元素去重
参数:-c 去重复单词时并统计次数
问题&#xff01;2 &#xff1a;去除网eth0的IP地址&#xff1f;
方法一&#xff1a;hostname -I

方法二&#xff1a;ifconfig eth0 | awk &#39;BEGIN{RS&#61;"[ :]"}NR&#61;&#61;31&#39;

方法三 &#xff1a;ifconfig eth0 | awk -F "[ :]&#43;" &#39;NR&#61;&#61;2{print $4}&#39;

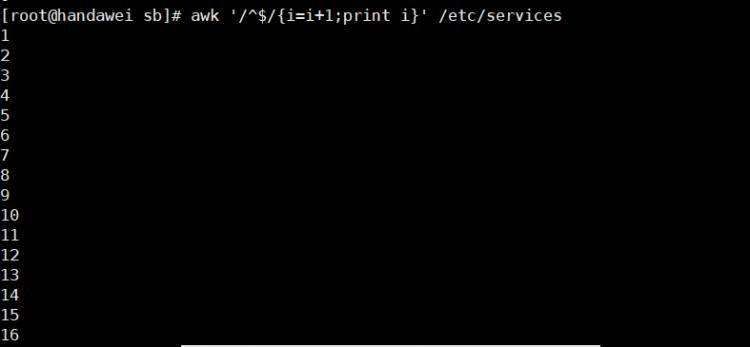
问题&#xff01;3 查看文件一共有多少空行&#xff1f;
方法一 &#xff1a;grep -c "^$" /etc/services

方法二 &#xff1a;awk &#39;/^$/{print $0}&#39; /etc/services | wc -l

方法三 &#xff1a;awk &#39;/^$/{i&#61;i&#43;1;print i}&#39; /etc/services
方法四 &#xff1a; awk &#39;/^$/{i&#61;i&#43;1}END{print i}&#39; /etc/services
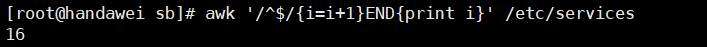








 京公网安备 11010802041100号
京公网安备 11010802041100号