作者:小鱼2502907687 | 来源:互联网 | 2023-01-23 17:20
摘要:现在的模型以及其参数愈加复杂,仅仅一两张的卡已经无法满足现如今训练规模的要求,分布式训练应运而生。
本文分享自华为云社区《分布式训练Allreduce算法》,原文作者:我抽签必中。
现在的模型以及其参数愈加复杂,仅仅一两张的卡已经无法满足现如今训练规模的要求,分布式训练应运而生。
分布式训练是怎样的?为什么要使用Allreduce算法?分布式训练又是如何进行通信的?本文就带你了解大模型训练所必须的分布式训练Allreduce算法。
通信概念
我们理解计算机的算法都是基于一个一个函数操作组合在一起得到的,那么我们在讲解分布式算法之前,我们必须先了解一下组成这种算法所应用于硬件的函数操作——集合通信的基本概念,
Broadcast(广播):将根服务器(Root Rank)上的数据分发广播给所有其他服务器(Rank)
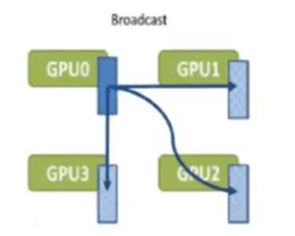
如图所示,当一台服务器计算完成了自己部分的参数数据,在分布式训练中想要把自己这部分数据同时发送给其他所有服务器,那么这种操作方式就叫做广播(broadcast)。
Scatter(散射):将根服务器上的数据散射为同等大小的数据块,每一个其他服务器得到一个数据块
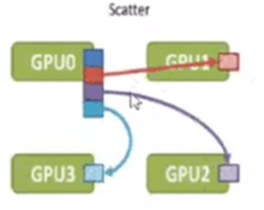
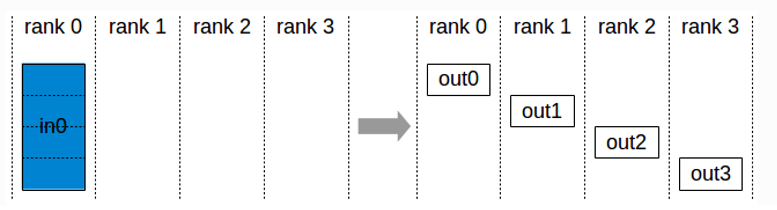
如图所示,当一台服务器计算完成自己部分的参数数据,但是因为有时候服务器上全部的参数数据过大,于是我们想要把这台服务器上的数据切分成几个同等大小的数据块(buffer),再按照序列(rank index)向其他服务器发送其中的一个数据块,这就叫做散射(Scatter)。
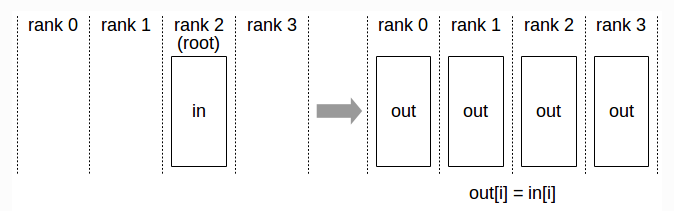
Gather(聚集):将其他服务器上的数据块直接拼接到一起,根服务器(Root Rank)获取这些数据
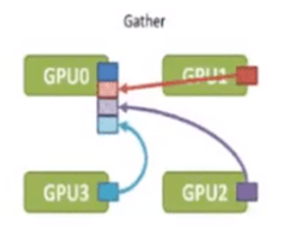
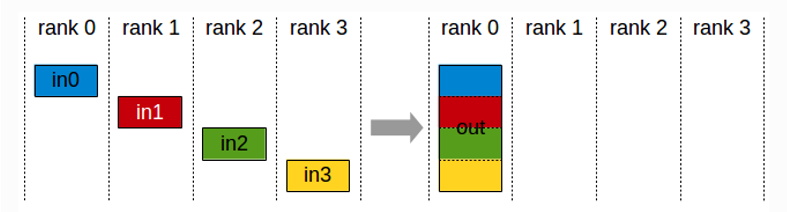
如图所示,当服务器都做了散射之后,每个服务器获得了其他服务器的一个数据块,我们将一台服务器获得的数据块拼接在一起的操作就叫做聚集(Gather)。
AllGather(全聚集):所有的服务器都做上述Gather的操作,于是所有服务器都获得了全部服务器上的数据
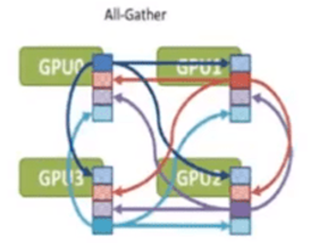
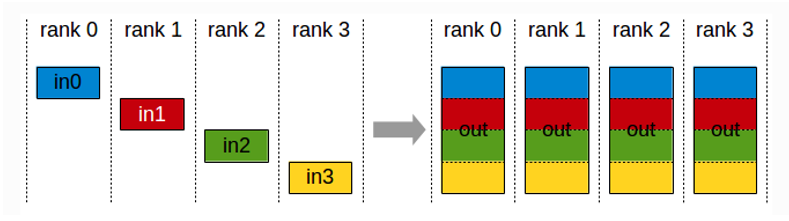
如图所示,所有的服务器都将自己收到的数据块拼接在一起(都做聚集的操作),那么就是全聚集(AllGather)。
Reduce(规约):对所有服务器上的数据做一个规约操作(如最大值、求和),再将数据写入根服务器
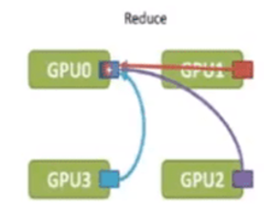
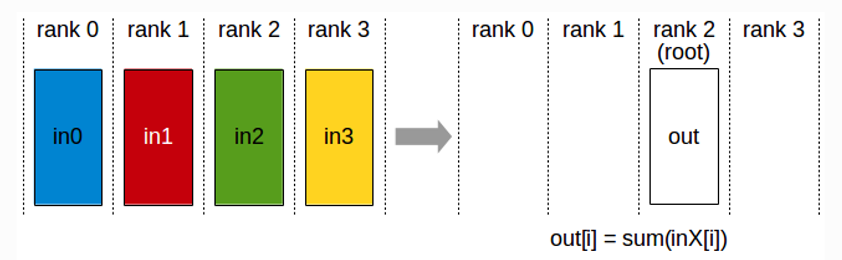
如图所示,当所有服务器都做广播或散射的时候,我们作为接收方的服务器收到各服务器发来的数据,我们将这些收到的数据进行某种规约的操作(常见如求和,求最大值)后再存入自己服务器内存中,那么这就叫规约(Reduce)
AllReduce(全规约):对所有服务器上的数据做一个规约操作(如最大值、求和),再将数据写入根服务器
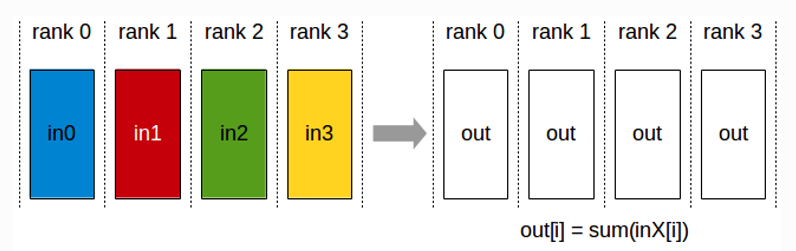
如图所示,同样每一个服务器都完成上述的规约操作,那么就是全规约(Allreduce)。这也就是分布式训练最基础的框架,将所有的数据通过规约操作集成到各个服务器中,各个服务器也就获得了完全一致的、包含原本所有服务器上计算参数的规约数据。
ReduceScatter(散射规约):服务器将自己的数据分为同等大小的数据块,每个服务器将根据index得到的数据做一个规约操作即,即先做Scatter再做Reduce。
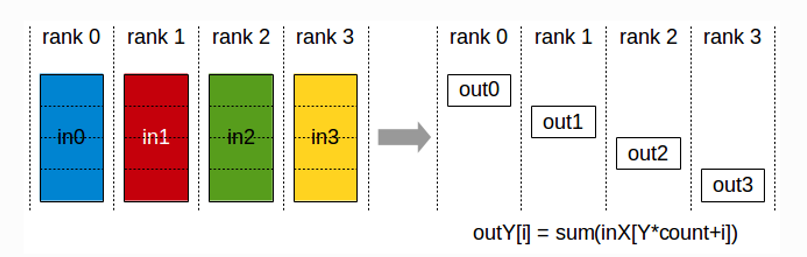
概念中,我们也常常遇到散射规约(ReduceScatter)这样的名词,简单来讲,就是先做散射(Scatter),将服务器中数据切分成同等大小的数据块,再按照序列(Rank Index),每一个服务器所获得的参数数据做规约(Reduce)。这就类似于全聚集,只不过我们将数据不是简单拼接到一起而是做了规约操作(求和或最大值等操作)。
理解各种硬件测的基本概念以后,我们对于分布式训练也应该有有一些理解了,即是分布式通过切分训练数据,让每一台服务器计算他所属的min-batch数据,再通过上述的reduce等操作进行同步,从而使得每个服务器上的参数数据都是相同的。
分布式通信算法
Parameter Server(PS)算法:根服务器将数据分成N份分到各个服务器上(Scatter),每个服务器负责自己的那一份mini-batch的训练,得到梯度参数grad后,返回给根服务器上做累积(Reduce),得到更新的权重参数后,再广播给各个卡(broadcast)。
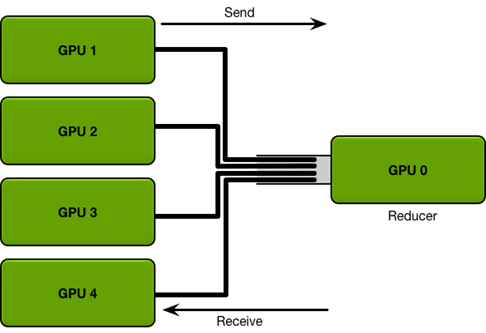
这是最初的分布式通信框架,也是在几卡的较小规模的训练时,一种常用的方法,但是显而易见的当规模变大模型上则会出现严重问题:
- 每一轮的训练迭代都需要所有卡都将数据同步完做一次Reduce才算结束,并行的卡很多的时候,木桶效应就会很严重,一旦有一张卡速度较慢会拖慢整个集群的速度,计算效率低。
- Reducer服务器任务过重,成为瓶颈,所有的节点需要和Reducer进行数据、梯度和参数的通信,当模型较大或者数据较大的时候,通信开销很大,根节点收到巨量的数据,从而形成瓶颈。
Halving and doubling(HD)算法:服务器间两两通信,每步服务器都可以获得对方所有的数据,从而不断进行,使得所有服务器全部数据。

这种算法规避了单节点瓶颈的问题,同时每个节点都将它的发送、接受带宽都运用起来,是目前极大大规模通信常用的方式,但是它也有着它的问题,即是在最后步数中会有大量数据传递,使得速度变慢。
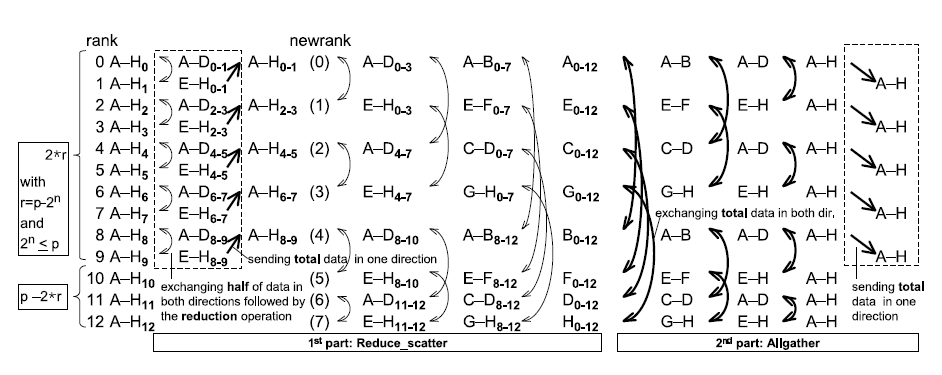
如果服务器数为非二次幂的情况下,如下图13台服务器,多出的5台会在之前与之后做单向全部数据的通信,其余服务器按照二次幂HD的方式进行通信,详情请参考Rabenseifner R.的Optimization of Collective Reduction Operations论文。但是在实用场景下,最后是将HD计算后含有所有参数数据的最大块的数据直接粗暴地向多出来的那几台服务器发送,导致这步的通信时间占比极大。
Ring算法:以环形相连,每张卡都有左手卡和右手卡,一个负责接收,一个负责发送,循环完成梯度累积,再循环做参数同步。分为Scatter Reduce和All Gather两个环节。
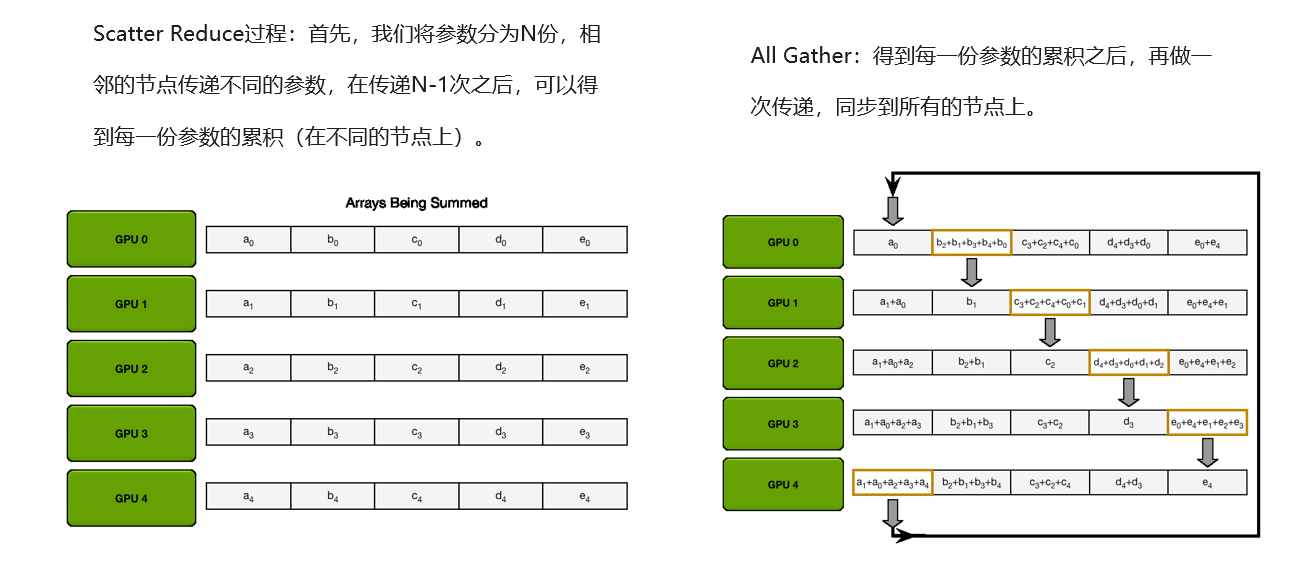
更为详细的图解
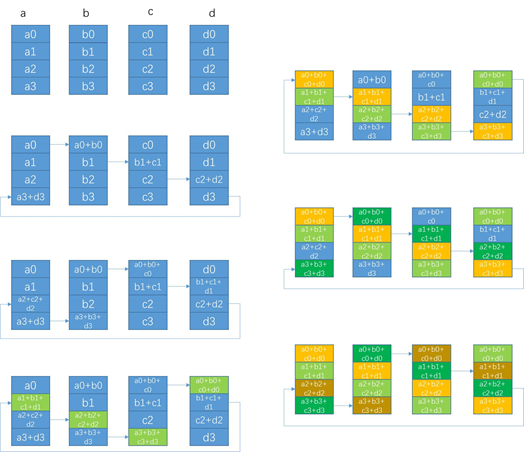
Ring算法在中等规模的运算中非常有优势,较小的传输数据量,无瓶颈,带宽完全利用起来。
缺点则是在大型规模集群运算中,巨大的服务器内数据,极长的Ring环,Ring的这种切分数据块的方式就不再占优势。
参考:
- http://research.baidu.com/bringing-hpc-techniques-deep-learning/
- https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/collectives.html
- https://zhuanlan.zhihu.com/p/79030485
- Rabenseifner R. (2004) Optimization of Collective Reduction Operations. In: Bubak M., van Albada G.D., Sloot P.M.A., Dongarra J. (eds) Computational Science - ICCS 2004. ICCS 2004. Lecture Notes in Computer Science, vol 3036. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-24685-5_1
点击关注,第一时间了解华为云新鲜技术~










 京公网安备 11010802041100号
京公网安备 11010802041100号