是一种通过网络实现文件在多台主机上进行分布式存储的文件系统。
Hbase生态系统
Hbase的数据模型相关概念
数据坐标的含义
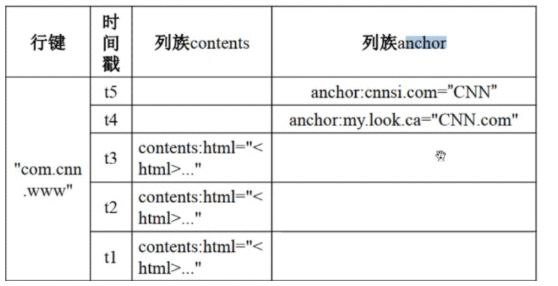
概念视图和物理视图
从概念视图看:Hbase由许多行组成,但是在物理视图上,它采用了基于列的存储方式
Hbase的三层结构
NoSQL数据库的含义与特点
含义:是对非关系型数据库的统称
特点:
关系数据库在WEB 2.0时代的局限 与WEB 2.0不适用关系型数据库的原因
云数据库的概念:部署和虚拟化在云计算环境中的数据库(简答)
云数据库的特性:(选择题)
MapReduce基本概念与计算向数据靠拢
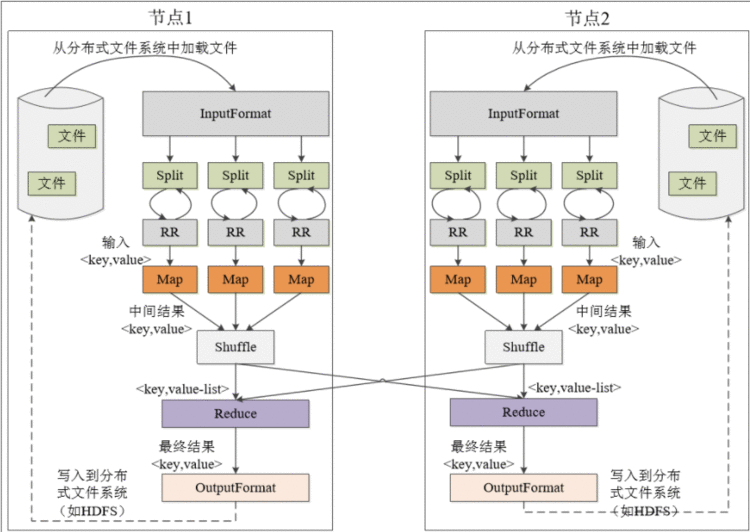
MapReduce工作流程与各个执行阶段工作
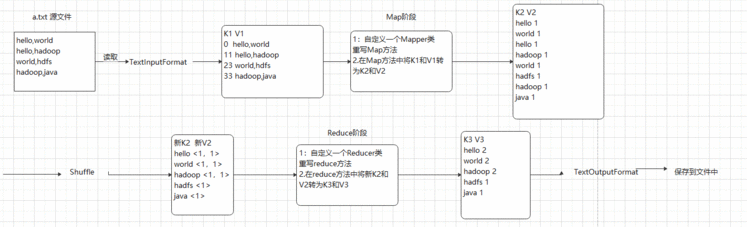
MapReduce的WORKCOUNT执行实例计算过程
参考视频
MapReduce实现关系运算
主要了解自然连接
Spark与Hadoop对比,Spark高性能的原因
大数据处理的三种类型与其适用的Spark技术栈(选择题)
RDD的设计与运行原理
大数据基本复习








 京公网安备 11010802041100号
京公网安备 11010802041100号