作者:mr.sun | 来源:互联网 | 2023-01-20 11:40
摘要
在实际集群上搭建 Hadoop 2.6.4 分布式集群环境。
集群准备
有五台机器,通过已经更改机器名称为master,slaver1,slaver2,slaver3,slaver4,并设置了面密码ssh登录。可以参考这里 2016-02/128149.htm
| 机器名称 | ip |
|---|
| master |
192.168.122.1 |
| slaver1 |
192.168.122.2 |
| slaver2 |
192.168.122.3 |
| slaver3 |
192.168.122.4 |
| slaver4 |
192.168.122.5 |
安装JDK
CentOS7 默认是openJDK
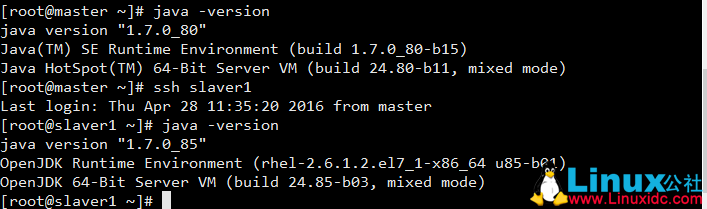
卸载CentOS 7 下的openJDK,安装Sun JDK1.7
查看openJDK安装路径
rpm -qa | grep Java
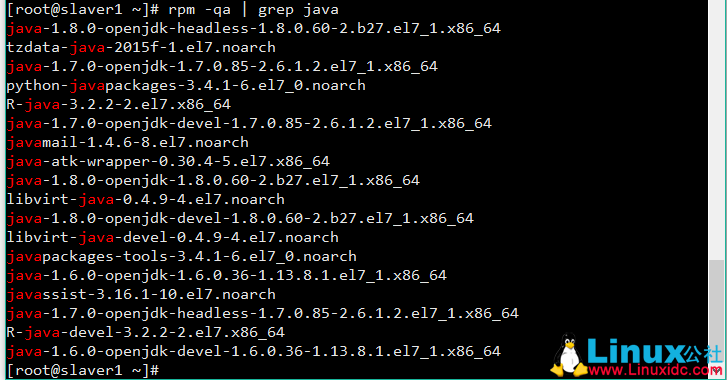
卸载openJDK
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.85-2.6.1.2.el7_1.x86_64
rpm -e --nodeps java-1.8.0-openjdk-devel-1.8.0.60-2.b27.el7_1.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.36-1.13.8.1.el7_1.x86_64
rpm -e --nodeps java-1.6.0-openjdk-devel-1.6.0.36-1.13.8.1.el7_1.x86_64
安装Sun JDK1.7
从官网下载 jdk-7u80-linux-x64.rpm,上传到 master

安装 Sun JDK1.7
rpm -ivh jdk-7u80-linux-x64.rpm
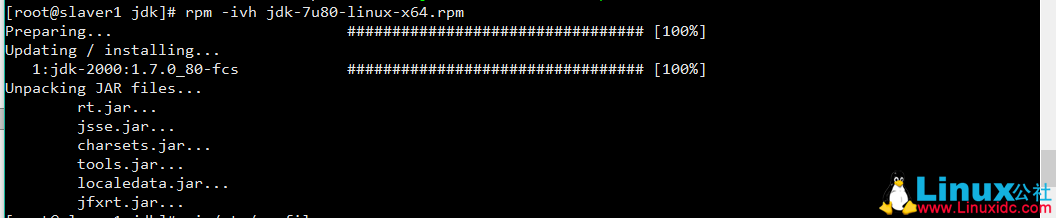
修改环境变量
在 /etc/profile里添加
export JAVA_HOME=/usr/java/jdk1.7.0_80
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin


source 生效

检验安装

安装 Hadoop 2.6.4
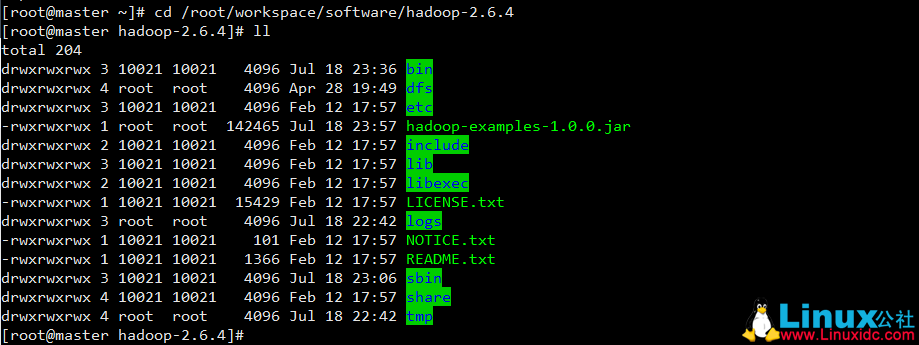
下载 ,解压
从官网下载 hadoop 2.6.4 , 并解压在 master 上
解压路径自己选择,我这里是解压在
/root/workspace/software/hadoop-2.6.4
Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程 2017-06/144926.htm
Hadoop2.3-HA高可用集群环境搭建 2017-03/142155.htm
Hadoop项目之基于CentOS7的Cloudera 5.10.1(CDH)的安装部署 2017-04/143095.htm
Hadoop2.7.2集群搭建详解(高可用) 2017-03/142052.htm
使用Ambari来部署Hadoop集群(搭建内网HDP源) 2017-03/142136.htm
Ubuntu 14.04下Hadoop集群安装 2017-02/140783.htm
CentOS 6.9下Hadoop伪分布式环境搭建 2017-06/144884.htm
添加环境变量
在 /etc/profile里添加
export HADOOP_HOME=/root/workspace/software/hadoop-2.6.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
修改 Hadoop 配置文件
hadoop-env.sh
在 hadoop 解压路径下面,/etc/hadoop/hadoop-env.sh 增加下面两行
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_PREFIX=/root/workspace/software/hadoop-2.6.4
core-site.xml
在 hadoop 解压路径下面,/etc/hadoop/core-site.xml增加下面内容
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000/value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/root/workspace/software/hadoop-2.6.4/tmpvalue>
property>
configuration>
hdfs-site.xml
在 hadoop 解压路径下面,/etc/hadoop/hdfs-site.xml 增加下面内容
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
configuration>
这里设置成3,表示数据有3个副本。
mapred-site.xml
在 hadoop 解压路径下面,/etc/hadoop/mapred-site.xml 增加下面内容
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
yarn-env.sh
在 hadoop 解压路径下面,/etc/hadoop/yarn-env.sh 增加下面,增加 Java-HOME 配置
export JAVA_HOME=/usr/java/jdk1.7.0_80
yarn-site.xml
在 hadoop 解压路径下面,/etc/hadoop/yarn-site.xml 增加下面内容
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<description>The address of the applications manager interface in the RM.description>
<name>Yarn.resourcemanager.addressname>
<value>master:18040value>
property>
<property>
<description>The address of the scheduler interface.description>
<name>Yarn.resourcemanager.scheduler.addressname>
<value>master:18030value>
property>
<property>
<description>The address of the RM web application.description>
<name>Yarn.resourcemanager.webapp.addressname>
<value>master:18088value>
property>
<property>
<description>The address of the resource tracker interface.description>
<name>Yarn.resourcemanager.resource-tracker.addressname>
<value>master:8025value>
property>
configuration>
这里添加的一些端口号,方便从远程通过浏览器查看集群情况,推荐按照这样添加。
slaves
在 hadoop 解压路径下面,/etc/hadoop/slaves 增加下面内容
master
slaver1
slaver2
slaver3
slaver4
更多详情见请继续阅读下一页的精彩内容: 2017-06/144932p2.htm




![Ubuntu 9.04中安装谷歌Chromium浏览器及使用体验[图文]](https://img1.php1.cn/3cd4a/24bf4/61b/c175cc0fe1277527.jpeg)




 京公网安备 11010802041100号
京公网安备 11010802041100号