作者:如果你在的时候的世界_266 | 来源:互联网 | 2023-02-06 23:41
目录1引言2现系统存在的问题2.1性能问题2.2团队并行开发问题2.3学习成本问题2.4容灾问题3新的系统架构4问题解决4.1性能问题解决4.2团队开发问题解决
目录
1 引言
2 现系统存在的问题
2.1 性能问题
2.2 团队并行开发问题
2.3 学习成本问题
2.4 容灾问题
3 新的系统架构
4 问题解决
4.1 性能问题解决
4.2 团队开发问题解决
4.3 学习成本问题改善
4.4 容灾问题改善
5 实现分析
5.1 Camstar/.Net分离
5.2 合理设计缓存
5.3 异步重发
6 开发实例
7 总结
7.1 加入缓存的优点
7.2 加入缓存的缺点
7.3 未来研究方向
1 引言
我做Camstar产品的开发快俩年了,由于一直是在项目现场工作,对Camstar的开发也有一定的经验和理解。对这个产品的开发,我是一直在吐槽:开发不方便,问题又多,技术支持困难等。然而真正思考一下,这些问题其实不是Camstar这个产品不友好,不高大上,而是将这个产品具体实施到项目上的时候,整体开发的设计不合理。
从技术角度去看Camstar这个产品,从他的designer设计,到.Net代码,到Portal页面设计,都是很先进的,其中的很多技术到目前都是频繁运用的,更不用说Camstar这个产品已经有着20多年的历史了。然而一个完整的系统,其实是复合木桶定律的,一个水桶能装多少水取决于它最短的那块木板。如果项目开发还是本着“开箱即用”的原则照搬照套,从技术角度看,这是不合理的。
将一个MES系统比喻成一个人,那么Camstar就是这个人的大脑,头部。Camstar以外的技术就是这个人的其他身体器官。目前大多数项目是随随便便给这个“人”装了一个“身体”,打着产品的“开箱即用”口号,产生了一个大头娃娃的畸形人。我的博文主要讨论如何将基于Camstar的MES系统打造成一个“健壮的人”,本篇主要讨论在Camstar架构中加入缓存管理以及这样做的理由。
2 现系统存在的问题
发现问题才能解决问题,从开发的角度和项目角度,我主要总结出以下几点可以通过缓存管理解决改善的问题。
2.1 性能问题
引入缓存,大家首先想到的应该是可以提高性能。MES系统的用户数量级不会很高,通常情况下是不会触碰到系统性能瓶颈。然而性能问题还是有的。
- Camstar的标准功能就可能遇到性能问题。比如物料消耗,由于Camstar对于每一个物料都可以做到严格把控,而物料和物料之间又可能存在递归嵌套。因此一个物料消耗较多的产品,在做物料消耗的时候,需要的系统资源开销是非常大的。如图2-1所示。
(由于知识产权等问题,博客中我不会贴出具体的架构图,设计图等,最多是我自己画的简化版,后面各种图同理,不再解释)
图2-1
- 在Camstar中客制化各种功能模块容易出现性能问题。在实际项目中,会客制化各种功能模块,其中可能会有很多压根不属于MES的功能模块。针对这些功能模块,是很难或者完全不能复用Camstar的标准功能,纯粹是将这些功能强塞进MES中。此时Camstar扮演的角色就只是一个开发平台,而不是标准产品。用Camstar开发颇有一种拿着大炮打蚊子的感觉。
2.2 团队并行开发问题
Camstar实际开发简单来说可以分三步:
对于一些依赖关系较重的功能模块,通常会分派给同一个开发人员做。假如这个功能模块要做100人天,老板想缩减项目周期,安排两个人做,能缩成50天吗?答案是不能的。因为Camstar在实际开发中基本上是面向实现编程的,两个人做同一个东西,俩人的代码依赖会非常严重,一个人代码有修改,另一个人基本上也要改,并且这个改动非常麻烦:假如A程序员修改了某个个建模,某块逻辑。那么他需要将本次修改的差异导出,包括MDB差异和C#代码,B程序员将这些修改内容导入到自己的开发环境,导入成功后,才能继续开发。如果不这样做的话,AB两个程序员在分别开发完自己的功能后,代码是很难整合的。
- 使用Designer建模;
- PortalStudio设计页面;
- 使用Visual Studio写C#代码的业务算法。
2.3 学习成本问题
你问一个程序员,你会JAVA,C++,Redis,Go等吗?通常情况下就算不会也了解,不了解也听过。然而你问别人,你会Camstar开发吗?相信除了圈内人员,其他程序员基都不懂。因为这实际上是产品,而不是什么通用技术。但是矛盾的是,Camstar在做项目的时候,就像是一个技术,你不会就没法做。更坑的是这种技术的学习难度是很大的,学习周期和学习成本,是很多小公司完全承受不住的。
2.4 容灾问题
目前我所知的Camstar项目的正式运行环境,通常和开发人员的虚拟机环境没有太大区别(主要是物理机和虚拟机的区别),真的是完美实践了照搬照套开箱即用。实际上这种环境的容灾性是极差的(可以说完全没有)。系统宕掉后,无论原因什么,代码bug问题,或是网络等问题,都会直接影响产线生产,可能导致产线停线。这在目前分布式系统技术如此成熟的情况下,是很不合理的。
3 新的系统架构
以上问题,可以通过加入缓存层得到解决或者改善。在加入缓存层之前,Camtar系统简图如3-1所示。
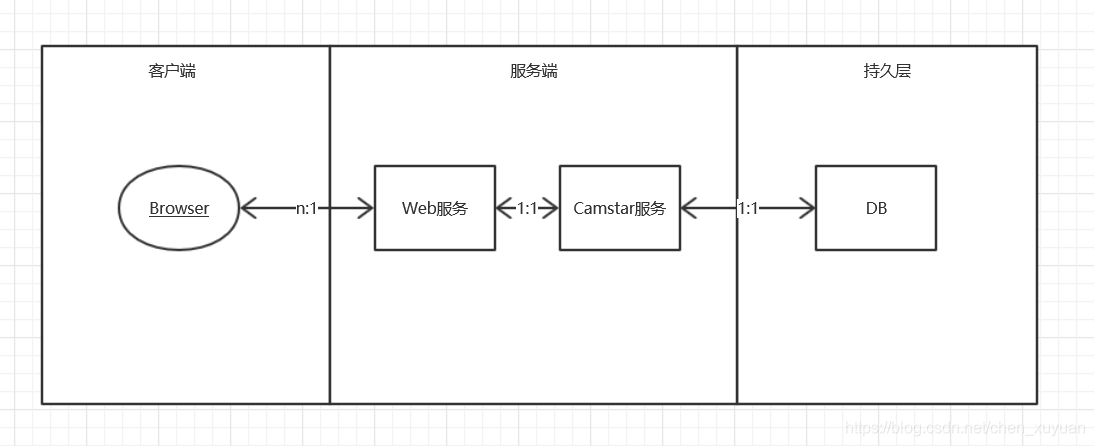
图3-1
系统主要包括四层,客户端(browser)、Web服务、Camstar服务和持久层(DB)。
一个简单的流程如图3-2所示。
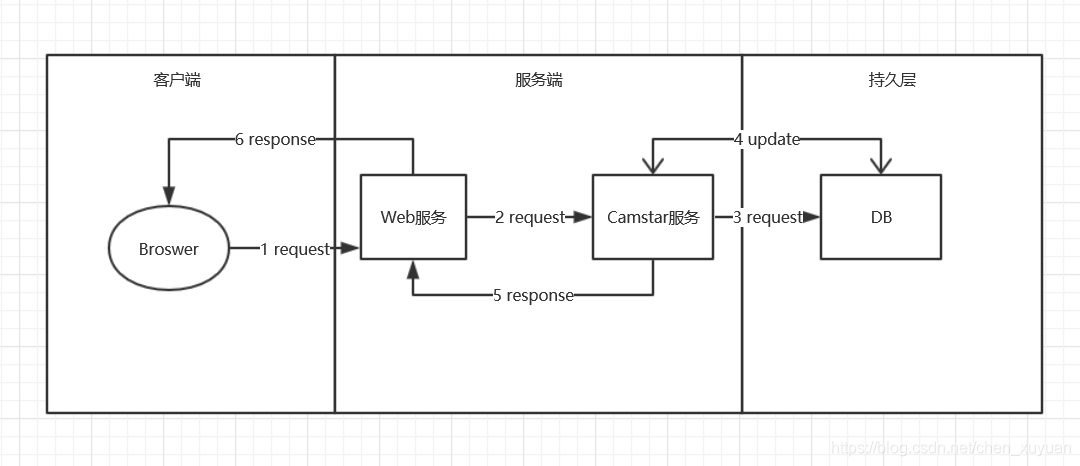
图3-2
客户端通过浏览器向Web服务器请求,Web服务器接收到请求后,调用部署在同一物理机上的Camstar服务接口,将请求信息发给Camstar服务,Camstar服务接收到请求后,从数据库加载需要的资源,并处理请求。处理完后,将处理完的数据重新写入数据库,并将处理结果返回。
现在在Web服务之后加入缓存层,新的系统架构简图3-3。
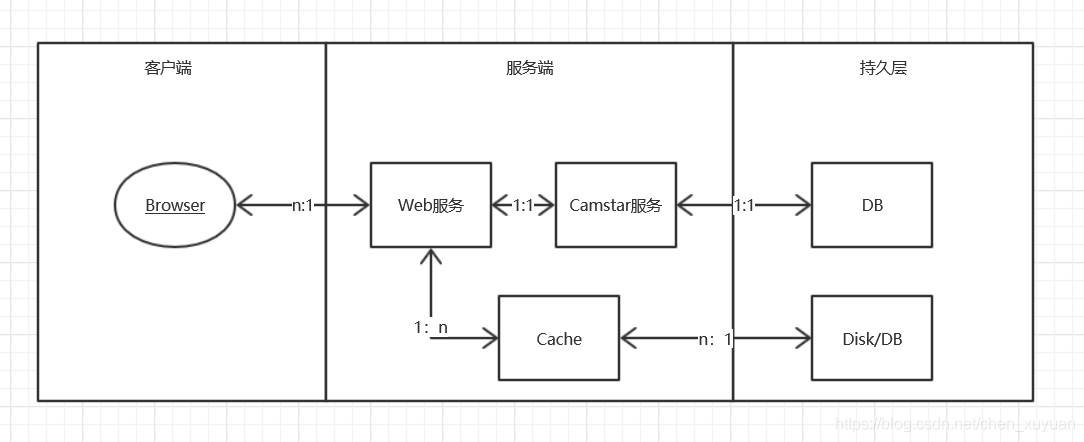
图3-3
加入缓存层后,请求可能就优先访问缓存,如果缓存命中,则直接返回。下面详细分析如何通过缓存解决前文提到的问题。
4 问题解决
4.1 性能问题解决
在Web服务和Camstar服务之间加入缓存,意味着客制化开发的非Camstar标准功能都可以通过合理的缓存设计达到性能优化的目的。对于一致性要求不高的数据,可以通过设置较高的过期时间等方式,提高缓存命中率,降低对Camstar服务层的穿透率,直接降低了Camstar服务的压力,同时也间接地降低了数据库的压力。
对于Camstar标准功能,通常项目上是不会完全照搬,而是会在Web服务层或大或小做一定的客制化,那就可以按照非标准功能的优化方式进行优化。特别的,如果是完全“开箱即用”的功能,那么缓存的优化是无效的,因为本文设计的缓存层并非做在了Camstar和DB之间。
当然,如果在Camstar服务和DB之间再做一层缓存,做多级缓存管理,那么确实可以做到完全优化,但是这样做的成本太大。并且,由于已经对除此以外的功能做了缓存优化,穿透到Camstar服务和DB的请求减小,间接地优化了需要消耗较多系统资源的功能。
比如客户端同时发起100个请求,其中90%做了缓存优化,且缓存命中率为50%,在不考虑缓存过期地情况下,实际穿透到Camstar服务和DB的请求只有45。那么虽然未对标准功能进行缓存优化,也间接地提高了一倍的吞吐量。
4.2 团队开发问题解决
假设页面A,B同时由A,B两名程序员开发,都依赖于同一个建模CDO。目前的做法是让A或B单独在Designer建模,设计完后将差异导出给另一个同事。并且后续并行工作的时候不能轻易再修改Designer建模。如果一人需要修改,且会影响另一个人,那么需要重新沟通。实际上我们需要的是一个类似于锁的东西,保证同一个CDO在同一时间只有一个人修改。
如果A,B俩名程序员在编程的时候都先依赖于缓存编程,则可以缓解这个问题,例如典型的读取缓存代码如下:
if(data == null)
{//读取缓存data = GetDataFromCache();//双检,如果读取缓存还是为空,则穿透到数据库,或者为了防止雪崩缓存一个空对象if(cache == null){//穿透到数据库,代码data = GetDataByCamstarService();//更新缓存SetCache(data);}
}
return data;
AB程序员都可以先不具体实现穿透到Camstar服务的代码,先将所有请求统一交给缓存处理,最后再统一沟通完善Designer的CDO,再补充具体的穿透代码。这个过程中,可以规定只由某一个人单独在Designer开发。
4.3 学习成本问题改善
基于4.2的理论基础和例子,假如A,B两名程序员对Camstar开发经验A>B,那么可以让B程序员完全依赖缓存编程,不实现穿透到Camstar服务的代码。让A程序员负责实现穿透代码和Designer建模。那么,就可以做到Camstar和.Net分离,无需所有程序员都花费较多精力学习Camstar。假如A,B的Camstar开发经验都不足,那么还可以引入一个C成员。
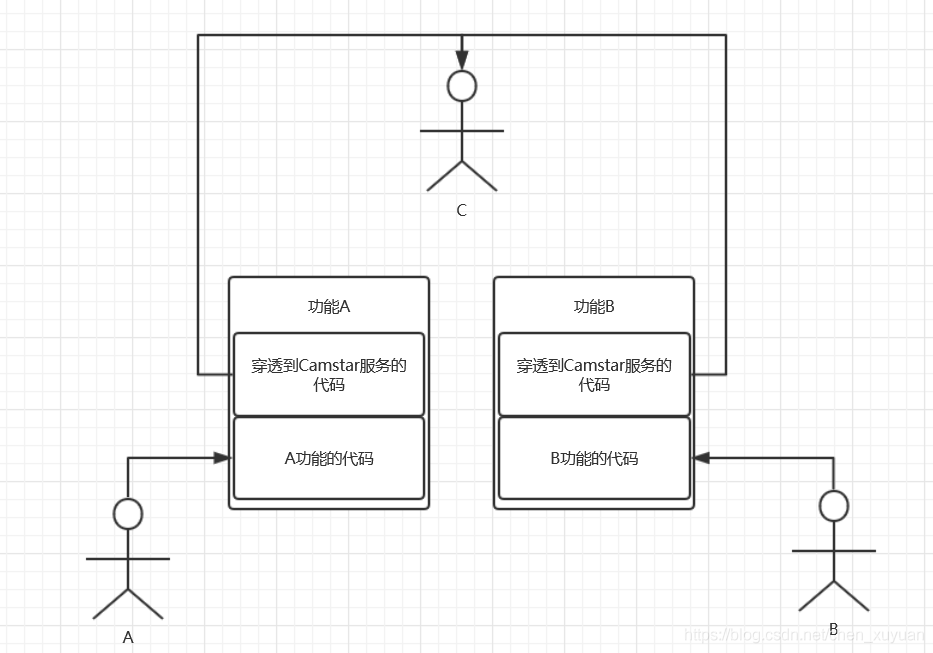
图4-2
4.4 容灾问题改善
Camstar系统挂掉通常是Camstar服务挂掉,而不是web服务器的问题。但是由于每一个用户的请求都会传到Camstar服务,因此camstar服务挂掉就意味着整个系统挂掉。加入缓存后,降低了Camstar服务的压力,减小了Camstar服务挂掉的几率。并且如果用户的请求能命中缓存,那么对于一些不是很严重的问题,例如网络波动,Camstar服务临时更新等,用户可能感觉受不到服务器的异常。
将缓存部署到不同的物理机上,假如主服务器出现异常,缓存可以记录请求,待主服务器恢复正常的时候异步的处理。不过这种做法具有较大的风险性,可能导致雪崩。缓存对于容灾问题的改善程度有限,更合理的做法应该是采用分布式系统和数据库备份等方式。
5 实现分析
针对之前的问题,本节从技术角度分析,举例出几个具体的使用缓存的技术思路。实现分析和开发实例都简单带过,在其他文章中详细讨论。
5.1 Camstar/.Net分离
Web服务层的代码使用模板方法模式设计,抽象基类定义访问缓存的抽象方法,而使用钩子方法(空方法)实现定义穿透到Camstar服务的代码。这样,可以让普通C#代码和Camstar代码分离。让精通Camstar的人负责实现Camstar代码,精通.Net的人负责实现其他代码。解决团队开发问题和学习成本问题。伪代码如下:
abstract class Demo
{public void TemplateMethod(){if(Hook())GetDataByCache(); elseGetDataByCamstar();}protected abstract void GetDataByCache();protected virtual void GetDataByCamstar(){//提供空实现}//子类如果实现了穿透DB的代码,则可以将此钩子方法返回trueprotected virtual bool Hook(){return false;}
}
5.2 合理设计缓存
合理设计缓存的过期时间,过期策略等,提高缓存的命中率,对于热点数据,还可以考虑做多级缓存。解决系统性能问题。
5.3 异步重发
将缓存部署到单独的物理服务器上,并设置心跳检测等方式监控服务器的运行情况,如果发现服务器异常,可以将请求暂存在缓存服务器,当服务器恢复正常的时候重新发送穿透到Camstar服务的请求。
6 开发实例
本篇文章主要以理论为主,实际开发实例涉及到具体代码了,放在这篇不合适,所以我打算新开一篇,实际开发者有兴趣可以看。Camstar 开发:缓存的设计与实现。
7 总结
加入缓存虽然可以解决改善现有的一些问题,但同时也会带来新的问题。总结下缓存加入的优缺点。(前文主要都是优点,所以此处主要描述缺点)
7.1 加入缓存的优点
1)解决改善了本文提出的几个核心问题。
2)提高了系统的可扩展性,系统在一定程度上面向了抽象层(缓存)编程,使得系统的扩展更加方便。
3)降低了系统的耦合性,每个人的代码都可以独立运行。
7.2 加入缓存的缺点
1)加入缓存可以说是个空间换取时间策略,增加了内存压力。如果缓存不是单独部署,那么可能会占用较大的内存。特别在Redis这种开源工具在持久化的时候,最坏情况会成倍地占用内存。
2)增加了开发人员的代码量,因为和原始的开发方式相比,开发人员还得编写读写缓存的代码。
3)缓存类地引入必然会导致整个系统更庞大,维护更加困难。
4)提高了开发人员对通用技术(缓存等)的技术要求,但是另一方面降低了开发人员对Camstar的技术要求,单从目前的市场情况来看,或许这不是缺点。
7.3 未来研究方向
其实我觉得我在文章开头的比喻挺有意思,将MES系统看作一个完整的人。我们想要在系统中加入不同功能,好比想让这个人拥有不同的能力(会炒菜,会做饭,会算术等)。如果说最原始的Camstar系统是一个智商超高但是身体羸弱的人,那么我们不断使用新技术充实这个系统,就是让这个人越来越健壮。现在的技术进步那么快,成熟的中间件那么多,我们要做的工作只是整合一些先进的技术。接下来我想研究分布式系统对Camstar是否有必要,目前我只想到可以大大提高容灾,因为我对分布式系统的学习也不深,所以还得继续学习提升自己的技术。当然,对于我来说,这个过程才是有趣的。
本文请勿转载!


![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)







 京公网安备 11010802041100号
京公网安备 11010802041100号