点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

作者 | 桑基韬
整理 | 维克多
人工智能目前最大的“拦路虎”是不可信赖性,以深度学习为基础的算法,在实验室环境下可以达到甚至超过人类的水平,但在很多实际应用场景下的性能无法保证,而且存在对抗鲁棒性、解释性、公平性等问题。
4月8日,在AI TIME青年科学家——AI 2000学者专场论坛上,北京交通大学计算机科学系教授、系主任桑基韬在报告《“超”人的机器学习:非语义特征的得与失》中,从两类虚假相关性角度解释了这种现象:
机器学习其实不管是目标,还是学习方式,都是类人的,是对人的知识蒸馏。这种知识蒸馏会出现两种情况:学的不够好,称为虚假相关性-1(欠蒸馏);学的太好了,称之为虚假相关性-2(过蒸馏)。
欠蒸馏,因为数据不完备,模型只学习到了训练数据的局部相关性,会存在分布外泛化和公平性等问题;过蒸馏是机器学习到了人难以感知/理解的模式,影响到了模型的对抗鲁棒性和解释性。
此外,桑教授还提出了将虚假相关性统一,探索非语义特征的学习和利用。以下是演讲全文,AI科技评论做了不改变原意的整理:
今天分享多媒体分析特别是计算机视觉中非语义特征的现象,分为三个部分:得、失和失而复得。报告内容受了很多工作的启发,其中有一些是我不成熟的思考,希望能和大家交流讨论。
1
得:“超”人的机器学习和非语义特征

回顾人工智能和机器学习的发展史,在围绕和人类经典任务PK的过程中,AI已经超越了人类的表现。从1997年国际象棋深蓝”以3.5:2.5战胜人类国际象棋世界冠军卡斯帕罗夫,到2021年AlphaFold蛋白质结构预测超过人类,都在表明,AI已经可以模拟分析、推理、决策等人类重要能力。

但在“超人”的能力之外,也体现了AI在对抗攻击下的脆弱性。上图第二张图片,人类加了一些噪声之后,同样一个网络却给出了两种截然不同的答案:elephant与koala。

不仅是图像分类,对于对抗攻击下的决策、表示,AI也非常脆弱。例如,通过加入一些对抗噪声,以上图片经过神经网络能得到完全一致的特征表示,也就是人视觉不同、对抗攻击后表示完全相同。目前,对抗攻击有很多作恶的地方,例如无人驾驶中攻击路标识别;刷卡机中攻击人脸识别。

回顾对抗样本的发展,在2014年,Szegedy首次提出对抗样本问题的10年前,2003年就有欺骗算法,也叫敌手模型,攻击垃圾邮件检测器。2014年提出的深度学习对抗样本,重要的特点是其强调“人类察觉不到扰动”。此后,对抗样本研究发展,呈现“猫鼠游戏”的状态,没有绝对成功的攻击,也没有绝对的防御。
2017年有两个工作值得一提,对抗样本实体化,在各个视角欺骗神经网络的现实世界3D物体;通用对抗噪声UAP,对于不同的样本添加通用的噪声,都可以让模型出错。
2019年MIT Madry团队的工作给了我们很大启发:对抗噪声本质是模型特征,对抗样本的分类器可以泛化到攻击类测试样本。具体而言,Madry通过两个实验得出两个结论:

1.对抗噪声可以作为目标类特征。如上图,是一张干净的小狗图片,通过加入“代表猫(特征)”的对抗噪声,让AI将其识别成猫。基于这些对抗攻击污染后的对抗样本训练的猫分类器在识别干净猫图像的任务中,却有不错的泛化。这就是利用对抗噪声训练的目标类分类器可以较好地泛化于真实的目标类样本。
2.非鲁棒特征对模型泛化性有贡献。把图像分成两类特征,一类是人可以理解,称为鲁棒特征,另一类是噪声,称为非鲁棒特征。当把图像非鲁棒特征去掉时,只利用这一部分特征去进行训练时候,会发现模型在样本上的准确性、泛化性是下降的。因此,可以得出结论非鲁棒特征对模型泛化性有贡献,有些信息人类不易理解但可以辅助模型推断。

除了对抗噪声能够体现人与AI算法的不同,是否关注物体的形状和纹理也是区别之一。如上图,在处理一个8*8拼图的图片时,人类很难识别出物体本来的面目;如果是4*4,我们勉强能看出边缘。因此,人在判断物体的时候,其实是需要借助形状信息。但是对于CNN模型,当形状信息缺失的时候,完全可以根据纹理进行准确的判断。
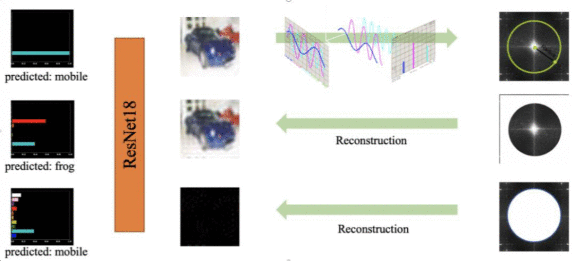
同时,该现象在频域里也有表现。如上图,高频重建的图像人眼几乎无法识别,模型却能准确预测类别。这篇论文中指出:数据包含两类信息,一类是语义信息,一类是以高频为代表的非语义信息。
在这两类信息里,人只能利用语义信息进行判断,模型同时可以利用这两部分信息。这篇论文和Madry团队论文中的观点引发了激烈的讨论:这部分信息是过拟合的噪声,还是真实任务的特征?我更倾向于后者,下面提供几个证据。
1.对抗样本的迁移性,其实就说明了非语义特征可以跨模型、跨数据集。换句话说,它不是针对模型和数据集过拟合的。
2.非哺乳动物的四色视觉,也表明一种视觉的信息对于某些物种,可能是不可见、不可感知的,但是对于其他物种是可感知的,而且是非常重要的。例如紫外光谱人不可感知,但鸟类可以看见,其中包含了鸟类求偶的真实特征。
3.AlphaFold:蛋白质折叠中的非语义特征。学者发现,折叠配置依赖于分布于整个多肽链的交互指纹,而交互指纹由于其全局分布性,结构非常复杂,人难以用规则进行定义。但其对于预测是有效的。因此,交互指纹这种非语义特征,显然对于蛋白质折叠的任务是有益的。
以上这些非语义特征的存在,也是当前很多机器学习任务超过人类的一个原因。
2
失:两类虚假相关性和可信赖机器学习
从另外角度看,这种非语义特征有哪些问题?从一种假设说起:“把机器学习看成对人的知识蒸馏”。这一假设可以用监督学习进行理解,监督学习要求“人去打标签”,然后模型会基于标签去学习从样本到标签的映射。在无监督和自监督任务中,其实也是人为去设定目标和学习机制。换句话说,机器学习其实不管是目标,还是学习方式,都是类人的,是对人的知识蒸馏。
但这种知识蒸馏有时会出现两种情况:学的不够好,称为虚假相关性-1(欠蒸馏);学的太好了,称之为虚假相关性-2(过蒸馏)。
其中,虚假的相关性是指统计机器学习基于训练数据中存在的相关性学习特征构建模型,其中某些相关性特征在系统和人使用过程中会出现错误。
这种欠蒸馏可以从机器学习过拟合的角度理解,因为数据不完备,模型学习到了训练数据的局部相关性。这会导致分布外泛化问题,训练集和测试集来自不同分布时,测试性能大幅下降,“聪明的汉斯”、“坦克都市传奇”都是分布外泛化的例子。

2017年,ICLR一篇最佳论文提出随机标签现象也可理解为欠蒸馏的体现,即随机打乱训练集样本标签,泛化gap随随机标签比例上升而增加,导致测试性能下降。这反映了深度网络甚至可以记忆训练集中的噪声信息,但这种噪声不是任务的本质特征,无法保证泛化性能。
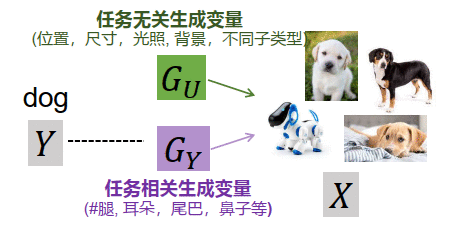
总结一下,欠蒸馏会导致模型学习到一些任务无关特征,即训练集强关联,但测试集无法泛化。我们尝试对任务无关特征给出更为严谨的定义,并分析它的性质。如上图,从数据生成的角度,从标签Y到样本X的生成过程中间引入一个变量G。G分成两部分,一部分是和任务相关的生成变量,也就是说当变量改变的时候,整个任务都会改变;另一部分是,它不会影响Y的分布,但是会影响x的呈现,例如对于生成“狗”的任务里面,模型会关注狗的位置,尺寸、光照等和任务无关的变量。这其实是对IID的放松,更符合数据集的实际分布情况。
任务无关特征除了有泛化性问题,在因果框架中,还可以看做混淆变量,同时如果这种特征带有社会属性,还可以看做偏见变量,会导致公平性问题。
前面提到过蒸馏是机器学习到了人难以感知/理解的模式,我们将其定义为非语义特征。简单来说,这种非语义特征是模型可利用的、人类难以理解的信息。值得指出的是,目前对于非语义特征尚没有统一的认识,我们正尝试结合人类视觉感知特点和信息理论建立一个严谨的、可以量化的定义。目前可以借助非语义特征的两种表现形式来理解:从内容结构角度可称为弱结构化特征,比如高频、小奇异值对应的信息都是人难以感知的;从模型知识角度即对应了Madry论文中提到的非鲁棒特征,可大致理解为攻击模型产生的对抗噪声。

上图(左)是在亚马逊众包平台上请工人对字符验证码进行识别的例子。我们在里面加入了8种程度的对抗噪声,可以看出人类和OCR识别算法的变化:最高尺度的噪声对人类没有变化,但由于扰动了非语义信息,算法性能会下降很快。
上图(右) 是加入高斯白噪声的情况。可以看到,人和算法虽然随着噪声程度的增加都有下降,但是人受影响会更大。原因可能是,当白噪声的等级增加,人类所主要依赖的语义信息就被遮盖掉了,但是模型可以同时挖掘非语义信息进行辅助判断。

过蒸馏,其实还影响到了模型的解释性,有研究发现,对抗鲁棒模型可能依赖语义特征进行推断,因此具有更好的梯度解释性。
这两种虚假相关性扩展到可赖机器学习有哪些启示?可信赖机器学习大概对应了可信计算的应用层。它有两个核心的概念:按照预期的目标执行,按照预期的方式执行。按照预期的目标要求任务理解准确,但只通过训练数据描述的任务往往不够全面、准确;以预期的方式执行,要求执行准确,即推断过程可理解、推断结果可预测。

如上图,上述两个目标和两类虚假相关性有一个大致的对应关系。基于两类虚假相关性可以将视觉信息划分为四个象限,而可信赖机器学习希望模型只利用第一象限的信息:即任务相关的语义特征。

我们提出一个可信赖机器学习框架,以最终让模型依赖任务相关的语义特征。有三步,第一步是传统的训练器,目的是在测试数据可以泛化,学到任务相关的特征,这部分特征可以满足不需要和人进行交互的系统应用场景。第二部分是解释器,目标是人可以理解,从任务相关特征进一步提取出面向语义的特征,可以同时满足和人的交互;第三部分是算法测试,目标是评估真实性能+诊断发现bug。我们注意到,把机器学习当成软件系统的话,其实缺少了软件工程里成熟的测试和调试的模块,引入测试模块,能进一步针对性地发现模型中利用的两类虚假相关特征,与训练器和解释器形成闭环,通过测试-调试共同保证机器学习算法从实验室级向工业级的可信赖应用。在这一框架下,我们对应在三个阶段探索了一些基础问题,并围绕视觉识别、多模态预训练、用户建模等应用场景开展了一些研究工作,这些工作我们整理成开源代码包供调用,并会集成到一个统一测试-诊断-调试平台上,将作为工具发布,以供对可信赖性有需求的算法设计、开发和使用人员使用。
3
失而复得:虚假相关性的统一和非语义特征学习
根据以上的讨论,围绕非语义特征,实际存在两个矛盾。一是“弃之可惜,用之不可信”。非语义特征丢掉很可惜,但拿来用又有风险。有用之处在于:模型可以利用非语义特征辅助推断,完全移除非语义特征使模型泛化性下降。风险在于:使用非语义特征的模型存在对抗鲁棒性、解释性等机器学习的可信赖问题。

第二个矛盾是:机器学习能力“超”人 ,但学习目标和方式“类”人。非语义特征包含了人类难以感知、机器可以利用的信息,而学习目标和方式是类人,比如深度神经网络受人类视觉系统启发,包括层次化网络结构、感受野逐层增加、简单细胞、复杂细胞等。
围绕“弃之可惜,用之不可信”矛盾,以泛化性和对抗鲁棒性为例,它背后代表的是两类虚假相关性之间的矛盾:泛化性的提高很大程度上来自非语义特征的利用,而在目前训练范式下,限制非语义特征会影响泛化性。
有没有可能将两类虚假相关性进行统一?我们提出一个假设,对抗鲁棒性问题不是因为模型利用了非语义特征,而是因为没有很好地利用非语义特征,非语义特征在提供有限泛化性贡献的同时,增加了被对抗攻击的风险。

我们也从频域入手,暂且将高频信息大致对应非语义特征。如上图,相比中低频,特征提取后,高频分量的类间距比较小,对最终分类的贡献也就比较弱。而实际上,在特征提取前,原始图像的高频分量中存在着相当的类判别信息。如下图,原始图像不同频率的HOG特征分布情况,右边是高频,左边是中低频。
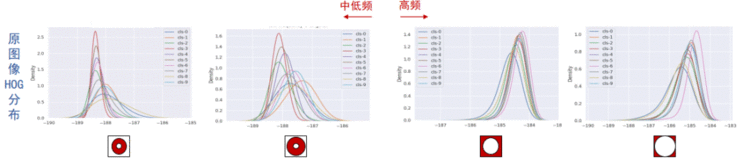
经过特征提取之后,可以明显看出:高频信息被抑制了,而中低频经过特征提取得到了增强。这告诉我们,高频信息对于模型泛化性的贡献是有限的。

但是和对抗鲁棒性有很强的关联性。如上图中间是无目标对抗攻击过程的动图,可以看出对抗攻击有一个阶段明显沿高频分量的分布方向移动,换句话说,高频分量很可能引导了对抗攻击在特征空间的行为。

这里我们有一个初步的假设,对抗攻击过程可能分为两个阶段:第一阶段,它会寻找正交于数据流形的决策边界,并跨过类决策边界;在第二个阶段对抗攻击继续向目标类中心集中。我们最近发现这个假设和两个阶段互信息的变化有很强的一致性,后续有进一步的结果,我们会专门进行介绍。从这个角度来看,高频信息代表的非语义特征,在模型训练过程中并没有得到重视,非语义特征不是天然容易被攻击,只是它没有被学习得很好,导致了对抗攻击有机可乘。

围绕“能力超人,学习类人”矛盾,对于非语义特征的学习和提取,可能要区别对待单独设计。这里以受人类视觉处理系统的层次化网络设计为例。今天的CNN设计,尝试借鉴逐层的网络结构,包括感受野逐层变化。如上图可视化的呈现,相比中低频特征,高频特征逐层差异小、感受野相对固定几乎是全局的。我们初步的实验发现,浅层、大卷积核更有利于高频特征学习。

最后,人类为什么会聚焦语义信息,而忽略非语义信息?我们“猜测”是进化的低成本目标所致。一个是学习代价小:人类的学习首先通过群体大数据积累形成结构先验,然后个体小样本迁移,从而能够举一反三。上图的实验中我们发现高频特征的学习需要消耗较多的样本,在典型的小样本学习设置下,模型无法实现良好拟合。另一个是推断代价小:完成一个任务所需要调用的神经元尽可能少,然而我们发现高频神经元总激活消耗大且不同高频神经元激活的差异大造成利用率低。高频特征处理的这些特点都和生物神经系统的低成本进化方向是相违背的。

我们知道AlphaGo的能量消耗相当于一个人的5万倍,如果我们抛开对于低成本的约束,对于非语义特征的学习和提取似乎也应该突破“类人”的约束。这启发我们根据所处理信息的特点,重新设计模型结构;参考其他生物神经系统,启发设计模型结构等。如果我们认可非语义特征的存在,机器学习关于数据集、模型结构、损失函数、优化方法等的先验假设是否都存在着新的理解和可能?同时,如何平衡类人和超人以避免非语义特征在现阶段带来的不可信赖风险?如果是需要人理解/交互的任务,我们希望是“类人”方式,定义好边界;如果是需要新知识发现的任务,就可以允许“超人”,大胆探索人所不能。当然,也有可能,对于非语义特征,只是目前不可理解,希望通过更多人投入相关研究,我们理解了背后的原理和机制后,不仅能可靠地利用这些信息设计机器学习算法和系统,更能拓展和提高我们自己的认知。
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了600多位海内外讲者,举办了逾300场活动,超150万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看更多内容





![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)






 京公网安备 11010802041100号
京公网安备 11010802041100号